本文主要是介绍Mycat使用与部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mycat使用与部署
- 前言
- 内容
- 简介
- 应用
- 基本概念
- 技术分析
- 目录结构
- 分片处理
- 连续分片
- 离散分片
- 综合分片
- 全局序列处理
- 小结
前言
今天和大家说说数据库中间件Mycat

图片源自 Mycat官方网站 对于Mycat1.6版本的结构
内容
简介
Mycat是目前活跃的开源数据库中间件,是一个彻底开源的面向企业应用开发的大数据库集群,它支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法.
应用
在平时的项目中会用到Mycat来解决项目中MySQL数据库的如下三个主要问题
- 数据库连接数
- 表数据量大(空间)
- 索引命不中全表扫描
- 索引命中 存储在硬盘里IO操作
- 硬件资源(QPS/TPS)
主要用到的功能有读写分离和f分库分表
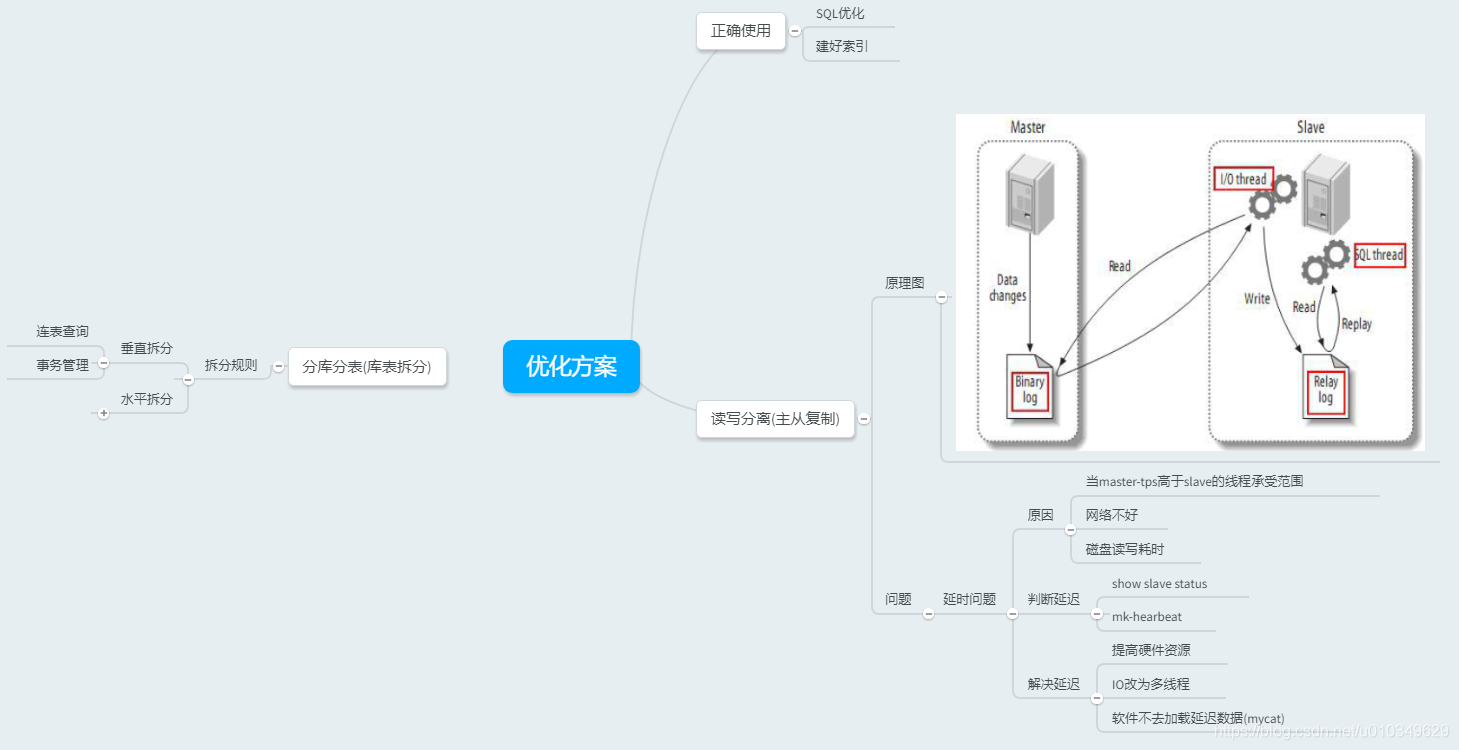
基本概念
下面和大家说说在Mycat中的一些基本概念
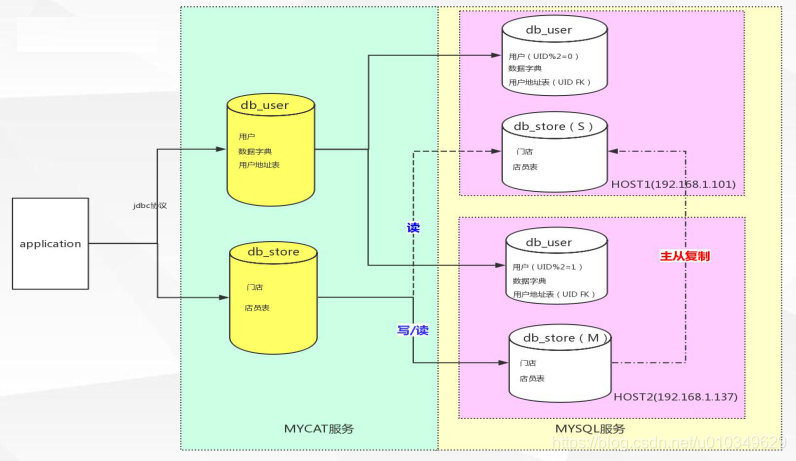
Mycat服务区域中-黄色标注的两个数据库是Mycat中定义的 逻辑库: db_user 与 db_store
Mycat服务区域中-黄色标注的五个表是Mycat中定义的 逻辑表: 用户表\数据字典\用户地址表\门店\店员表
MySQL服务区域中-两个紫色区域代表两台服务器
MySQL服务区域中-两个db_user数据库是Mycat管理的拆分数据库
分表条件是根据对用户表的UID对2取模, 不同条件可在Mycat-Conf文件下的rule.xml文件配置.
数据字典表是两个库查询数据时常会连接的表单,由于数据量较小且为主要连表查询的信息所以在Mycat中配置为全局表.
用户地址表的增删改查都与用户表的UID有着密切的联系.所以可以在Mycat中将其配置为ER表,关联条件就是外键—用户表的UID.
MySQL服务区域中-两个db_store数据库是Mycat管理的主从数据库
技术分析
目录结构
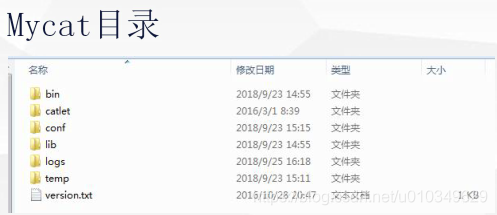
- /bin 存放可执行文件./mycat {start|restart|stop|status…}
- /conf 存放配置文件
- server.xml -Mycat 服务器参数设置和用户授权的配置文件(启动参数)
<system><property name="useSqlStat">0</property><!-- 1为开启实时统计、0为关闭 --><property name="useGlobleTableCheck">0</property><!-- 1为开启全加班一致性检测、0为关闭 --><property name="sequnceHandlerType">2</property><!-- <property name="useCompression">1</property>--><!--1为开启mysql压缩协议--><!-- <property name="fakeMySQLVersion">5.6.20</property>--><!--设置模拟的MySQL版本号--><!-- <property name="processorBufferChunk">40960</property> --><!-- <property name="processors">1</property><property name="processorExecutor">32</property> --><!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena--><property name="processorBufferPoolType">0</property><!--默认是65535 64K 用于sql解析时最大文本长度 --><!--<property name="maxStringLiteralLength">65535</property>--><!--<property name="sequnceHandlerType">0</property>--><!--<property name="backSocketNoDelay">1</property>--><!--<property name="frontSocketNoDelay">1</property>--><!--<property name="processorExecutor">16</property>--><!--<property name="serverPort">8066</property> <property name="managerPort">9066</property><property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property><property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> --><!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志--><property name="handleDistributedTransactions">0</property><!--off heap for merge/order/group/limit 1开启 0关闭 --><property name="useOffHeapForMerge">1</property><!--单位为m --><property name="memoryPageSize">1m</property><!--单位为k --><property name="spillsFileBufferSize">1k</property><property name="useStreamOutput">0</property><!--单位为m --><property name="systemReserveMemorySize">384m</property><!--是否采用zookeeper协调切换 --><property name="useZKSwitch">true</property></system><!-- 全局SQL防火墙设置 --><!-- <firewall><whitehost><host host="127.0.0.1" user="mycat"/><host host="127.0.0.2" user="mycat"/></whitehost><blacklist check="false"></blacklist></firewall> --><user name="root"><property name="password">123456</property><property name="schemas">db_store,db_user</property><!-- 表级 DML 权限设置 --><!-- <privileges check="false"><schema name="db_user" dml="0110" ><table name="users" dml="1111"></table> IUSD<table name="useraddres" dml="1110"></table></schema></privileges> --></user>
- schema.xml - 逻辑库和逻辑表的定义
<schema sqlMaxLimit="100" checkSQLschema="false" name="db_store"><table name="store" primaryKey="storeID" dataNode="db_store_dataNode"/><table name="employee" primaryKey="employeeID" dataNode="db_store_dataNode"/></schema><schema sqlMaxLimit="100" checkSQLschema="false" name="db_user"><table name="data_dictionary" primaryKey="dataDictionaryID" dataNode="db_user_dataNode1,db_user_dataNode2" type="global"/><table name="users" primaryKey="userID" dataNode="db_user_dataNode$1-2" rule="mod-userID-long"><childTable name="user_address" primaryKey="addressID" parentKey="userID" joinKey="userID"/></table></schema><!-- 节点配置 --><!-- db_store --><dataNode name="db_store_dataNode" database="db_store" dataHost="db_storeHOST"/><!-- db_user --><dataNode name="db_user_dataNode1" database="db_user" dataHost="db_userHOST1"/><dataNode name="db_user_dataNode2" database="db_user" dataHost="db_userHOST2"/><!-- 节点主机配置 --><!-- 配置db_store的节点主机 --><dataHost name="db_storeHOST" slaveThreshold="100" switchType="1" dbDriver="native" dbType="mysql" writeType="0" balance="1" minCon="10" maxCon="1000"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost password="123456" user="root" url="192.168.8.137:3306" host="hostM1"><!-- can have multi read hosts --><readHost password="123456" user="root" url="192.168.8.101:3306" host="hostS1"/></writeHost></dataHost><!-- 配置db_user的节点主机 --><dataHost name="db_userHOST1" slaveThreshold="100" switchType="1" dbDriver="native" dbType="mysql" writeType="0" balance="0" minCon="10" maxCon="1000"><heartbeat>select user()</heartbeat><writeHost password="123456" user="root" url="192.168.8.137:3306" host="userHost1"> </writeHost></dataHost><dataHost name="db_userHOST2" slaveThreshold="100" switchType="1" dbDriver="native" dbType="mysql" writeType="0" balance="0" minCon="10" maxCon="1000"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost password="123456" user="root" url="192.168.8.101:3306" host="userHost2"> </writeHost></dataHost>
- rule.xml - 分片规则的配置文件
<?xml version="1.0" encoding="UTF-8"?><mycat:rule xmlns:mycat="http://io.mycat/"><tableRule name="rule1"><rule><columns>id</columns><algorithm>func1</algorithm></rule></tableRule><tableRule name="rule2"><rule><columns>user_id</columns><algorithm>func1</algorithm></rule></tableRule><tableRule name="sharding-by-intfile"><rule><columns>sharding_id</columns><algorithm>hash-int</algorithm></rule></tableRule><tableRule name="auto-sharding-long"><rule><columns>id</columns><algorithm>rang-long</algorithm></rule></tableRule><tableRule name="mod-long"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule></tableRule><tableRule name="mod-userID-long"><rule><columns>userID</columns><algorithm>mod-long</algorithm></rule></tableRule><tableRule name="sharding-by-murmur"><rule><columns>id</columns><algorithm>murmur</algorithm></rule></tableRule><tableRule name="crc32slot"><rule><columns>id</columns><algorithm>crc32slot</algorithm></rule></tableRule><tableRule name="sharding-by-month"><rule><columns>create_time</columns><algorithm>partbymonth</algorithm></rule></tableRule><tableRule name="latest-month-calldate"><rule><columns>calldate</columns><algorithm>latestMonth</algorithm></rule></tableRule><tableRule name="auto-sharding-rang-mod"><rule><columns>id</columns><algorithm>rang-mod</algorithm></rule></tableRule><tableRule name="jch"><rule><columns>id</columns><algorithm>jump-consistent-hash</algorithm></rule></tableRule><function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function><function name="murmur" class="io.myc+.....+tion.PartitionByMurmurHash"><property name="seed">0</property><!-- 默认是0 --><property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --><property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 --><!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 --><!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 --></function><function name="crc32slot" class="io.m+.....+tion.PartitionByCRC32PreSlot"><property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 --></function><function name="hash-int" class="io.myc+....+ction.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property></function><function name="rang-long" class="io.m+....+tion.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property></function><function name="func1" class="io.mycat.route.function.PartitionByLong"><property name="partitionCount">8</property><property name="partitionLength">128</property></function><function name="latestMonth" class="io.m+....+tion.LatestMonthPartion"><property name="splitOneDay">24</property></function><function name="partbymonth" class="io.m+....+ction.PartitionByMonth"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2015-01-01</property></function><function name="rang-mod" class="io.m+....+ction.PartitionByRangeMod"><property name="mapFile">partition-range-mod.txt</property></function><function name="jump-consistent-has+..+.PartitionByJumpConsistentHash"><property name="totalBuckets">3</property></function></mycat:rule>
-
- log4j2.xml - 配置logs目录日志输出规则
-
- wrapper.conf - JVM相关参数设置
-
/lib - 主要存放 mycat 依赖的一些 jar 文件
-
/logs - 存放日志文件
分片处理
连续分片
- 实例
根据日期范围分片
根据数字范围分片 - 优点
扩容无须迁移数据
范围条件查询资源消耗少 - 缺点
数据热点问题
并发能力受限于分片节点
离散分片
- 实例
枚举分片
数字取模分片(如本文分析的Mycat部署例图)
字符串Hash分片 - 优点
数据分布均匀
并发能力强不受分片节点限制 - 缺点
移植性差-扩容难
综合分片
将连续分片与离散分片结合使用
- 实例
范围求模分片
取模范围分片
全局序列处理
由于我们通过Mycat对原有数据进行了分库分表的操作,那么对每条数据的全局唯一标识就是一个需要解决的问题,关于全局序列的处理Mycat为我们提供了以下三种方式:
-
本地文件方式
步骤
sequenceHandlerType=0
配置sequence_db_conf.properties
使用next value for MYCATSEQ_XXX
问题
无法持久化,Mycat重启就会丢失 -
数据库自动生成方式
步骤
sequenceHandlerType=1
配置sequence_db_conf.properties
使用next value for MYCATSEQ_XXX
指定autoIncrement
问题
多线程,两个表之间会串号 -
本地时间戳
步骤
ID=64位 二进制(42毫秒+5机器ID+5业务编码+12重复累加)
sequenceHandlerType=2
配置sequence_db_conf.properties
指定autoIncrement
小结
在项目应用中Mycat的管理还提供了-弱XA事务机制-节点扩缩容量-数据快速移植等功能的支持,以上是我对Mycat的整理笔记,还有很多需要完善,将与Mycat开发组一同前行学习,荣幸与您分享~
这篇关于Mycat使用与部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




