本文主要是介绍Leetcode 剑指 Offer II 077.排序链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目难度: 中等
原题链接
今天继续更新 Leetcode 的剑指 Offer(专项突击版)系列, 大家在公众号 算法精选 里回复
剑指offer2就能看到该系列当前连载的所有文章了, 记得关注哦~
题目描述
给定链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
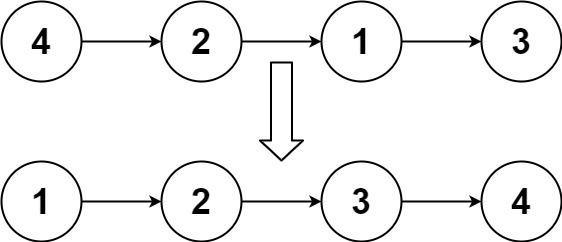
- 输入:head = [4,2,1,3]
- 输出:[1,2,3,4]
示例 2:
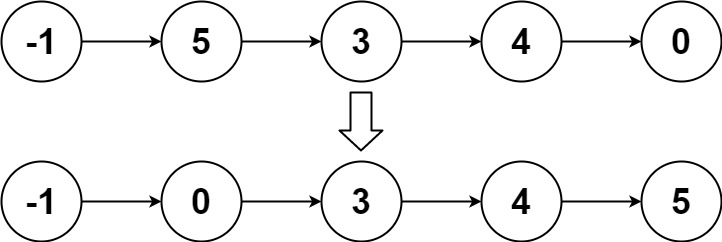
- 输入:head = [-1,5,3,4,0]
- 输出:[-1,0,3,4,5]
示例 3:
- 输入:head = []
- 输出:[]
提示:
- 链表中节点的数目在范围 [0, 5 * 10^4] 内
- -10^5 <= Node.val <= 10^5
进阶:你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
题目思考
- 如何做到 O(n log n) 时间复杂度和常数级空间复杂度?
解决方案
思路
- 分析题目, 一个很容易想到的思路就是将链表每个节点存到一个数组中, 然后使用自定义排序, 对数组按照节点的值从小到大排序, 再依次连起来即可
- 不过这样虽说时间复杂度可以做到 O(NlogN), 但使用了额外空间, 不满足进阶要求, 如何优化呢?
- 要想做到常数级空间复杂度排序, 首先就不能采用递归, 因为递归有额外递归栈的空间消耗
- 另外题目给的是单向链表, 不好从后往前遍历, 所以经典的快速排序在这里也不适用, 如果额外增加向前的连接, 又需要额外空间
- 常见的 O(NlogN)排序还有归并排序, 虽然递归归并的实现方式比较经典, 但我们也可以利用迭代的方式实现, 这样就可以做到常数级空间复杂度
- 具体思路就是先将相邻的单个节点进行归并, 然后再将 2 个节点作为整体, 将相邻部分归并, 然后是 4 个, 8 个, 以此类推, 最终实现全部节点的排序
- 举个例子, 对于链表
1->5->4->3->0->2- 第一步, 对相邻节点从小到大归并排序, 即 1 和 5 归并, 4 和 3 归并, 0 和 2 归并, 得到
1->5->3->4->0->2 - 第二步, 对相邻两个节点从小到大归并排序, 即
1->5和3->4归并,0->2不变, 得到1->3->4->5->0->2 - 第二步, 对相邻四个节点从小到大归并排序, 即
1->3->4->5和0->2归并, 得到0->1->2->3->4->5
- 第一步, 对相邻节点从小到大归并排序, 即 1 和 5 归并, 4 和 3 归并, 0 和 2 归并, 得到
- 这样只需要 logN 次归并, 然后每次归并只需要遍历每个节点常数次, 总体时间复杂度是 O(NlogN), 且没有使用额外空间
- 具体实现方面, 我们需要记录链表总长度和当前归并部分的长度
- 然后针对每个归并长度遍历整个链表, 分别得到当前待归并的左右部分, 归并后再继续下个左右部分的归并, 直到达到末尾
- 最终当归并长度大于等于总长度时, 说明整个链表已经排序好了, 返回链表头即可
- 另外注意在遍历过程中需要处理好节点的连接关系, 避免导致无限循环
- 下面代码给出了每一步详细的注释, 大家可以结合代码和注释来理解
复杂度
- 时间复杂度 O(NlogN): 每次归并排序的长度都是上次长度乘以 2, 所以一共只需要归并 logN 次, 然后每次归并时需要遍历所有节点两遍 (一遍记录左右部分的头和尾, 一遍实际归并), 这部分时间复杂度是 O(N), 所以整体时间复杂度就是 O(NlogN)
- 空间复杂度 O(1): 只使用了几个常数空间的变量
代码
class Solution:def sortList(self, head: ListNode) -> ListNode:def merge(head1, head2):# 将链表head1和head2进行归并排序# 使用哨兵节点简化处理dummy = ListNode(0)cur = dummywhile head1 or head2:if not head2 or head1 and head1.val <= head2.val:# head2为空, 或者head1的值更小, 追加head1cur.next = head1# head1向后移动head1 = head1.nextelse:# 此时只能追加head2cur.next = head2# head2向后移动head2 = head2.next# 当前节点向后移动cur = cur.next# 返回归并排序后的链表头和尾return (dummy.next, cur)# 统计原始链表的节点数n = 0cur = headwhile cur:cur = cur.nextn += 1# 从长度为1的两个链表开始归并排序cnt = 1# 使用哨兵节点简化处理dummy = ListNode(0, head)# 只要长度不超过n, 就说明有至少两个链表需要归并while cnt < n:# ptail存储前一个归并好的链表的末尾, 初始化为哨兵ptail = dummy# cur是当前处理的节点cur = dummy.nextwhile cur:# lhead和ltail是当前待归并的左侧链表头和尾lhead = curltail = cur# 遍历lcnt个节点, 并更新ltail和curlcnt = cntwhile lcnt > 0 and cur:ltail = curcur = cur.nextlcnt -= 1if ltail:# 断开ltail和右侧的连接ltail.next = None# rhead和rtail是当前待归并的右侧链表头和尾rhead = currtail = cur# 遍历rcnt个节点, 并更新rtail和currcnt = cntwhile rcnt > 0 and cur:rtail = curcur = cur.nextrcnt -= 1if rtail:# 断开rtail和右侧的连接rtail.next = None# 归并左右链表, 得到归并后的新链表的头和尾nhead, ntail = merge(lhead, rhead)# 将前一个归并部分的尾指向当前归并部分的头ptail.next = nhead# 然后更新ptail尾当前归并部分的尾ptail = ntail# 归并长度乘以2, 不断循环归并排序更大长度的两部分, 直到整个链表有序cnt *= 2# 最终哨兵节点的下一个节点就是全部排序后的头return dummy.next
大家可以在下面这些地方找到我~😊
我的 GitHub
我的 Leetcode
我的 CSDN
我的知乎专栏
我的头条号
我的牛客网博客
我的公众号: 算法精选, 欢迎大家扫码关注~😊

这篇关于Leetcode 剑指 Offer II 077.排序链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




