本文主要是介绍五十六、JAVA和C++谁快,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:RednaxelaFX
链接:https://www.zhihu.com/question/50137261/answer/119636825
来源:知乎
不加限定语就说“Java性能已经达到甚至超过C++”纯属耍流氓 >_< 这种对Java性能的过分自信,作为参与过HotSpot VM和Zing VM的实现的俺来说也无法认同。
要是有人跑了benchmark然后说Java的性能比C++好,俺的第一反应也会是:真的么?得看看这benchmark到底测的是什么,有没有错误解读结果。
反之亦然。不加限定语就说C++的性能完胜Java同样属于耍流氓,不过俺遇到这种论调通常都不会试图去争辩,因为对方多半不是有趣的目标听众…
说到底,C++在比Java更底层的位置上,拥有更灵活的操纵接近底层的资源的能力,所以给充分时间做优化的话,无论如何也能比Java写的程序跑得快。所以一旦讨论向着这种不考虑开发时间的方向发展之后,通常就没啥可讨论的了,C++必胜。
有趣的限定语之一就是应用场景。例如说磁盘或网络I/O为主的应用类型,如果用Java实现,并且如果正确使用了Java中此场景下zero-copy的技巧,跟一个同算法用C++实现的版本性能不会有多少差别的。
这就是为什么单纯用C++来重写一次Hadoop(而不改进其设计或算法)的话并不会有显著的性能提升——这样的重写并不会成就一个跟原装MapReduce相同水平的系统。
有趣的限定语之二是microbenchmark。Benchmark可以用来测许多不同的方面,例如应用的启动速度、顶峰速度等。然而一个使用JIT编译或者自适应动态编译的JVM,其性能必然是慢慢提升的;而一个AOT编译的系统(例如C或C++,或者比较少见的JVM),它在代码执行的层面上一开始就已经在最终状态了,启动时就以接近顶峰速度来运行。在这种前提下用写C++的microbenchmark的方式去测Java的顶峰性能,那就是纯打压Java一侧的分数大杀器。
如果要在常见JVM上测Java的顶峰性能,通常需要正确的预热。使用专门用来写microbenchmark的框架,例如jmh,可以有效地在进入测分阶段前正确预热。否则的话请选用一个做AOT编译的JVM。
题主的原问题之一的:
而且教育版的Minecraft为什么要用C++重写呢?
我不知道教育版Minecraft是神马状况,但原版Minecraft可是写得很烂的Java。硬要说的话是Java代码的反面教材(即便它那么流行)。这个就算不用别的语言重写,它的Java版本也早该重写了(1s
==============================================
放个半相关的传送门吧:LLVM相比于JVM,有哪些技术优势? - RednaxelaFX 的回答
像C或者C++,在事先编译(AOT)时可以充分利用closed-world assumption来做优化,而且用户对编译时间的容忍程度通常比较高(特别是对最终的product build的编译时间容忍度更高),所以可以做很多相当耗时的优化,特别是耗时的interprocedural analysis。
我所熟悉的JVM中,JIT编译最缺失的优化就是interprocedural analysis。JVM很可能会选择用非常受限的形式的interprocedural analysis来做优化,例如CHA(Class Hierarchy Analisys);又或者是借助大量的方法内联(method inlining)来达到部分interprocedural analysis的效果。
即便是上面的传送门举的例子,Zing JVM里基于LLVM写的新JIT编译器,还是只做非常有限的interprocedural analysis的。例如说如果我们可以有whole-program alias analysis的话就无敌了,但是没有…
(有些特化的JVM会在AOT编译时做有趣的interprocedural analysis,例如Oracle Labs的Substrate VM。论文之一可参考 Safe and efficient hybrid memory management for Java )
==============================================
不过反过来,有些C++程序员觉得新奇(其实C++编译器也已经做了很久或者渐渐开始流行起来)的优化,在高性能JVM上倒是稀松平常的事。
- 一个是PGO,profile-guided optimization。常见的JVM会不断收集运行中的程序的type profile、branch profile、invocation/loop profile等,并将其应用到JIT优化中。再放个半相关的传送门:JIT编译,动态编译与自适应动态编译 - 编程语言与高级语言虚拟机杂谈(仮) - 知乎专栏
- 一个是LTO,link-time optimization。在常见JVM上运行的Java程序,本来就是做lazy/dynamic linking的,而等到JIT编译的时候正好dynamic linking已经做好了,所以可以完全利用上linking后的状态来做优化。这样,跨模块的优化(例如说跨模块的方法内联)就是稀松平常的事。
- 看看常见的C++环境中,跨越动态链接库的边界会不会做函数内联?这事情不是完全不能做,但是要做就得把一个优化器带在运行时库里动态去做,对很多C++程序员来说这是不可思议的(再次强调,这不是不能做,只是很多人不习惯这种做法)
- 一个是虚函数内联,inlining of virtual method invocations。很多C++程序员会说C++的虚函数通过多态指针去调用的话无法内联,一说起虚函数调用就想到vtable。这个当然也是误解,其实C++编译器可以实现若干技巧来实现虚函数的内联,并非一定要通过vtable去调用。但在高性能JVM里如果不能高效地内联虚方法的话,性能就彻底完蛋了,所以不得不使用各种技巧来内联。再次放个半相关的传送门:HotSpot VM有没有对invokeinterface指令的方法表搜索进行优化? - RednaxelaFX 的回答
- 送上介绍C++编译器通过CHA来做虚函数的去虚化(devirtualization)的论文:Optimization of Object-Oriented Programs Using Static Class Hierarchy Analysis, Jeffrey Dean, David Grove, Craig Chambers, ECOOP'95
对于我们做编译器优化的人来说,Java相比C++最爽(适合优化)的一点就是指针的类型安全:Java里,一个引用(底下由直接指针实现)声明是什么类型的,就可以相信它一定是什么类型的;而在C++的优化编译器里,指针类型通常被认为是不可信的,只有在非常高优化级别用尽一切可压榨的信息来优化时才会相信它。
这意味着,在Java里,下面的方法:
static int foo(int[] a, byte[] b) {// ...
}
可以直接通过类型信息就靠谱地得到a与b不会alias的结论,因为a与b的静态类型不兼容,运行时肯定不会指向同一对象。而相似的C或C++代码:
int foo(int* a, char* b) {// ...
}
则不能单纯通过类型信息而得到a与b一定不alias的结论。
此外,Java的引用只可能引用对象的固定位置(例如说对象的起始位置),而不像C或C++的指针可以指向到对象的任意位置(例如任意指向到对象的内部)。所以通过一个Java引用去访问不同的offset,也足以确定这两个offset是不会alias的。
这就是说,在Java里,下面的方法:
static int foo(int[] a, int[] b) {a[0] = b[1];// ...
}
虽然a和b的静态类型都是int[],无法通过类型信息来判断a与b不alias,但接下来访问a[0]与b[1]肯定不会alias。
而相似的C或C++代码:
int foo(int* a, int* b) {a[0] = b[1];// ...
}
不但a与b是否alias无法确定,a[0]与b[1]是否alias也无法确定。
至于alias analysis对优化有多重要,相信同行们会会心一笑。在HotSpot VM的Server Compiler(C2)里,基于type + offset结合memory slicing做的alias analysis还是颇为有效的。
==============================================
关于GC嗯…放几个传送门:
- 为什么 Python 工程师很少像 Java 工程师那样讨论垃圾回收? - RednaxelaFX 的回答
- Go1.6中的gc pause已经完全超越JVM了吗? - RednaxelaFX 的回答
- Java 大内存应用(10G 以上)会不会出现严重的停顿? - RednaxelaFX 的回答
- Azul Systems 是家什么样的公司? - RednaxelaFX 的回答
- C++ 短期内在华尔街的买方和卖方还是唯一选择吗? - RednaxelaFX 的回答
==============================================
有些关于Java性能比C++好的几种常见误解点,这里也想稍微讨论一下。
0、用Java程序的性能跟GCC / Clang的-O0、-O1来比性能。
答:这不是自取其辱么。像HotSpot VM、IBM J9 VM里的JIT编译器,在其顶层编译的时候,默认自带的优化程度至少是跟GCC -O2在同一水平的——或者说那是目标。如果通过抑制对比的对方的优化程度来做比较,那有啥意思了。
1、JVM通过JIT编译可以更好的利用CPU的特定指令,比C++事先编译(AOT)的模型好。
答:并不是。看情况。有很多情况会影响这种说法在现实中的有效性。
其一是某个具体的JIT编译器到底有没有针对某些CPU的新指令做优化。如果没有,那说啥都是白说。而像GCC、LLVM这些主流编译器架构背后都有很多大厂支持,对新指令的跟进是非常快的——至少比HotSpot VM的JIT编译器对x86的新指令的跟进要快和全面。如果本机用的程序自己在本机上-march=native来编译,那便是对自己机器的CPU特性的最好利用。
而像Intel的icc所带的库,很多都是对各种不同的Intel CPU事先编译出了不同的版本,一股脑带在发布包里,到程序启动时检测CPU特性来选择对应最匹配的版本的库动态链接上,这样也可以充分利用CPU的特性。
总之不要以为用了JIT编译器就比AOT编译器能更充分地使用CPU特性了…这没有必然的因果关系。
2、JIT在运行时编译可以更好地利用profile-guided optimization。
答:也不一定。
看前面一个关于JIT和自适应动态编译的传送门,例如说CLR的JIT编译器就用不上PGO,因为它的编译时机太早了,还没来得及收集profile。
而对于AOT编译的模型,也可以通过training run收集profile来做offline PGO,同样可以得到PGO的好处。这种AOT编译利用PGO的模型,跟JIT在运行时收集profile并做PGO的模型相比,最大的好处是AOT编译是offline的,各种传统优化可以做得更彻底;而缺点是如果training program跟实际应用的profile匹配度不高,或者实际应用在运行时行为有phase shift,那这种offline的做法就无法很好的应对了。不过说真的,能高效应对phase shift的JIT系统也不多…
==============================================
最后纯娱乐一下,放个截图:
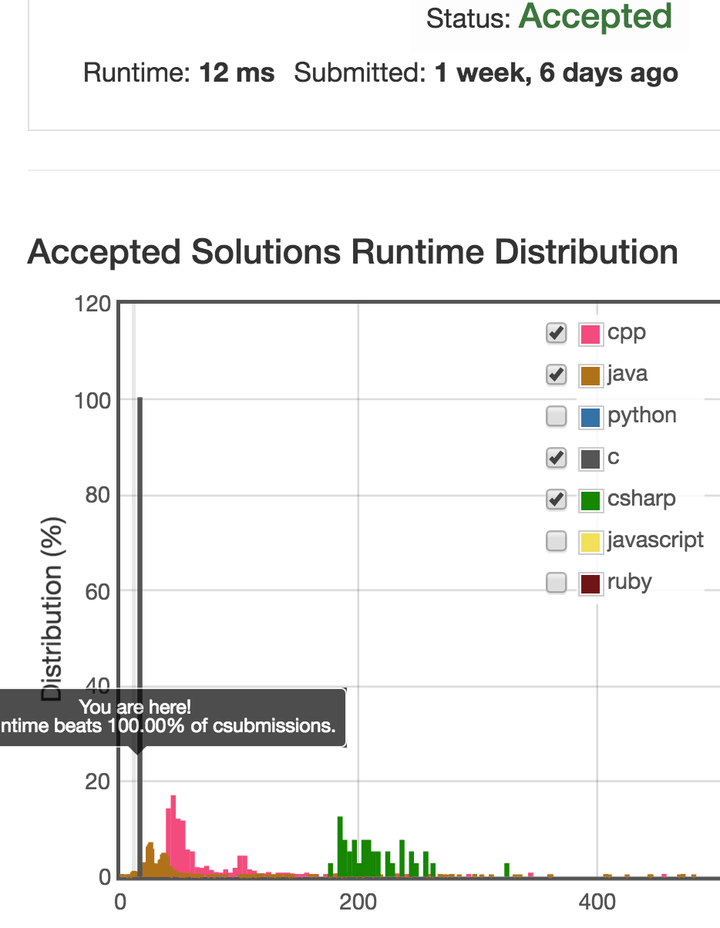
这是leetcode上的297。截图是我用C写的解的用时状况。
我自己是做JVM的JIT编译器的,我都无法理解为啥这题会有那么多Java submission的时间那么短。感觉肯定是哪里出错了(不是开玩笑。
要是有机会的话得问问leetcode的人看他们到底是怎么跑Java的…
看评论区说不同语言的测试用例好像是不一样的。原来有这种事?——在leetcode做Java时间统计的
@Deep Reader
大大的回答说所有语言的测试用例都是一样的,但是Java的时间统计剪掉了一些前后的开销。
这篇关于五十六、JAVA和C++谁快的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






