本文主要是介绍数据库期末复习资料,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
考纲
选择 10分
简答题 25分
ER图+建表 15分
建表以后的范式的分解、规范化 15分
Sql语句 35分 :关系代数,select,触发器
--------------------------------------数据库设计-----------------------------------
第一章:
1.数据库部分
2.三级结构、两级独立性
第二章:
1.ER图
2.三个世界
3.数据模型出选择
4.关系模型的基本概念
5.关键字的概念
6.简答:为什么要做规范化,原因是什么? 不规范增删改都会有异常。
8.PPT上的五类题型
------------------------------SQL 语句--------------------------------------------------
略
1.数据库完整性
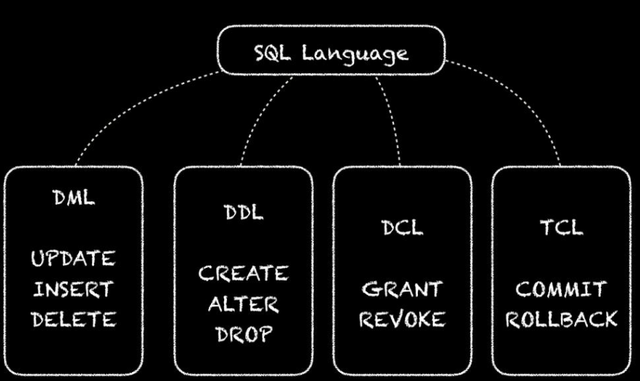
2.sql的 组成:DDL、DML、DCL
1.视图定义
3.修改视图的限制
1.索引的概念
2.索引优点、缺点
3.簇索引和非簇索引的差别
1.存储过程和触发器、定义变量、常见数据类型(整数字符串)、ifelse语句、循环函数
1.可靠性安全性完整性必考其一(简答)
考如何实现
备份的方式,有什么差别
并发控制会造成什么,怎么做,死锁的解法
安全性不同的level
ER图难点(15)
注意三元关系
- 画图
- 转换为关系模式
函数依赖和范式难点(15)
- 判断范式
- 求候选码
- 求最小函数依赖
- 化简为第二范式
- 化简为第三范式
SQL语言(35)
存储过程和触发器、定义变量、常见数据类型(整数字符串)、ifelse语句、循环函数
1.关系代数写查询语句(2个)
连接、选择、投影
2.过程、触发器、视图(2个)
创建视图
视图:可以理解成虚拟表。
(1)编写视图实现查询出所有银行卡账户信息,显示卡号,身份证,姓名,余额。
create view CardAndAccount as
select CardNo 卡号,AccountCode 身份证,RealName 姓名,CardMoney 余额 from BankCard
left join AccountInfo on BankCard.AccountId = AccountInfo.AccountId
go
如果要进行相应信息的查询,不需要编写复杂的SQL语句,直接使用视图,如下:
select * from CardAndAccount
创建存储过程
存储过程(Procedure)是SQL语句和流程控制语句的预编译集合。
(1)没有输入参数,没有输出参数的存储过程。
定义存储过程实现查询出账户余额最低的银行卡账户信息,显示银行卡号,姓名,账户余额
--方案一
create proc proc_MinMoneyCard
asselect top 1 CardNo 银行卡号,RealName 姓名,CardMoney 余额from BankCard inner join AccountInfo on BankCard.AccountId = AccountInfo.AccountIdorder by CardMoney asc
go--方案二:(余额最低,有多个人则显示结果是多个)
create proc proc_MinMoneyCard
asselect CardNo 银行卡号,RealName 姓名,CardMoney 余额from BankCard inner join AccountInfo on BankCard.AccountId = AccountInfo.AccountIdwhere CardMoney=(select MIN(CardMoney) from BankCard)
go
执行存储过程:
exec proc_MinMoneyCard
(2)有输入参数,没有输出参数的存储过程
模拟银行卡存钱操作,传入银行卡号,存钱金额,实现存钱操作
create proc proc_CunQian
@CardNo varchar(30),
@MoneyInBank money
asupdate BankCard set CardMoney = CardMoney + @MoneyInBank where CardNo = @CardNoinsert into CardExchange(CardNo,MoneyInBank,MoneyOutBank,ExchangeTime)values(@CardNo,@MoneyInBank,0,GETDATE())
--go
执行存储过程:
exec proc_CunQian '6225125478544587',3000
(3)有输入参数,没有输出参数,但是有返回值的存储过程(返回值必须整数)。
模拟银行卡取钱操作,传入银行卡号,取钱金额,实现取钱操作,取钱成功,返回1,取钱失败返回-1
create proc proc_QuQian
@CardNo varchar(30),
@MoneyOutBank money
asupdate BankCard set CardMoney = CardMoney - @MoneyOutBank where CardNo = @CardNoif @@ERROR <> 0return -1insert into CardExchange(CardNo,MoneyInBank,MoneyOutBank,ExchangeTime)values(@CardNo,0,@MoneyOutBank,GETDATE())return 1
go
执行存储过程:
declare @returnValue int
exec @returnValue = proc_QuQian '662018092100000002',1000000
print @returnValue
(4)有输入参数,有输出参数的存储过程
查询出某时间段的银行存取款信息以及存款总金额,取款总金额,传入开始时间,结束时间,显示存取款交易信息的同时,返回存款总金额,取款总金额。
create proc proc_SelectExchange@startTime varchar(20), --开始时间@endTime varchar(20), --结束时间@SumIn money output, --存款总金额@SumOut money output --取款总金额
as
select @SumIn = (select SUM(MoneyInBank) from CardExchange where ExchangeTime between @startTime+' 00:00:00' and @endTime+' 23:59:59')
select @SumOut = (select SUM(MoneyOutBank) from CardExchange where ExchangeTime between @startTime+' 00:00:00' and @endTime+' 23:59:59')
select * from CardExchange
where ExchangeTime between @startTime+' 00:00:00' and @endTime+' 23:59:59'
go
执行存储过程:
declare @SumIn money --存款总金额
declare @SumOut money --取款总金额
exec proc_SelectExchange '2018-1-1','2018-12-31',@SumIn output,@SumOut output
select @SumIn
select @SumOut
(5)具有同时输入输出参数的存储过程
密码升级,传入用户名和密码,如果用户名密码正确,并且密码长度<8,自动升级成8位密码
--有输入输出参数(密码作为输入参数也作为输出参数)
--密码升级,传入用户名和密码,如果用户名密码正确,并且密码长度<8,自动升级成8位密码
select FLOOR(RAND()*10) --0-9之间随机数
create proc procPwdUpgrade
@cardno nvarchar(20),
@pwd nvarchar(20) output
asif not exists(select * from BankCard where CardNo=@cardno and CardPwd=@pwd)set @pwd = ''elsebeginif len(@pwd) < 8begindeclare @len int = 8- len(@pwd)declare @i int = 1while @i <= @lenbeginset @pwd = @pwd + convert(floor(rand()*10),nvarchar(1)) set @i = @i+1endupdate BankCard set CardPwd = @pwd where CardNo=@cardnoend3333end
go
declare @pwd nvarchar(20) = '123456'
exec procPwdUpgrade '6225547854125656',@pwd output
select @pwd
创建触发器
- inserted
- deleted
- insert into语句后,可以从inserted表查到添加的信息
- delete from语句之后,可以从deleted…
- update 之后,同时可以查inserted(新)和deleted(旧)
(1)假设有部门表和员工表,在添加员工的时候,该员工的部门编号如果在部门表中找不到,则自动添加部门信息,部门名称为"新部门"。
编写触发器:
create trigger tri_InsertPeople on People
after insert
as
declare @departId varchar(20)
set @departId = (select DepartmentId from inserted)if not exists(select * from Department where DepartmentId = @departId)insert into Department(DepartmentId,DepartmentName)values(@departId,'新部门')
go
测试触发器:
insert People(DepartmentId,PeopleName,PeopleSex,PeoplePhone)
values('009','赵云','男','13854587456')
我们会发现,当插入赵云这个员工的时候会自动向部门表中添加数据。
(2)触发器实现,删除一个部门的时候将部门下所有员工全部删除。
编写触发器:
create trigger tri_DeleteDept on Department
after delete
as
delete from People where People.DepartmentId =
(select DepartmentId from deleted)
go
测试触发器:
delete Department where DepartmentId = '001'
我们会发现当我们删除此部门的时候,同时会删除该部门下的所有员工
(3)创建一个触发器,删除一个部门的时候判断该部门下是否有员工,有则不删除,没有则删除。
编写触发器:
drop trigger tri_DeleteDept --删除掉之前的触发器,因为当前触发器也叫这个名字
create trigger tri_DeleteDept on Department
Instead of delete
asif not exists(select * from People where DepartmentId = (select DepartmentId from deleted))begindelete from Department where DepartmentId = (select DepartmentId from deleted)end
go
测试触发器:
delete Department where DepartmentId = '001'
delete Department where DepartmentId = '002'
delete Department where DepartmentId = '003'
我们会发现,当部门下没有员工的部门信息可以成功删除,而部门下有员工的部门并没有被删除。
(4)修改一个部门编号之后,将该部门下所有员工的部门编号同步进行修改
编写触发器:
create trigger tri_UpdateDept on Department
after update
asupdate People set DepartmentId = (select DepartmentId from inserted)where DepartmentId = (select DepartmentId from deleted)
go
测试触发器:
update Department set DepartmentId = 'zjb001' where DepartmentId='001'
我们会发现不但部门信息表中的部门编号进行了修改,员工信息表中部门编号为001的信息也被一起修改了。
3.各种查询操作(3个)
- top
- distinct
- like
- in
- between
查询
=:等于,比较是否相等及赋值
!=:比较不等于 <>
>:比较大于
<:比较小于
>=:比较大于等于
<=:比较小于等于
IS NULL:比较为空
IS NOT NULL:比较不为空
in:比较是否在其中 in (select ...)
like:模糊查询 like 'computer%'
BETWEEN...AND...:比较是否在两者之间
and:逻辑与(两个条件同时成立表达式成立)
or:逻辑或(两个条件有一个成立表达式成立)
not:逻辑非(条件成立,表达式则不成立;条件不成立,表达式则成立)
(10)查询工资最高的5个人的信息
select top 5 * from People order by PeopleSalary desc
(11)查询工资最高的10%的员工信息
select top 10 percent * from People order by PeopleSalary desc
(12)查询出地址没有填写的员工信息
select * from People where PeopleAddress is null
(13)查询出地址已经填写的员工信息
select * from People where PeopleAddress is not null
模糊查询
%:代表匹配0个字符、1个字符或多个字符。
_:代表匹配有且只有1个字符。
[]:代表匹配范围内
[^]:代表匹配不在范围内
(4)查询姓刘的员工,名字是2个字
--方案一:
select * from People where PeopleName like '刘_'
--方案二:
select * from People where SUBSTRING(PeopleName,1,1) = '刘' and LEN(PeopleName) = 2
(6)查询出电话号码开头138的员工信息
select * from People where PeoplePhone like '138%'
(7)查询出电话号码开头138的员工信息,第4位可能是7,可能8 ,最后一个号码是5
select * from People where PeoplePhone like '138[7,8]%5'
(8)查询出电话号码开头133的员工信息,第4位是2-5之间的数字 ,最后一个号码不是2和3
--方案一:
select * from People where PeoplePhone like '133[2,3,4,5]%[^2,3]'
--方案二:
select * from People where PeoplePhone like '133[2-5]%[^2-3]'
聚合查询
-
只有count是对行的累加计数,其他聚合函数都是对某一列的计算
-
只有count不忽略null,其他都会忽略
-
聚合不应出现在 WHERE 子句中,除非该聚合位于 HAVING 子句或选择列表所包含的子查询中,并且要对其进行聚合的列是外部引用。

(6)求数量,最大值,最小值,总和,平均值,在一行显示
select COUNT(*) 数量,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资,SUM(PeopleSalary) 工资总和,AVG(PeopleSalary) 平均工资 from People
(7)查询出武汉地区的员工人数,总工资,最高工资,最低工资和平均工资
select '武汉' 地区,COUNT(*) 数量,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资
,SUM(PeopleSalary) 工资总和,AVG(PeopleSalary) 平均工资 from People
WHERE PEOPLEADDRESS = '武汉'
(8)求出工资比平均工资高的人员信息
declare @avgsalsary float
set @avgsalary = select AVG(PeopleSalary) 平均工资 from People
select * from People where PeopleSalary > @avgsalary and area in ('北京',‘上海’)
count中使用distinct去重,统计某一列上不同的值有几个
select count(distinct city) from authors
SELECT COUNT(DISTINCT C#) FROM SC
分组查询
为了保证完整性,系统约定俗成,在使用了聚合函数的查询语句中,除了聚合函数,可以在查询列表上,要出现其他字段,那么该字段就必须为分组字段,而且该字段一定要跟随在GROUP BY关键字后面。
与聚合函数一起出现在select后面进行查询的列,只有两种可能性:被聚合 、被分组
1)根据员工所在地区分组统计员工人数 ,员工工资总和 ,平均工资,最高工资和最低工资
select PeopleAddress 地区,COUNT(*) 人数,SUM(PeopleSalary) 工资总和,
AVG(PeopleSalary) 平均工资,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资
from People group by PeopleAddress
(2)根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资,1985 年及以后出身的员工不参与统计。
select PeopleAddress 地区,COUNT(*) 人数,SUM(PeopleSalary) 工资总和,
AVG(PeopleSalary) 平均工资,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资
from People
where PeopleBirth < '1985-1-1'
group by PeopleAddress
(3)根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资,要求筛选出员工人数至少在2人及以上的记录,并且1985年及以后出身的员工不参与统计。
select PeopleAddress 地区,COUNT(*) 人数,SUM(PeopleSalary) 工资总和,
AVG(PeopleSalary) 平均工资,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资
from People
where PeopleBirth < '1985-1-1'
group by PeopleAddress
having COUNT(*) >= 2
多表查询
-
inner join TABLE on … 如果两表信息条数不匹配,则只显示匹配的信息
-
left join TABLE on… 如果两表信息条数不匹配,显示左的信息然后右边不匹配的信息显示NULL
-
右外连接(right join):右外连接和左外连接类似,A left join B == B right join A
全外连接(full join):两张表的所有数据无论是否符合主外键关系必须全部显示,不符合主外键关系的地方null取代。
-
where … in (select … where …) 只能显示主表数据,类似left join
-
from TABLE1,TABL2 where … = , , … = , 不推荐,笛卡尔积消耗内存

查询出没有转账交易记录的银行卡账户信息,显示卡号,身份证,姓名,余额。
select CardNo 卡号,AccountCode 身份证,RealName 姓名,CardMoney 余额 from BankCard
left join AccountInfo on BankCard.AccountId = AccountInfo.AccountId
where BankCard.CardNo not in (select CardNoIn from CardTransfer)
and BankCard.CardNo not in (select CardNoOut from CardTransfer)select CardNo 卡号,AccountCode 身份证,RealName 姓名,CardMoney 余额 from BankCard 2left join AccountInfo on BankCard.AccountId = AccountInfo.AccountId3where CardNo not in4(select CardNo from CardExchange where MoneyInBank <> 0)select DepartmentName 部门名称,COUNT(*) 人数,SUM(PeopleSalary) 工资总和,
AVG(PeopleSalary) 平均工资,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资
from People left join DEPARTMENT on Department.DepartmentId = People.DepartmentId
group by Department.DepartmentId,DepartmentName
having AVG(PeopleSalary) >= 10000
order by AVG(PeopleSalary) desc
带循环、分支判断的查询
- convert(类型,变量)
if exists(select * from CardTransfer where CardNoIn = '6225547858741263'
and convert(varchar(10),TransferTime, 120) = convert(varchar(10),getdate(), 120)
)print '有转账记录'
elseprint '没有转账记录'
declare @AccountId int
declare @count int
if exists(select * from AccountInfo where AccountCode = '420107199507104133')begin select @AccountId = (select AccountId from AccountInfo where AccountCode = '420107199507104133')select @count = (select COUNT(*) from BankCard where AccountId = @AccountId)if @count <= 2begininsert into BankCard(CardNo,AccountId,CardPwd,CardMoney,CardState)values('6225456875357898',@AccountId,'123456',0,1) end elsebeginprint '一个人最多只能办理三张银行卡'end end
elsebegininsert into AccountInfo(AccountCode,AccountPhone,RealName,OpenTime)values('420107199507104133','13335645213','关羽',GETDATE())set @AccountId = @@identityinsert into BankCard(CardNo,AccountId,CardPwd,CardMoney,CardState)values('6225456875357898',@AccountId,'123456',0,1) end
declare @i int = 1
declare @str varchar(1000)
while @i<=9
begindeclare @j int = 1set @str = ''while @j <= @ibegin--方案二set @str = @str + Convert(varchar(2),@i) + '*' + Convert(varchar(2),@j) + '=' + Convert(varchar(2),@i*@j) + CHAR(9) --char(9)制表符; set @j = @j + 1endprint @strset @i = @i + 1
end
带变量的查询
- 声明变量和赋值
declare @a int
declare @b char(10)
declare @c varchar(20)
declare @d nvarchar(20)
declare @e money-------------------------
set @a = 1
set @b = 'abcdefghi'
select @c = (select top 1 name from People where id = '8204200213') -- 如果查询出多条则赋值最后一条
declare @gyBalance money
select @gyBalance = (select CardMoney from BankCard where CardNo='6225547858741263')
select CardNo 卡号,AccountCode 身份证,RealName 姓名,CardMoney 余额 from BankCard
left join AccountInfo on BankCard.AccountId = AccountInfo.AccountId
where CardMoney > @gyBalance
简答题部分(25,4个)
- 数据库发展史(现阶段与之前对比)
- 三级结构、两级独立性
三级结构:用户层、概念层、物理层;外模式、概念模式、内模式
两级独立性:物理独立性、逻辑独立性
分级好处:实现数据独立性;数据共享;便于用户操作;安全性
- 三个世界
现实世界-实际存在【用户级】
信息世界–抽象加工(不同人不一样,取决于设计者的看法)【概念级】
机器世界-实际存在0101【物理级】
- 规范化的原因
数据冗余;插入异常;删除异常;修改异常
- 函数依赖有什么,函数范式有什么
平凡、非平凡;完全、部分;传递
第一范式:必须满足,所有属性都不可分
第二范式:第一范式的基础上,所有非主属性完全依赖于主属性
第三范式:第二范式的基础上,所有非主属性不传递依赖主属性
- 数据库完整性、约束性条件
域完整性:列的值是有效的,check约束、null、default
实体完整性:行的标识是唯一的,唯一主键
参考(引用)完整性:表之间的关系是完整的,外键
用户自定义完整性:自定义规则,触发器、过程
- 视图的定义和优点,修改视图的限制
定义:视图是用户级的虚拟表,其内容取决于定义时的查询操作。视图不是一个物理存放的表,当用户对视图查询时,本质上执行的是创建视图时的select语句。
优点:利于用户的个性化推荐,用户只需查找视图即可;安全性,限制了用户的权限,用户不能对基表操作;隔离变化,用户眼中的视图是不变的,其基表是可以动态变化的。
限制:不能同时修改基表的两个列;添加行是应该满足数据的合理性(null、default等);视图中的列的数据符合基表的数据完整性约束,对视图中列的修改也要符合基表中的约束;某些列不能修改,如计算列、聚合函数列等。
- 索引的概念和优点、缺点
概念:索引是为了方便查询而建立在一张表或一个视图的列集合上的,优点是加速查询、优化分组和排序等操作,缺点是占用额外的空间存放索引、需要创建时间、修改数据时间长。
- 簇索引和非簇索引的应用
簇索引:叶子结点存放数据本身, 一个表只能建立一个,适合分组和区间查询的情况。
非簇索引:叶子节点存放数据的指针,一个表可以建立多个非簇索引。
-
可靠性、安全性(必考其一) 如何实现
-
备份有几种方式,差异是什么
完整数据库备份
差异备份:备份自上一次完整数据库备份后修改过的数据库页。
事务日志备份:仅备份事务日志。事务日志是自上次备份后(不论这个备份是完全备份、差异备份还是事务日志备份)对数据库执行的所有事务的备份。可以使用事务日志备份将数据库恢复到特定的即时点。
文件或文件组备份:仅备份数据库中某个文件或文件组,用于恢复位于故障磁盘上的那部分,用于超大型数据库,不同时间备份不同的部分。
- 并发控制造成什么,怎么做,死锁
并发操作带来的数据不一致性:
丢失修改(lost update)
不可重复读(non-repeatable read)
读“脏”数据(dirty read)
锁是数据库中用来处理并发的一种对象,它允许事务用一定的方法锁定所需要的资源
- 安全性不同的level
选择
sql的 组成:DDL、DML、DCL
数据对象的定义语句:创建是create、修改是alter不是update、删除是drop不是delete
delete 是DML,打标签而不真正释放空间,触发器
drop和truncate是DDL,直接释放空间
本质区别 :DDL代表数据定义语言,是一种有助于创建数据库模式的SQL命令。而,DML代表数据操作语言,是一种有助于检索和管理关系数据库中数据的SQL命令。
命令上的区别:DDL中常用的命令有:create,drop,alter,truncate和rename等等。而,DML中常用的命令有:insert,update,delete和select等等。
志备份将数据库恢复到特定的即时点。
文件或文件组备份:仅备份数据库中某个文件或文件组,用于恢复位于故障磁盘上的那部分,用于超大型数据库,不同时间备份不同的部分。
- 并发控制造成什么,怎么做,死锁
并发操作带来的数据不一致性:
丢失修改(lost update)
不可重复读(non-repeatable read)
读“脏”数据(dirty read)
锁是数据库中用来处理并发的一种对象,它允许事务用一定的方法锁定所需要的资源
- 安全性不同的level
选择
sql的 组成:DDL、DML、DCL
数据对象的定义语句:创建是create、修改是alter不是update、删除是drop不是delete
delete 是DML,打标签而不真正释放空间,触发器
drop和truncate是DDL,直接释放空间
本质区别 :DDL代表数据定义语言,是一种有助于创建数据库模式的SQL命令。而,DML代表数据操作语言,是一种有助于检索和管理关系数据库中数据的SQL命令。
命令上的区别:DDL中常用的命令有:create,drop,alter,truncate和rename等等。而,DML中常用的命令有:insert,update,delete和select等等。
[外链图片转存中…(img-ifGnVVnh-1714924159510)]
影响上的区别:DDL命令会影响整个数据库或表,但DML命令会影响表中的一个或多个记录。
这篇关于数据库期末复习资料的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





