本文主要是介绍Kafka ,LEO和HW更新时机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们假设有一个topic,单分区,副本因子是2,即一个leader副本和一个follower副本。我们看下当producer发送一条消息时,broker端的副本到底会发生什么事情以及分区HW是如何被更新的。
下图是初始状态,我们稍微解释一下:初始时leader和follower的HW和LEO都是0(严格来说源代码会初始化LEO为-1,不过这不影响之后的讨论)。leader中的remote LEO指的就是leader端保存的follower LEO,也被初始化成0。此时,producer没有发送任何消息给leader,而follower已经开始不断地给leader发送FETCH请求了,但因为没有数据因此什么都不会发生。值得一提的是,follower发送过来的FETCH请求因为无数据而暂时会被寄存到leader端的purgatory中,待500ms(replica.fetch.wait.max.ms参数)超时后会强制完成。倘若在寄存期间producer端发送过来数据,那么会Kafka会自动唤醒该FETCH请求,让leader继续处理之。

第一种情况:follower发送FETCH请求在leader处理完PRODUCE请求之后
producer给该topic分区发送了一条消息。此时的状态如下图所示:
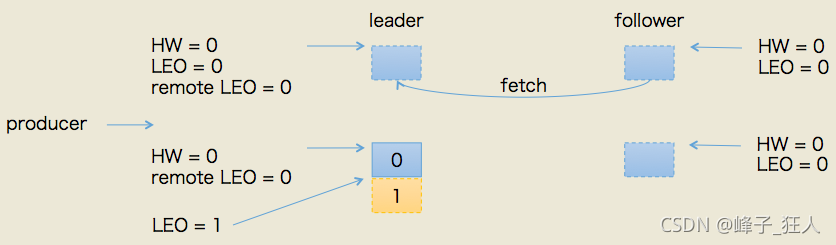
如图所示,leader接收到PRODUCE请求主要做两件事情:
1.把消息写入写底层log(同时也就自动地更新了leader的LEO)
2.尝试更新leader HW值(前面leader副本何时更新HW值一节中的第三个条件触发)。我们已经假设此时follower尚未发送FETCH请求,那么leader端保存的remote LEO依然是0,因此leader会比较它自己的LEO值和remote LEO值,发现最小值是0,与当前HW值相同,故不会更新分区HW值
所以,PRODUCE请求处理完成后leader端的HW值依然是0,而LEO是1,remote LEO是1。假设此时follower发送了FETCH请求(或者说follower早已发送了FETCH请求,只不过在broker的请求队列中排队),那么状态变更如下图所示:
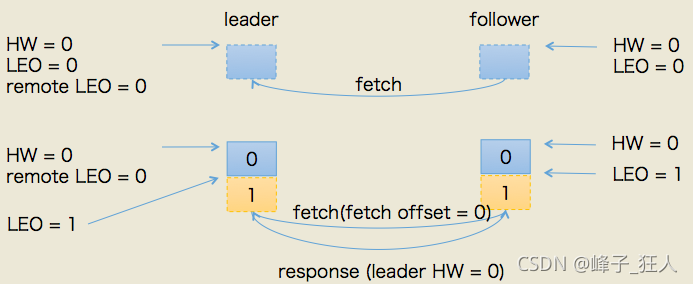
本例中当follower发送FETCH请求时,leader端的处理依次是:
1.读取底层log数据
2.更新remote LEO = 0(为什么是0? 因为此时follower还没有写入这条消息。leader如何确认follower还未写入呢?这是通过follower发来的FETCH请求中的fetch offset来确定的)
3.尝试更新分区HW——此时leader LEO = 1,remote LEO = 0,故分区HW值= min(leader LEO, follower remote LEO) = 0
4.把数据和当前分区HW值(依然是0)发送给follower副本
而follower副本接收到FETCH response后依次执行下列操作:
1.写入本地log(同时更新follower LEO)
2.更新follower HW——比较本地LEO和当前leader HW取小者,故follower HW = 0
此时,第一轮FETCH RPC结束,我们会发现虽然leader和follower都已经在log中保存了这条消息,但分区HW值尚未被更新。实际上,它是在第二轮FETCH RPC中被更新的,如下图所示:

上图中,follower发来了第二轮FETCH请求,leader端接收到后仍然会依次执行下列操作:
1.读取底层log数据
2.更新remote LEO = 1(这次为什么是1了? 因为这轮FETCH RPC携带的fetch offset是1,那么为什么这轮携带的就是1了呢,因为上一轮结束后follower LEO被更新为1了)
3.尝试更新分区HW——此时leader LEO = 1,remote LEO = 1,故分区HW值= min(leader LEO, follower remote LEO) = 1。注意分区HW值此时被更新了!!!
4.把数据(实际上没有数据)和当前分区HW值(已更新为1)发送给follower副本
同样地,follower副本接收到FETCH response后依次执行下列操作:
1.写入本地log,当然没东西可写,故follower LEO也不会变化,依然是1
2.更新follower HW——比较本地LEO和当前leader LEO取小者。由于此时两者都是1,故更新follower HW = 1 (注意:我特意用了两种颜色来描述这两步,后续会谈到原因!)
Okay,producer端发送消息后broker端完整的处理流程就讲完了。此时消息已经成功地被复制到leader和follower的log中且分区HW是1,表明consumer能够消费offset = 0的这条消息。
这篇关于Kafka ,LEO和HW更新时机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







