本文主要是介绍【HDFS】关于HDFS-17497:在commit block时更新quota,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链接:https://github.com/apache/hadoop/pull/6765
Ticket标题:The number of bytes of the last committed block should be calculated into the file length。
HDFS里,一个在写入的文件可能包含多个commited状态的块。
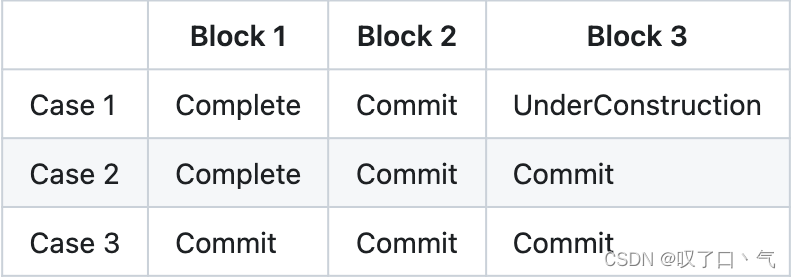
但是计算文件大小的时候,最后一个commited block并没有被计算进去,但是却包含了其他的commited blocks。
如下代码:
/*** Compute file size of the current file.* * @param includesLastUcBlock* If the last block is under construction, should it be included?* @param usePreferredBlockSize4LastUcBlock* If the last block is under construction, should we use actual* block size or preferred block size?* Note that usePreferredBlockSize4LastUcBlock is ignored* if includesLastUcBlock == false.* @return file size*/<这篇关于【HDFS】关于HDFS-17497:在commit block时更新quota的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









