本文主要是介绍redis的双写一致性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
双写一致性问题
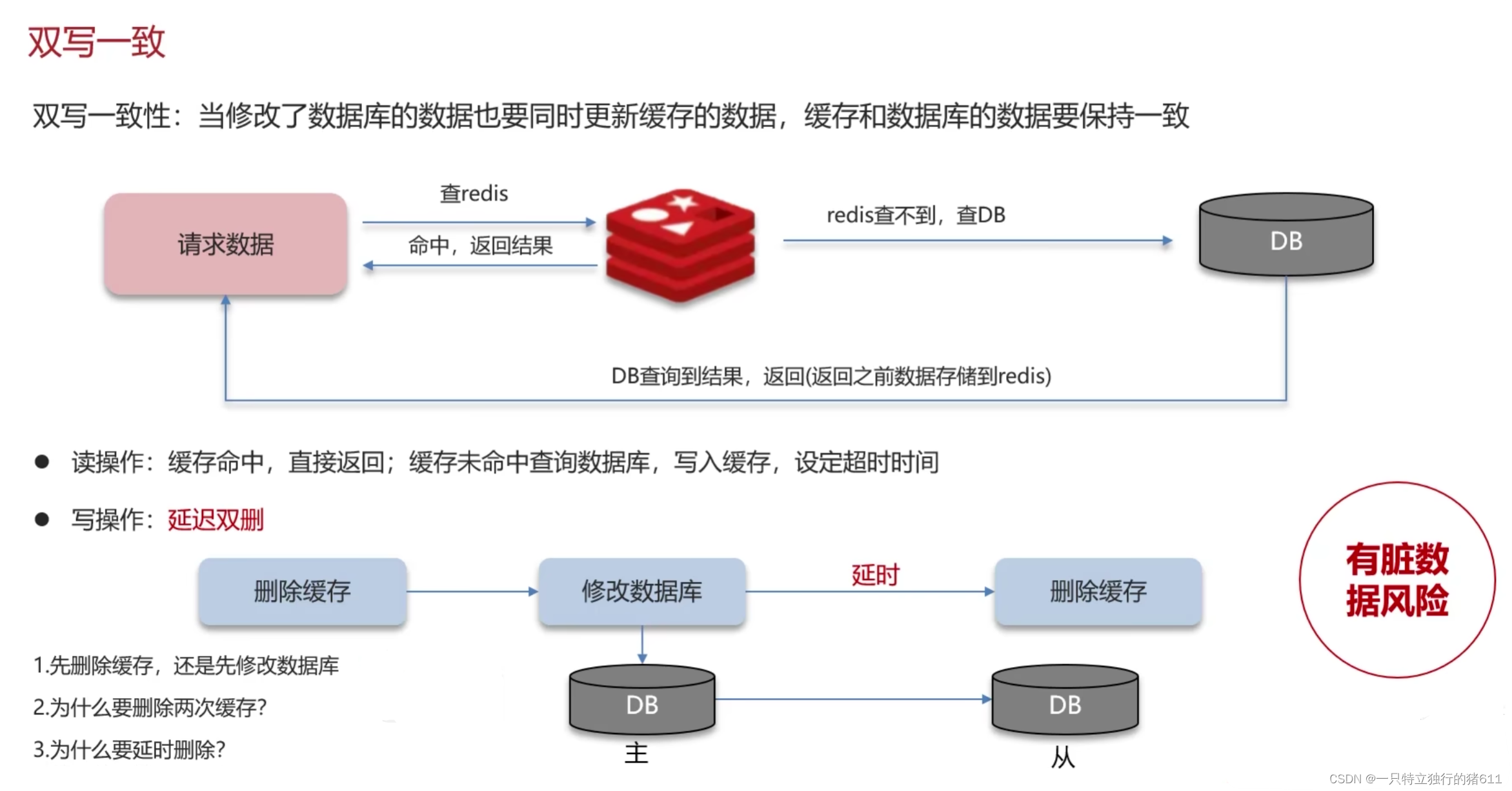
1.先删除缓存或者先修改数据库都可能出现脏数据。
2.删除两次缓存,可以在一定程度上降低脏数据的出现。
3.延时是因为数据库一般采用主从分离,读写分离。延迟一会是让主节点把数据同步到从节点。
1.读写锁保证数据的强一致性
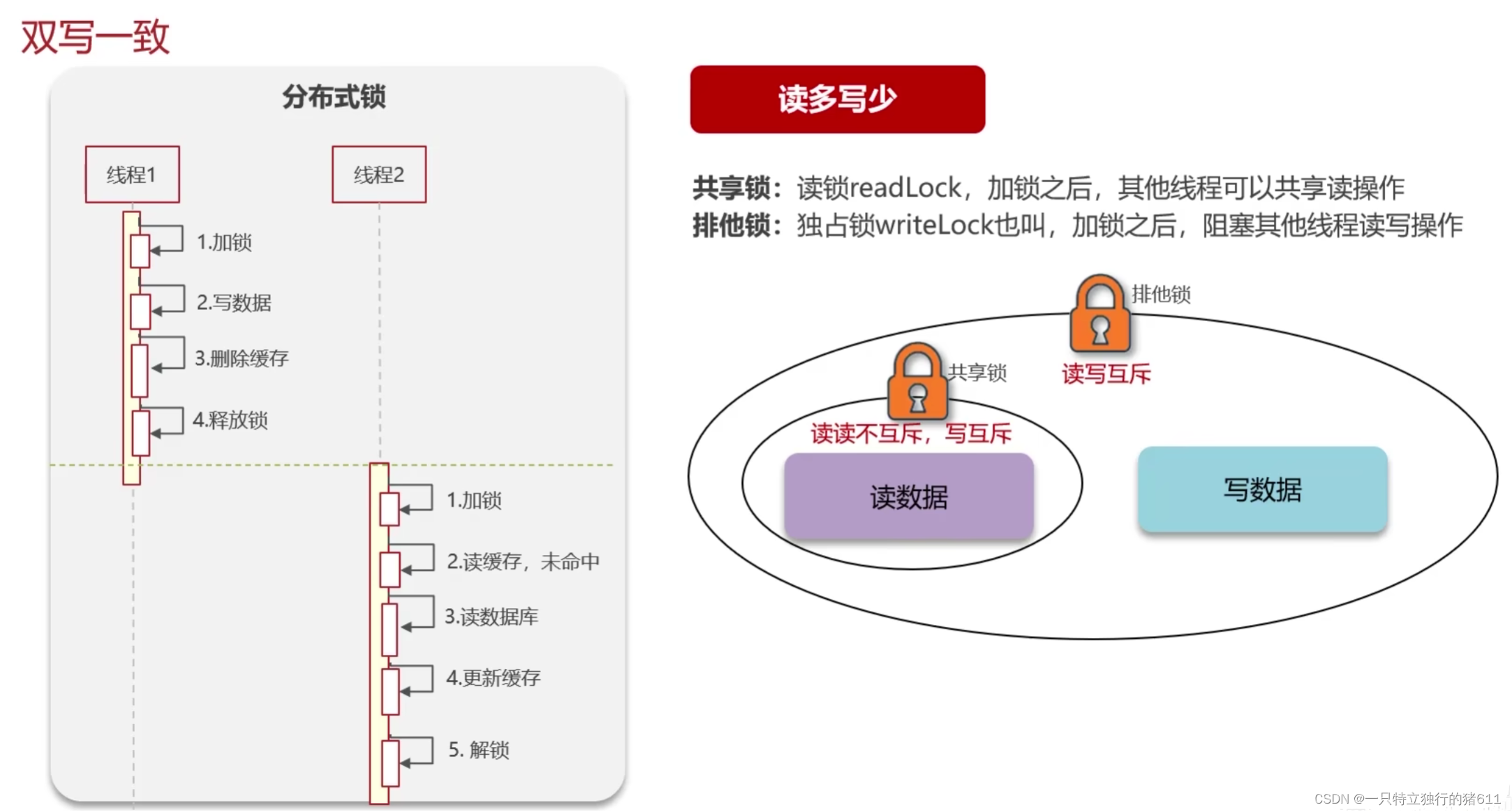
因为一般放入缓存中的数据都是读多写少(如果读少写多,就不用缓存了,直接操作数据库)。因此,用读写锁可以保证数据的强一致性。但缺点就是性能低,因为写数据时,其他线程还是要等待。
2.消息队列保证数据最终一致
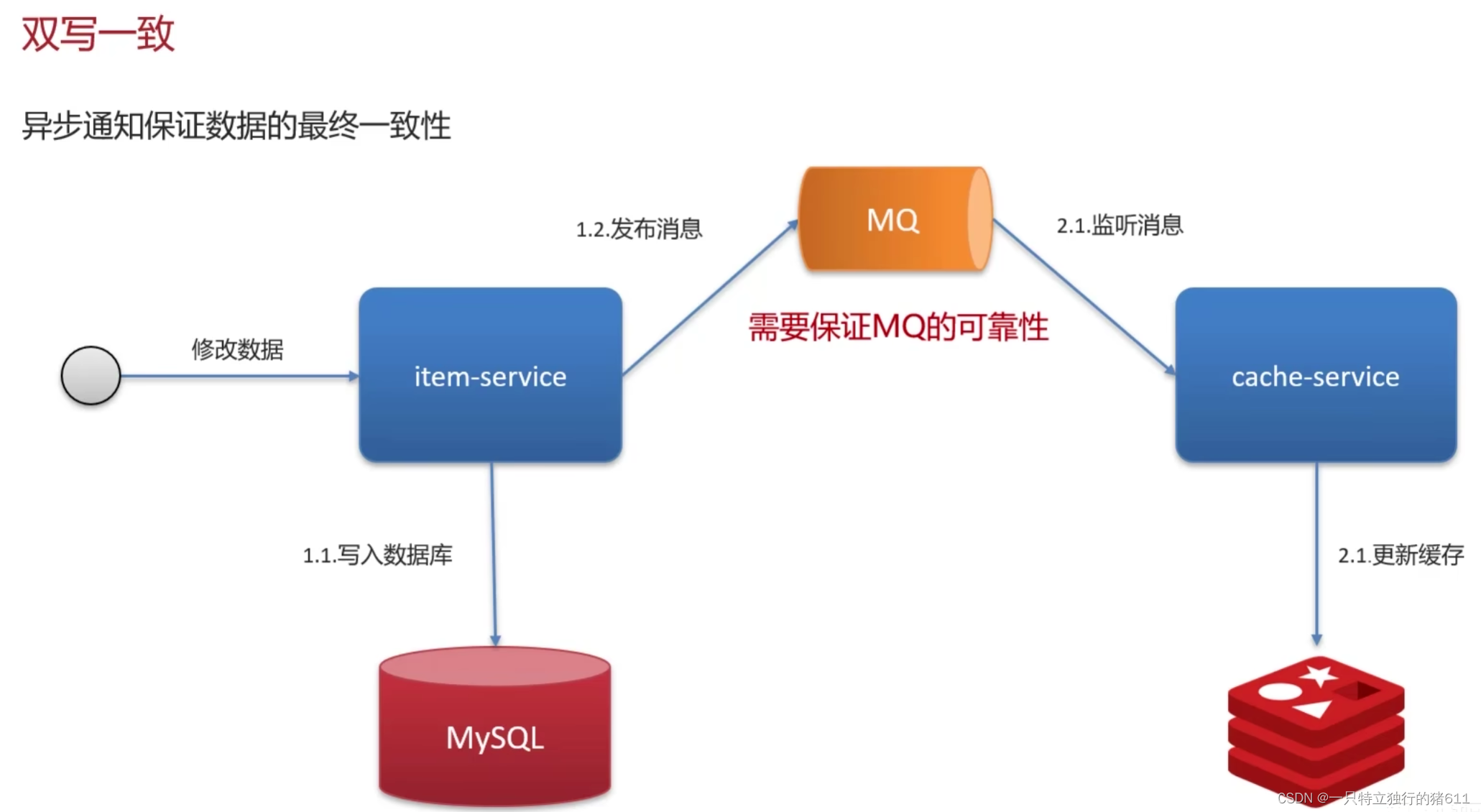
这种情况可能有短暂的数据延迟,但效率高。
3.基于Canal的异步通知(和方法2类似)
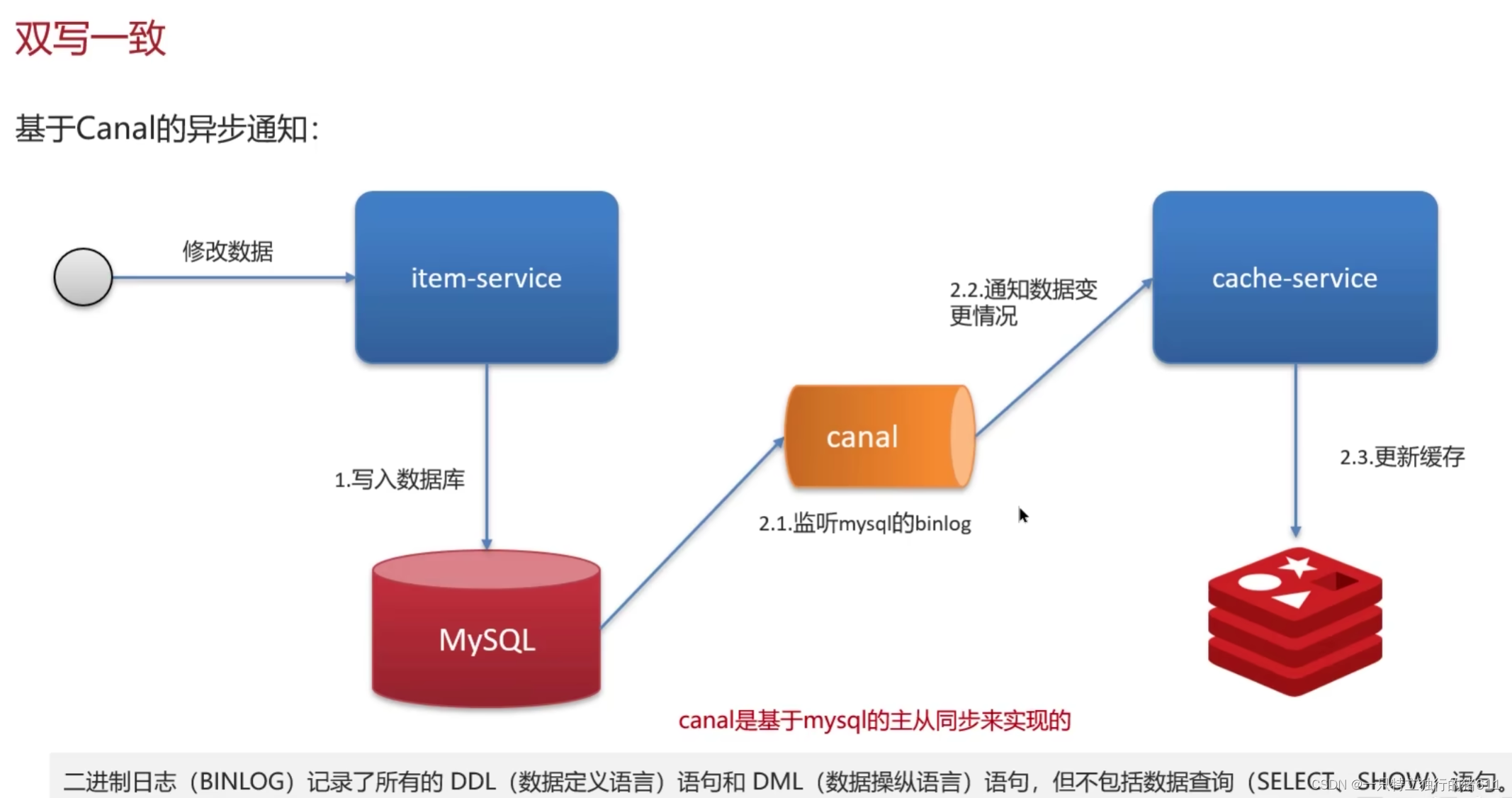
优点:对于业务代码几乎零侵入。 缺点:还是可能有短暂的数据延迟。
总结:

这篇关于redis的双写一致性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





