本文主要是介绍百问C语言第1问——彻底弄懂define用法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
玩转指针专栏
趣味c程序专栏
一.c语言关系操作符练习题(新手必会)
一.c语言常见概念(超全)
一.趣味c程序—关机程序(整蛊同学版)
二.趣味c程序—猜数字游戏(含干货知识点
三.趣味c程序—打印图形(1)(含干货知识点)
目录
- 系列文章目录
- 🥙前言
- 🥪#define的用法
- 🍑1.#define常见用法
- 🌳定义常量
- 🌳定义宏函数(注意点)
- 🍑2.理解#define的 两个要点
- 🍑3.核心计算:只替换不计算(两道例题)
- 🌳例题1详解
- 🌳例题2详解
- 🌳定义带参数的宏进行循环计算
- 🍑4.#define使用注意事项
- 🌳注意1
- 🌳注意2
- 🍑5.#define和函数对比(了解)
- 🍑【总结】
- 🍑【写在后面】
🥙前言
为什么学define?
在写程序时经常会碰到这样一个问题,我们需要 重复写很多相同的代码,并且这些
代码结构相同。总是想自己把这段代码封装一下然后直接进行调用,但是如果这段代码逻辑并不复杂,并且代码量也不大,不适合进行封装,那么我们就会想到c/c++中的关键字——define
点击这里,查看所有玩转指针专栏的文章!
点击这里,查看所有百问C语言栏的文章!

🥪#define的用法
🍑1.#define常见用法
常量是使用频率很高的一个量。常量是指在程序运行过程中,其值不能被改变的量。常量常使用#define来定义。 使用#define定义的常量也称为符号常量,可以提高程序的运行效率。
其常见的用法包括两种,分别是:
1)#define 宏名 宏值
2)#define 宏名(参数列表) 表达式 🌳定义常量
使用 #define 可以定义常量,这些常量在编译时会被其值替换。
#define PI 3.14159
在代码中,任何出现 PI 的地方都会被替换为 3.14159
#define MAX 100 // 将 MAX 这个标识符和 100 这个数字关联起来
#define REG register // 为 register 这个关键字,创建一个简短的名字REG
#define STR "test_string" // 用 STR 这样一个名字来代替 test_string 这样一个字符串int main()
{REG int a = MAX; // 这里的 reg 被解释成 register关键字,MAX 被解释成 100printf("%d\n", a);printf("%s\n", STR); return 0;
}

🌳定义宏函数(注意点)
使用 #define 可以定义常量,这些常量在编译时会被其值替换。
#define Add(a,b) a+b;
📝【注意】
在一般使用的时候是没有问题的,但是如果遇到如:c * Add(a,b) * d的时候就会出现问题,代数式的本意是a+b然后去和c,d相乘,但是因为使用了define(它只是一个简单的替换),所以式子实际上变成了ca + bd
#define MAX(a, b) ((a) > (b) ? (a) : (b))
在代码中,任何出现 PI 的地方都会被替换为 3.14159
在上面的例子中,MAX 是一个宏函数,它接受两个参数并返回它们中的较大值。注意,因为宏函数在编译时进行文本替换,所以需要在参数周围加上括号以确保正确的运算顺序。
`
🍑2.理解#define的 两个要点
📝【小总结】
1.*#define 是预处理指令,用于定义常量或宏,当你使用 #define 定义了一个宏时,预处理器(preprocessor)会在编译之前将宏名替换为其定义的内容,这个过程是简单的文本替换,而不是计算或执行
2.由于 #define 仅仅是替换而不进行计算,所以你需要特别小心,因为不恰当的宏定义可能会导致意外的结果或错误。
🍑3.核心计算:只替换不计算(两道例题)
下面是一个简单的例子来帮助你理解 #define 的只替换不计算:
🌳例题1详解
#include <stdio.h> #define SQUARE(x) x * x int main() { int a = 5; int b = SQUARE(a + 1); // 这里会替换为 (a + 1) * (a + 1),而不是 (a * a) + 1 printf("b = %d\n", b); // 输出 36,而不是预期的 26 // 为了得到正确的平方和加1,你需要使用括号来确保运算顺序 #define CORRECT_SQUARE(x) ((x) * (x)) int c = CORRECT_SQUARE(a + 1); // 这里会替换为 ((a + 1) * (a + 1)) printf("c = %d\n", c); // 输出 36,这是正确的 (a + 1) 的平方 // 另一个例子,显示没有计算 #define MULTIPLY_BY_TWO(x) x * 2 int d = MULTIPLY_BY_TWO(5 + 3); // 这里会替换为 5 + 3 * 2,由于运算符优先级,结果是 11 而不是 16 printf("d = %d\n", d); // 输出 11 return 0;
}
这个例子中,你可以看到 SQUARE(a + 1) 被替换为 (a + 1) * (a + 1),而不是你可能期望的 (a * a) + 1。同样,MULTIPLY_BY_TWO(5 + 3) 被替换为 5 + 3 * 2,由于乘法优先级高于加法,所以结果是 11 而不是 16。
为了避免这类问题,你需要在宏定义中谨慎使用括号,以确保运算顺序和优先级与你的预期相符。
🌳例题2详解
#define N 3 #define Y(n) ((N+1)*n)
则执行语句z=2*(N+Y(5+1));后,z的值为( )。
接下来,我们要执行语句 z=2*(N+Y(5+1));。在这个语句中,Y(5+1) 宏会被替换。
📝【替换过程】
Y(5+1) 替换为 ((N+1)(5+1))(注意这里 n 被替换为 5+1)。
由于 N 被定义为 3,所以 ((N+1)(5+1)) 替换为 ((3+1)*(5+1))。
现在,完整的表达式 z=2*(N+Y(5+1)); 变为:
z = 2 * (3 + ((3+1)*(5+1)));
计算这个表达式:
z = 2 * (3 + (4*6));
z = 2 * (3 + 24);
z = 2 * 27;
z = 54;
🌳定义带参数的宏进行循环计算
#include <stdio.h> #define SUM_UP_TO(n) ((n > 0) ? (n + SUM_UP_TO(n-1)) : 0) int main() { int sum = SUM_UP_TO(5); // 这将展开为 5 + 4 + 3 + 2 + 1 + 0 printf("Sum up to 5 is %d\n", sum); // 输出 15 return 0;
}
🍑4.#define使用注意事项
🌳注意1
使用#define定义带有运算符的符号常量时,一定要对每个量都加上圆括号,以避免出现不必要的错误
📝【看看前面的和定义宏函数的注意点和例题就知道啦!】
🌳注意2
符号常量同名的问题:
以下写法是正确的
#include"stdio.h"
#define PROD 2 * 5
#define PROD 2 * 5
int main()
{printf( "%d", PROD );return 0;
}但是以下使用#define定义PROD 会提示告警:第三行代码“PROD ”redefiened
也就是说,使用#define定义重复的符号常量时,如果运算符的前后都有空格,则不提示告警,否会提示告警。因此使用#define带有运算符的常数之间的运算需要注意符号常量不要重名。
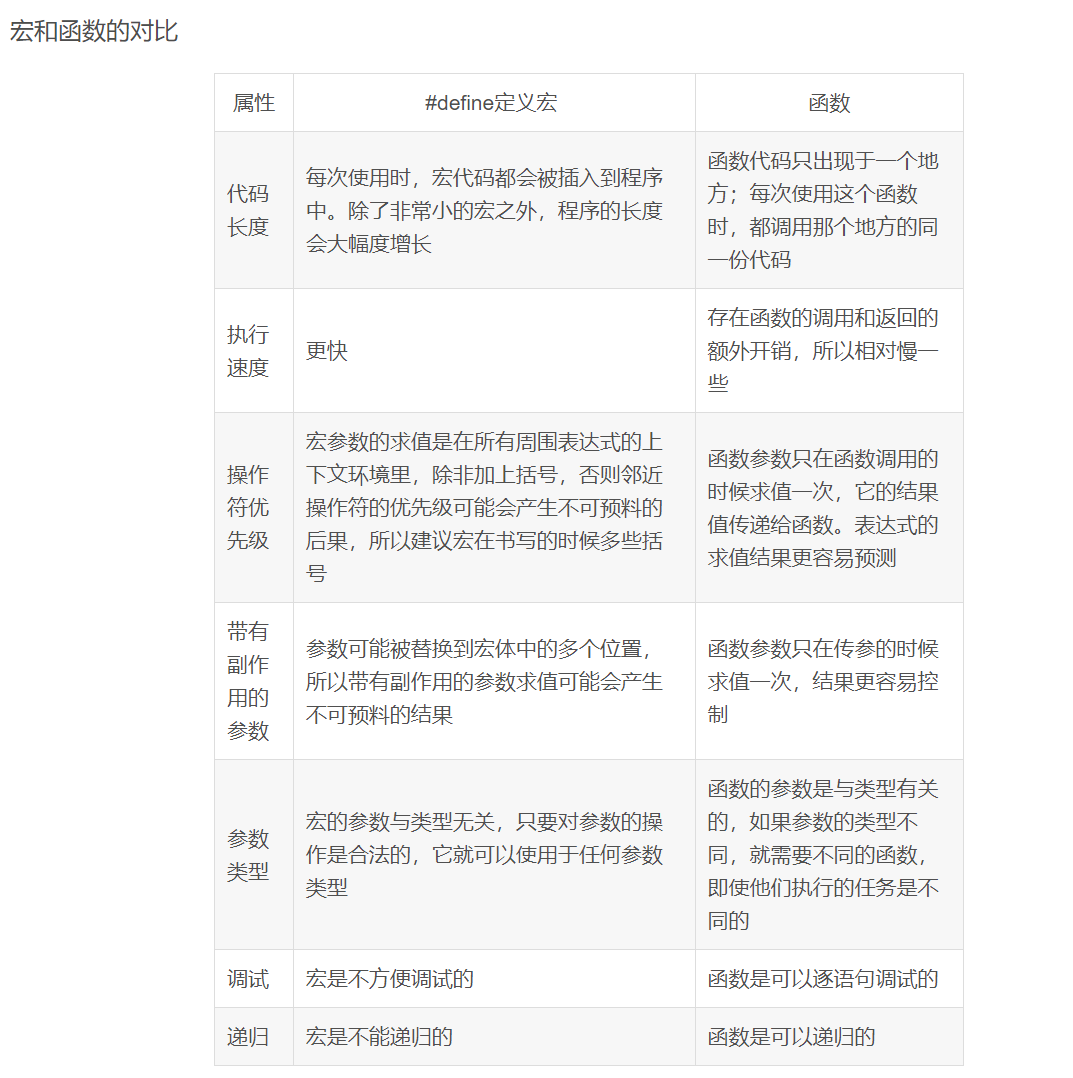
🍑5.#define和函数对比(了解)
把宏名全部大写
函数名不要全部大写
宏通常被应用于执行简单的运算,比如在两个数中找出较大的一个
#define MAX(a, b) ((a)>(b)?(a):(b))
那为什么不用函数来完成这个任务?原因有二:
用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和速度方面更胜一筹
更为重要的是函数的参数必须声明为特定的类型。
所以函数只能在类型合适的表达式上使用。反之这个宏怎可以适用于整形、长整型、浮点型等可以用于来比较的类型。宏是类型无关的

宏有时候可以做函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到
#define MALLOC(num, type)\
(type *)malloc(num * sizeof(type))
...
//使用
MALLOC(10, int);//类型作为参数
//预处理器替换之后:
(int*)malloc(10 * sizeof(int));
🍑【总结】
1.宏定义是在预处理阶段进行的,所以在定义宏时不需要在末尾添加分号(;)。2.由于宏定义只是简单的文本替换,所以定义宏函数时要特别注意参数的使用,确保在替换后不会产生语法错误或逻辑错误。3.#define 定义的宏是全局的,可以在文件的任何地方访问。4.#undef 指令用于取消之前定义的宏。5.宏定义通常用于常量定义和简单的函数替换,对于复杂的函数或功能,建议使用函数来实现。

🍑【写在后面】
百问C语言系列之后会陆续更新,看看小编码字的份上,各位帅哥和姐姐麻烦给个关注,如果喜欢,可以点赞和收藏我的专栏,虽然小编目前大一非科班,不过我会继续更新我的内容,努力成长。如果内容出现错误,恳请批评指正。

点击这里,查看所有玩转指针专栏的文章!
点击这里,查看所有百问C语言栏的文章!
这篇关于百问C语言第1问——彻底弄懂define用法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





