本文主要是介绍Neo4j 之安装和 CQL 基本命令学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
正常使用结构化的查询语言 SQL(Structured Query Language)较多一些,但是像 Neo4j 这种非结构化的图形数据库来说,就不得不学习下 CQL(Cypher Query Language)语言了。如果你之前学过 《离散数学》或《图论》,对语法理解起来应该要容易一些。
Neo4j 安装
jdk安装
我用的 Neo4j 是 neo4j-community-3.5.5-windows.zip ,所以下载个 jdk11 安装就可以了。官网的下载比较卡,网盘没失效的话可以用这个链接。
jdk-11.0.6_windows-x64_bin.exe
链接:https://pan.baidu.com/s/1uwkT0SDdKlzN8C2kNRBKhA?pwd=xq4w
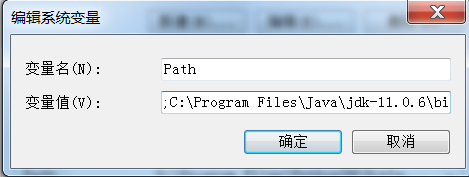
然后就是点击安装就可以了,安装好以后记得设置环境变量(根据你自己的安装路径设置)。
neo4j安装
链接:https://pan.baidu.com/s/11aLfX2FlD7Accra5FyUmOw?pwd=dt8q
neo4j 的安装也很简单,解压后,放到某个目录(目录不要有特殊字符),然后设置环境变量就可以,我自己是直接放到 C 盘下的,然后设置环境变量就可以了。

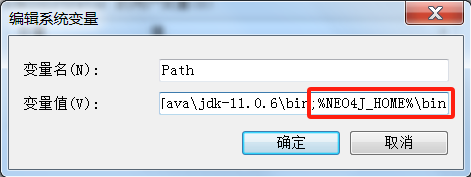
命令行脚本启动以后,打开访问下面标记处远程链接就可以了
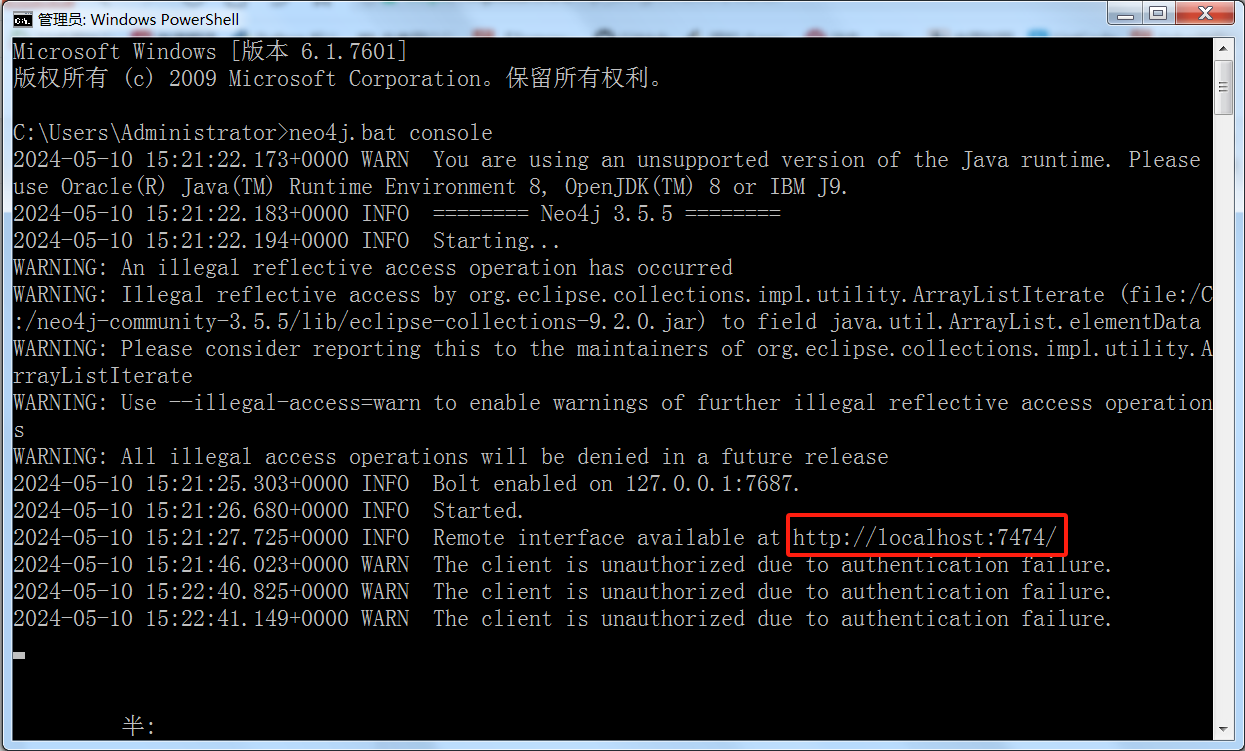
默认账号和密码都是 neo4j ,初次登录要修改密码,这个就不多说了。
CQL基本命令
常用命令关键词不多,主要是下面这些。
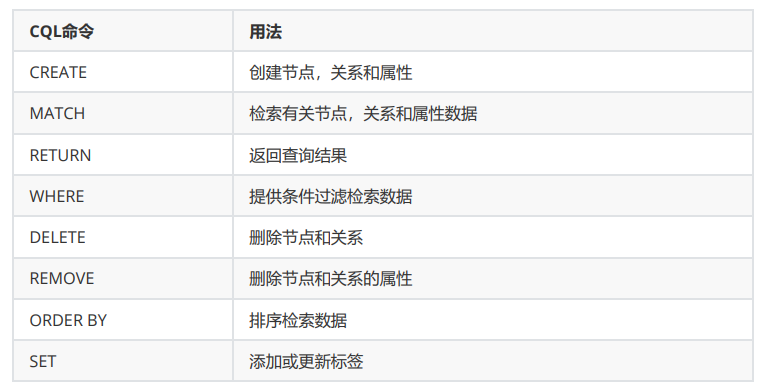
节点操作
创建节点
创建节点的基本语法如下:
CREATE (node_name:label_type {property:value});
CREATE: 创建新节点。node_name: 节点的名称。label_type: 节点所属的标签类型。property:value: 节点属性和值。
我们来个例子试试,比如创建一个人员节点。当然, RETURN 语句不是必须的,如果你不需要查看创建的结果,就不需要执行 RETURN 语句返回。
CREATE (person:Person {name: "John", age: 30 })
RETURN person;
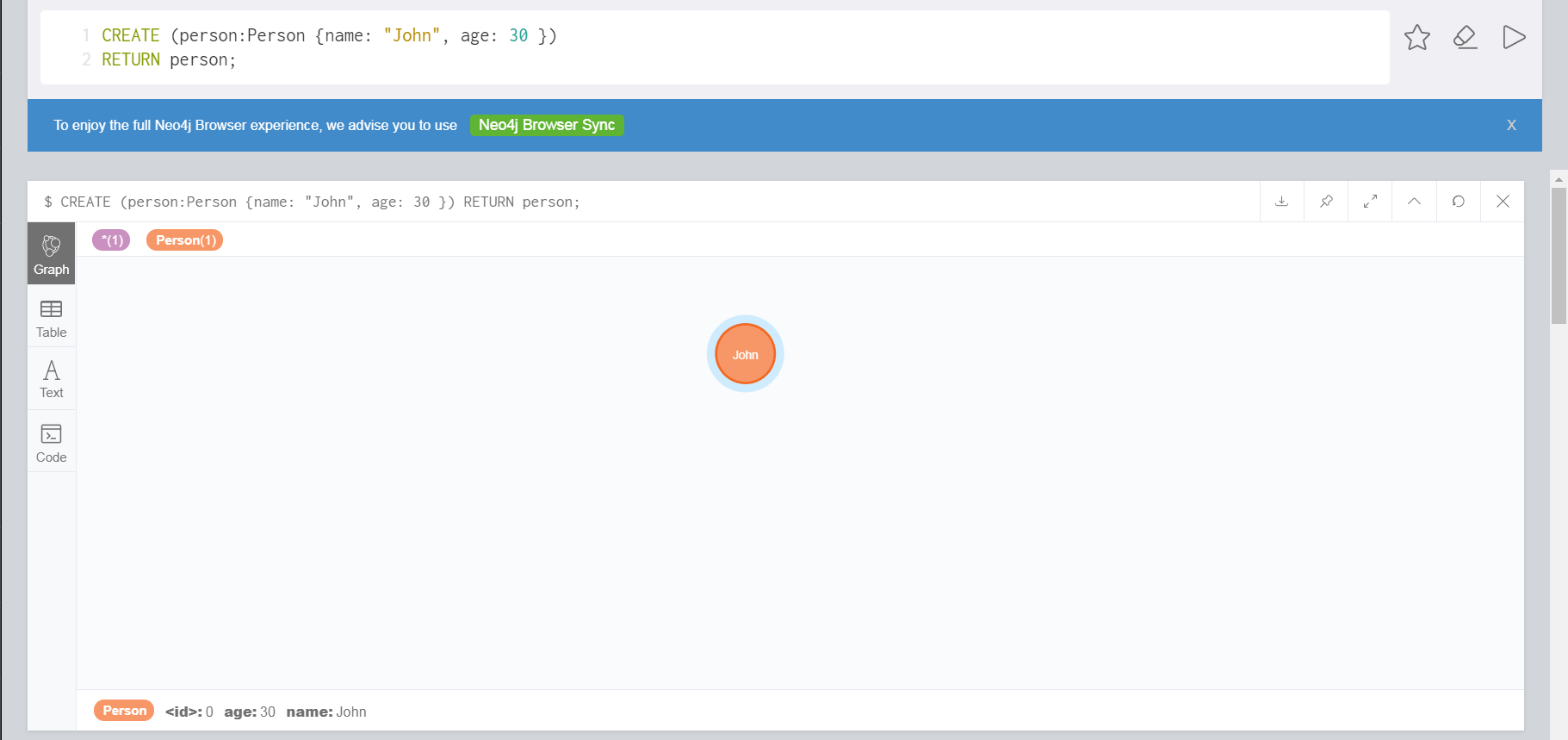
对于语句中的 person,如果你后续没有针对它的引用,其实也是可以不用写的,当然写上之后要更清晰一些。像下面的语句,同样可以成功创建节点。
CREATE (:Person {name: "Looking", age: 30 })
批量创建多个节点
CREATE (person1:Person {name: "John", age: 30 }), (person2:Person { name:"Sandra", age: 25 });查询节点
查询节点的基本语法如下:
MATCH (node_name:label_type)
WHERE node_name.property = value
RETURN node_name;
比如查询所有 Person 的节点:
MATCH (person: Person) return person;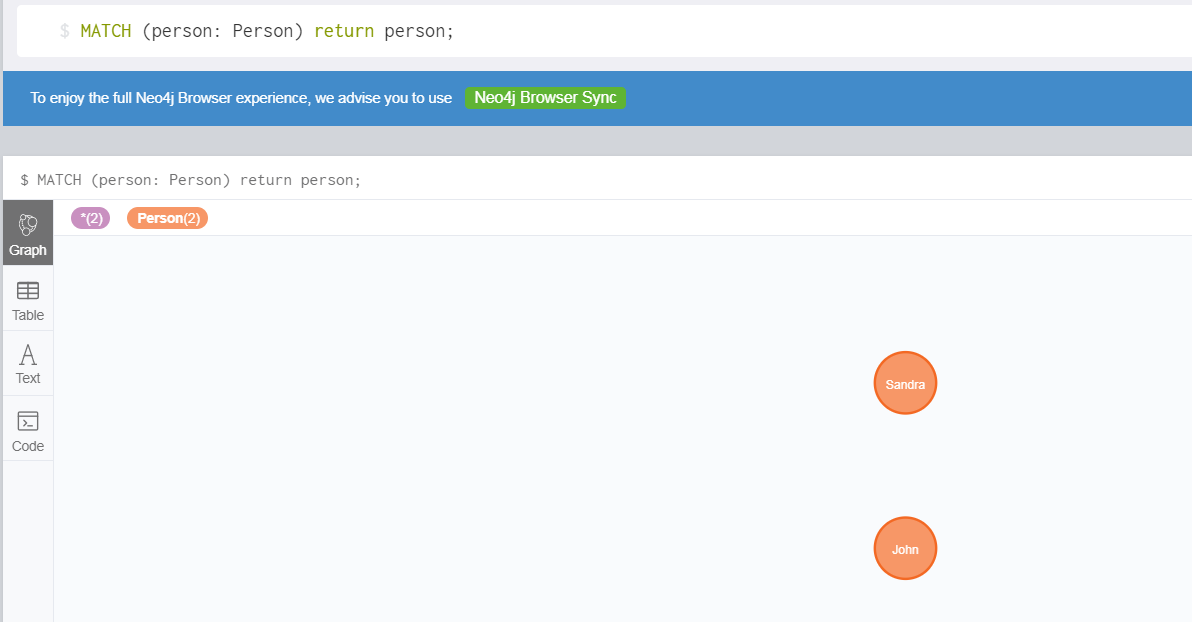
也可以指定属性查询
MATCH (person: Person{name:"John"}) return person;或者使用 WHERE 语句指定查询条件
MATCH (person: Person)
WHERE person.name="John"
RETURN person;修改节点
修改节点主要用到 SET 关键字,这块和 SQL 的用法差不多,语法如下:
MATCH (node_name:label_type {property:value}) SET node_name.new_property = new_value;
比如修改 Person 节点中名为 John 的 age 为 100 。
MATCH (person: Person{name:"John"}) SET person.age=100;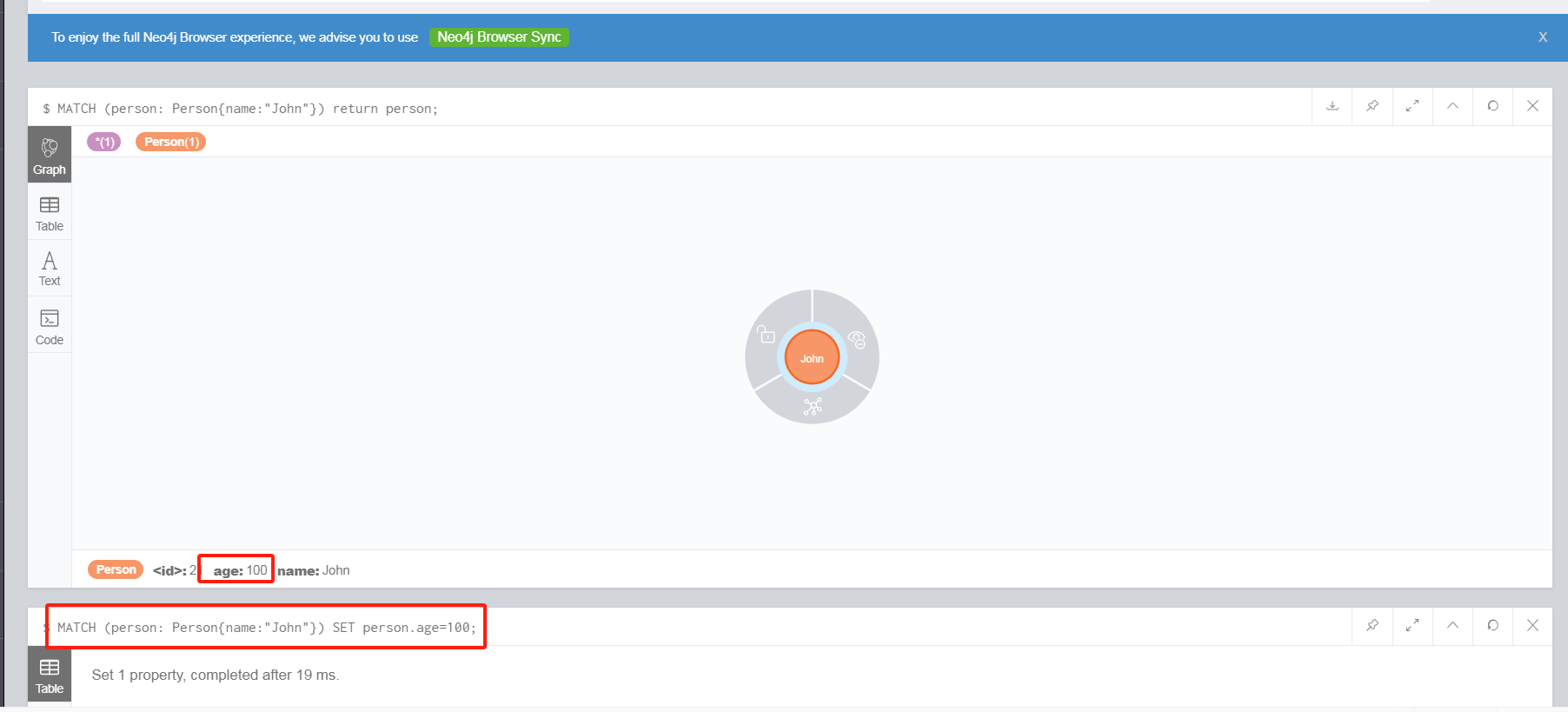
也可以同时修改多个属性,中间用逗号隔开即可。
注意:即使我新建 John 节点的时候没有给他指定 phone 属性,但是丝毫不影响我修改节点时给他加上一个 phone 属性。
MATCH (person: Person{name:"John"})
SET person.age=100, person.phone='12345';
删除节点
删除节点也很简单,显示用 MATCH 查询节点,然后对查询结果的句柄使用 DELETE 删除即可
MATCH (person: Person{name:"John"}) DELETE person;
如果节点还有关系的话,直接删除节点是会报错的——这个比较好理解,关系是建立在节点的基础上的,如果节点没了,那么和这个节点关联的关系如何自处?
 当然还可以使用带 WHERE 语句的复杂查询 。
当然还可以使用带 WHERE 语句的复杂查询 。
MATCH (person: Person) WHERE person.age>25 DELETE person;
关系操作
在图当中,除了针对节点的操作,各个节点之间还有相应的关系。
创建关系
在Neo4j中,关系是将两个节点连接在一起的东西。要在Neo4j中创建关系,需要使用以下语法:
CREATE (node_name_1:label_type)-[:relationship_type {property:value}]->(node_name_2:label_type);
比如,我们给 John 和 Sandra 之间创建一个朋友关系 FriendWith
CREATE (person1:Person{name: "John"})-[r:FriendWith{year:3}]->(person2:Person{name: "Sandra"})
当然,也可以使用 MATCH 和 MERGE 的组合来创建关系(注意箭头方向,我这里创建的一个反向关系,而且 FriendWith 关系是双向的也完全说得通):
MATCH (person1:Person {name: "John"}), (person2:Person {name: "Sandra"})
MERGE (person1)<-[r:FriendWith{years:3}]-(person2);
查询关系
关系查询上面已经有示例了,比如我要查询 John 和 Sandra 之间的关系:
MATCH p=(:Person{name: "John"})-[r:FriendWith]-(:Person{name: "Sandra"}) RETURN p
也可以通过 WHERE 语句对节点和关系的属性进行限制:
MATCH p=(person1:Person)-[r:FriendWith]-(person2:Person)
WHERE person1.name="John"
AND person2.name="Sandra"
AND r.years=3
RETURN p修改关系
通节点一样,关系的熟悉修改也使用 SET,比如我们修改 John 和 Sandra 的好友关系时间为 5 年
MATCH p=(person1:Person)-[r:FriendWith]-(person2:Person)
WHERE person1.name="John"
AND person2.name="Sandra"
SET r.years=5
RETURN p
删除关系
MATCH p=(person1:Person{name: "John"})-[r:FriendWith]-(person2:Person{name: "Sandra"})
DELETE r 注意:上面的删除语句,如果使用 DELETE p 的话,会将节点和关系一并删除掉的哟!
注意:上面的删除语句,如果使用 DELETE p 的话,会将节点和关系一并删除掉的哟!
看下面语句的执行结果,节点也被删除了,所以使用时千万要小心。

如果删除关系的时候,节点还有其他关系,使用 DELETE p 会怎么样呢?
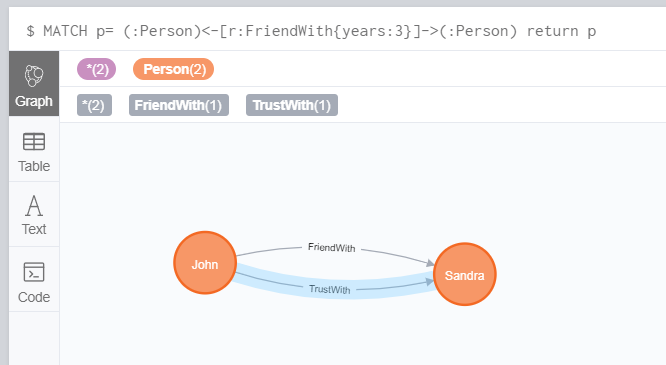
我们可以看到,除了 MATCH 匹配到的关系,如果节点之间还有其他关系,删除节点的话是会报错的哟。
 删除操作(DELETE)
删除操作(DELETE)
一般图数据库中,除了离散的节点,还有和节点相关联的关系,当节点还有关系时,单独删除节点并不可行,此时,还需要将和删除节点相关的关系都一并删除才行。
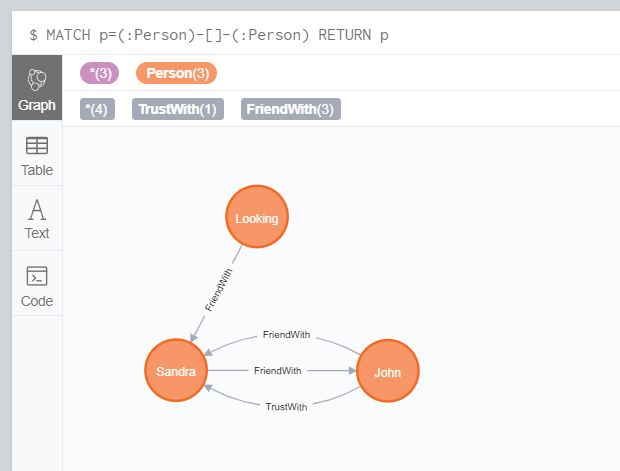
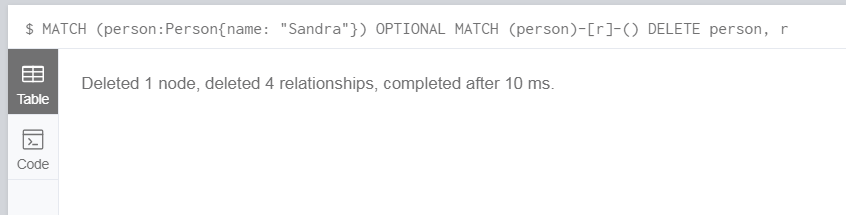
比如,我们要删除 Sandra 以及和 Sandra 相关联的关系 (r 后面没有添加关系标签,是为了让 r 匹配和 Sandra 相关的任何关系):
MATCH (person:Person{name: "Sandra"})
OPTIONAL MATCH (person)-[r]-()
DELETE person, r从返回结果可以看到,Sandra 节点以及和它相关的 4 个关系已被删除
移除属性 (REMOVE)

比如我们移除 John 的 age 属性:
MATCH (person:Person{name: "John"})
REMOVE person.age
排序操作 (ORDER BY)
比如将人员查询结果按照年龄降序排序:
MATCH (p:Person)
RETURN p
ORDER BY p.age DESC
结果合并(UNION 和 UNION ALL)
MATCH (p:Person{name: "John"})
RETURN p
UNION
MATCH (p:Person)
WHERE p.age=40
RETURN p
查询和 John 有好友和家庭关系的的节点名称:

UNION ALL 不会去重
MATCH (n:Person {name: 'John'})-[:FamilyWith]->(f)
RETURN f.name AS name
UNION ALL
MATCH (n:Person {name: 'John'})-[:FriendWith]->(f)
RETURN f.name AS name;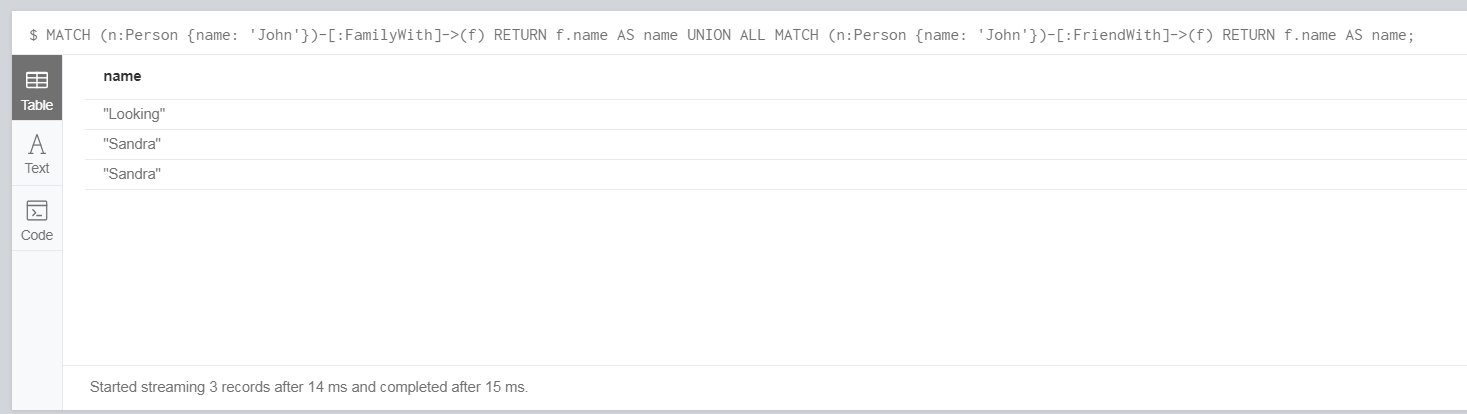 UNION 会去重
UNION 会去重
MATCH (n:Person {name: 'John'})-[:FamilyWith]->(f)
RETURN f.name AS name
UNION
MATCH (n:Person {name: 'John'})-[:FriendWith]->(f)
RETURN f.name AS name;
偏移和限制(LIMIT 和 SKIP)
MATCH (n)
RETURN n.property
SKIP m
LIMIT nn 表示要返回的结果集数量,m 表示要跳过的结果集数量。使用 LIMIT 和 SKIP 子句时,返回的结果集将会是从跳过指定数量的结果集之后的前 n 个结果集。
简单理解 SKIP 类似于 SQL 的 OFFSET,表示偏移量, LIMIT 同 SQL 的 LIMIT
不加限制
MATCH (p:Person)
RETURN p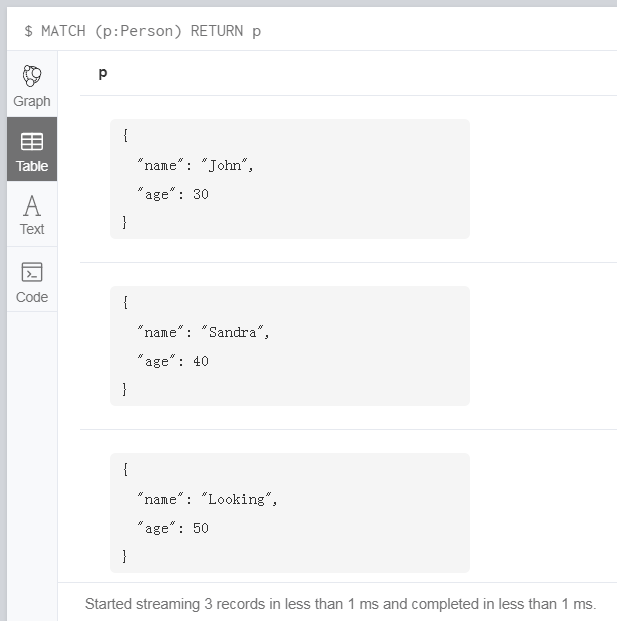
限制 LIMIT
MATCH (p:Person)
RETURN p
LIMIT 2 
限制 SKIP 和 LIMIT
MATCH (p:Person)
RETURN p
SKIP 1
LIMIT 2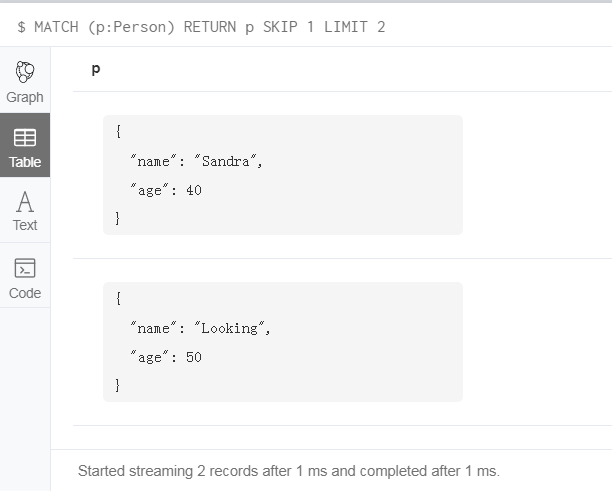
MERGE
MERGE 前面的例子有使用过,MERGE 是一种用于创建或更新节点和关系的关键字。它可以用于合并现有的节点和关系,也可以用于创建新的节点和关系。 可以简单理解为 SQL 中的 UPSERT(UPDATE + INSERT),如果查询到的关系和节点已存在则更新,否则创建。
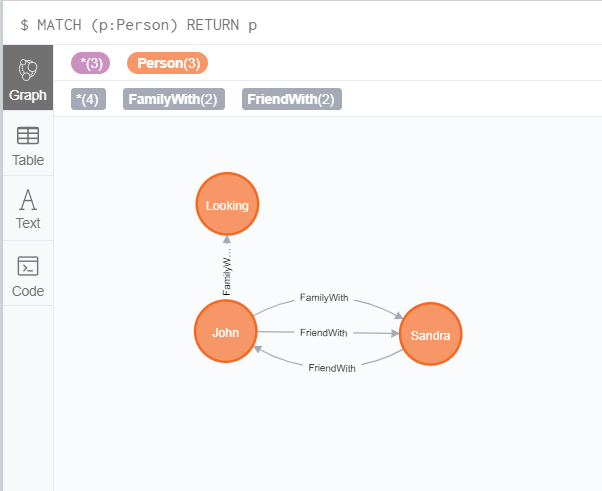
就比如节点创建时,我们先试试用 MREGE 创建同名 Looking 节点,与原 Looking 节点属性完全保持一致(发现没有变化)。
MERGE (p:Person{name: "Looking", age: 50})
当然,如果新节点的属性和旧节点属性不完全一致,使用 MERGE 也是会创建新的节点的。
我们再试试用 MREGE 创建同名 Looking 节点(创建成功) :
CREATE (p:Person{name: "Looking", age: 50})

这两个 Looking 节点的属性完全一样(当然,系统为了区分,对应的 id 不一样)。
NULL
-
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
-
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
-
还可以用 NULL 作为查询的条件。

比如我已经删除了 Looking 节点的 age 属性。
MATCH (p:Person)
WHERE p.age IS NULL
RETURN p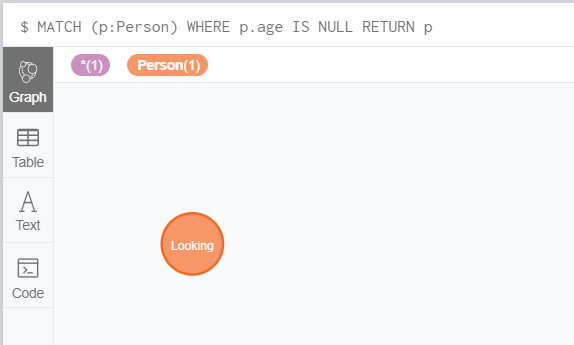
IN
Neo4j CQL提供了一个 IN 运算符,以便为 CQL 命令提供值的集合判断。
MATCH (p:Person)
WHERE p.age IN [30, 40]
RETURN p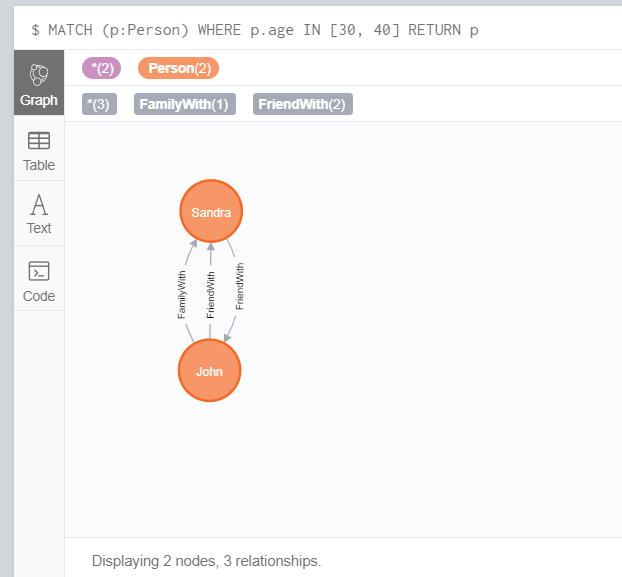
这篇关于Neo4j 之安装和 CQL 基本命令学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






