本文主要是介绍2024数维杯B题完整思路24页+配套代码1-4问+可视化结果图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
后续参考论文也会进行一个更新
2024年数维杯数学建模B题主要关注生物质和煤共热解问题的研究
点击链接加入群聊【2024数维杯数学建模ABC题资料汇总】:
2024数维杯B题完整思路18页+1-5问配套代码+后续参考论文![]() https://www.jdmm.cc/file/2710636
https://www.jdmm.cc/file/2710636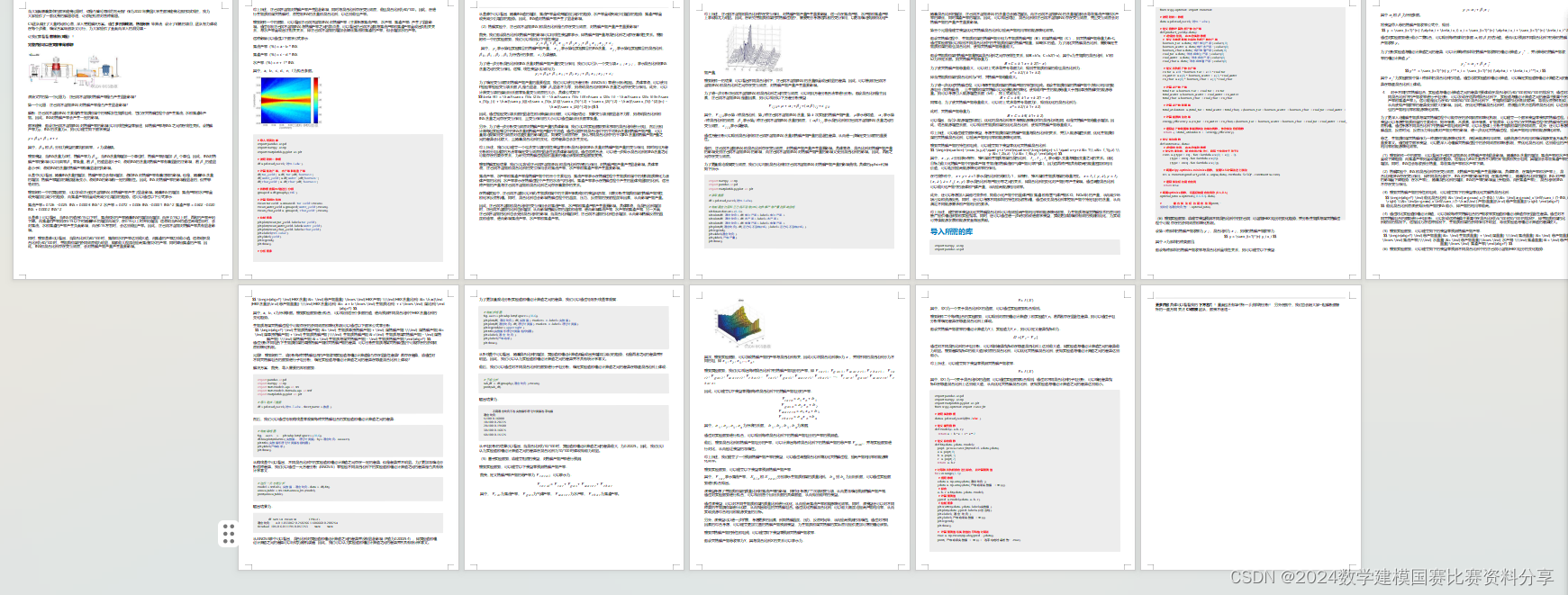

该段文字的第一个问题为:正己烷不溶物对热解产率是否产生显著影响? 第一个问题:正己烷不溶物(INS)对热解产率是否产生显著影响?
解析:正己烷不溶物(INS)主要是由生物质和煤中的非挥发性物质组成,它们在共热解过程中会产生焦油、水和焦渣等产 物。因此,INS对热解产率会产生一定的影响。
数学建模:假设正己烷不溶物(INS)对热解产率的影响可以用线性模型来描述,即热解产率与INS之间存在线性关系。设热解 产率为y,INS的含量为x,则可以建立如下数学模型:
y = β 0 + β 1 x + ε
其中, β 0 和 β 1 分别为模型的截距和斜率, ε 为误差项。
根据模型,当INS含量为0时,热解产率为 β 0 ,当INS含量每增加一个单位时,热解产率会增加 β 1 个单位。因此,INS对热解产率的影响可以用斜率 β 1 来衡量,若 β 1 的值显著大于0,说明INS的含量对热解产率有着显著的正影响;若 β 1 的值显著小于0,说明INS的含量对热解产率有着显著的负影响。
从图中可以看出,随着INS含量的增加,热解产率也会有所增加,说明INS对热解产率有着正向的影响。但是,随着INS含量 的增加,热解产率增加的幅度逐渐变小,说明INS的影响有一定的限制性。因此,INS对热解产率的影响是显著的,但并非 绝对的。
根据附件一中的实验数据,可以发现正己烷不溶物(INS)对热解产率产生了显著影响。随着INS的增加,焦油产率和水产率呈 现先增加后减少的趋势,而焦渣产率则呈现先减少后增加的趋势。这可以通过以下公式表示:
焦油产率 = 0.126 - 0.025 INS + 0.0003 INS^2 水产率 = 0.072 + 0.006 INS - 0.0001 INS^2 焦渣产率 = 0.802 - 0.020 INS + 0.0002 INS^2
从图像上可以看出,当INS的值在0.15以下时,焦油和水的产率随着INS的增加而增加,而在0.15以上时,两者的产率开始 下降。而焦渣的产率则在0.15以下时随着INS的增加而减少,在0.15以上时开始增加。这说明当INS的值过高或过低时,会 对焦油、水和焦渣的产率产生负面影响,而在0.15左右时,会达到最佳产率。因此,正己烷不溶物对热解产率具有显著影 响。
同时,根据图像可以看出,当混合比例为30/100时,焦油和水的产率达到最大值,而焦渣的产率达到最小值。这说明在混 合比例为30/100时,生物质和煤的协同效应最为明显,能够最大程度地提高焦油和水的产率,同时降低焦渣的产率。因 此,INS和混合比例存在交互效应,会对热解产物产量产生重要影响。
综上所述,正己烷不溶物对热解产率产生显著影响,同时与混合比例存在交互效应,最佳混合比例为30/100。因此,在进 行生物质和煤共热解时,应控制INS的含量和混合比例,以达到最佳产率。
根据附件一中的数据,可以看出正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)产生了显著影 响。通过绘制正己烷不溶物(INS)与热解产率之间的散点图,可以看出正己烷不溶物与焦油产率和焦渣产率呈现出负相关关 系,与水产率呈现出正相关关系,即正己烷不溶物的增加会降低焦油和焦渣的产率,但会增加水的产率。
这种影响可以通过以下数学公式表示: 焦油产率(%) = a - b * INS
焦渣产率(%) = c - d * INS 水产率(%) = e + f * INS
其中,a、b、c、d、e、f为拟合参数。
分析正己烷不溶物(INS)对热解产率的影响
方法:使用方差分析(ANOVA)来确定不同INS含量对热解产率(焦油产率、水产率、焦渣产率)是否有显著影响。
图像解释:绘制条形图或箱线图来可视化不同INS含量下的热解产率,并用图形表示统计显著性。
(2)正己烷不溶物(INS)和混合比例的交互效应
方法:同样使用方差分析(ANOVA),但这次是二因素方差分析,以检验INS含量和混合比例之间的交互效应。
交互效应的识别:通过分析交互作用项的显著性,确定在哪些热解产物上样品重量和混合比例的交互效应最为明显。
(3)优化共热解混合比例
方法:可以使用多目标优化算法,如遗传算法或多目标遗传算法(MOGA),来找到最优的混合比例,以最大化产物利用率和能源转化效率。
模型建立:基于实验数据建立一个或多个目标函数,如总热解产率、特定产物产率等。
(4)产物收率实验值与理论计算值的比较
方法:使用配对t检验来比较每种共热解组合的产物收率实验值与理论计算值。
子组分析:对存在显著性差异的组合,进一步分析不同混合比例下的差异,以确定差异的具体来源。
(5)建立热解产物产率预测模型
方法:可以使用回归分析来建立预测模型。考虑到可能存在非线性关系,可以使用多项式回归、支持向量回归(SVR)或随机森林等机器学习方法。
模型选择:基于模型的预测性能(如R²、均方误差MSE等指标)选择最佳模型。
实施步骤
数据整理:首先需要整理和分析附件1和附件2中的实验数据。
统计分析:对数据进行描述性统计分析,包括计算平均值、标准差等。
方差分析:执行ANOVA分析以确定显著性影响因素。
交互效应分析:进行二因素方差分析,识别交互效应。
优化模型:建立并求解多目标优化问题。
差异分析:对实验值与理论计算值进行比较分析。
预测模型:选择合适的统计或机器学习方法建立预测模型。
模型验证:使用交叉验证等方法验证模型的预测性能。
问题一
1. 数据整理
首先,我们需要整理实验数据,确保每个实验条件下的热解产率数据(焦油产率、水产率、焦渣产率)和对应的正己烷不溶物(INS)含量都是可用的。
2. 描述性统计
对每个热解产率指标进行描述性统计分析,计算其在不同INS含量下的平均值、中位数、标准差等统计量。
3. 方差分析 (ANOVA)
方差分析是一种用来分析数据中变量间是否存在显著性差异的统计方法。这里我们关注的是正己烷不溶物(INS)含量对热解产率的影响,因此可以使用单因素方差分析。
单因素方差分析的基本步骤:
- 计算组间和组内平方和:组间平方和(SSB)表示不同INS含量组之间的变异,组内平方和(SSW)表示组内个体之间的变异。
- 计算组间和组内均方:均方是平方和除以其自由度。
- 计算F统计量:F统计量是组间均方与组内均方的比值,用于测试组间差异的显著性。
4. 显著性检验
通过比较计算得到的F统计量与F分布的临界值(或使用p值),来判断正己烷不溶物(INS)含量对热解产率是否有显著影响。
5. 图形表示
使用条形图或箱线图来可视化不同INS含量下的热解产率。在条形图中,每个条形代表一个INS含量组的热解产率的平均值,条形的长度表示平均值的大小,误差线表示标准差。在箱线图中,箱子表示数据的四分位数,中间的线条表示中位数,箱子外的“须”表示最小值和最大值(除去异常值)。
6. 结论
根据方差分析的结果和图形表示,我们可以得出结论,说明正己烷不溶物(INS)对热解产率是否有显著影响。
问题二
1. 数据整理
确保实验数据包括两个因素:正己烷不溶物(INS)含量和混合比例,以及它们对热解产物产量的影响。
2. 二因素方差分析
二因素方差分析用于检验两个分类自变量的主效应以及它们之间的交互效应对观测数据平均值的影响。
二因素方差分析的基本步骤:
- 计算总变异:总平方和(SST)表示所有观测值与其总平均值之间的差异。
- 计算因素A的主效应:A因素的平方和(SSA)表示因素A不同水平之间的差异。
- 计算因素B的主效应:B因素的平方和(SSB)表示因素B不同水平之间的差异。
- 计算A和B的交互效应:交互项的平方和(SSAB)表示因素A和B相互作用的差异。
- 计算组内变异:组内平方和(SSW)表示所有组内个体与其组平均值之间的差异。
- 计算均方和F统计量:均方是平方和除以其自由度,F统计量是均方除以组内均方
3. 显著性检验
通过比较计算得到的F统计量与F分布的临界值(或使用p值),判断因素A、因素B以及它们的交互作用是否对热解产物产量有显著影响。
4. 图形表示
使用交互作用图来可视化因素A、因素B以及它们的交互效应对热解产物产量的影响。这种图形可以是三维条形图或等高线图,其中两个轴分别代表两个因素的水平,第三个轴代表热解产物产量。
5. 结论
根据二因素方差分析的结果和图形表示,我们可以得出结论,说明正己烷不溶物(INS)含量和混合比例是否存在交互效应,以及这种交互效应在哪些热解产物上最为明显。
问题三
1. 确定优化目标
首先,需要明确优化的目标,这可能包括但不限于:
- 最大化热解油产率
- 最小化焦渣产率
- 最大化能源转化效率
3. 建立约束条件
在优化过程中,可能需要考虑以下约束条件:
- 原料的混合比例限制
- 热解温度和时间的限制
- 设备的工作条件限制
4. 多目标优化
由于我们通常有多个优化目标,可以使用多目标优化算法来寻找最优解。常见的多目标优化算法包括:
- 遗传算法
- 多目标遗传算法
- 粒子群优化
5. 优化算法的实现
以多目标遗传算法为例,其基本步骤包括:
- 初始化种群:生成一组随机解作为初始种群。
- 适应度评估:计算每个个体的适应度,即目标函数值。
- 选择操作:根据适应度选择个体进行繁殖。
- 交叉操作:通过交叉操作产生新的个体。
- 变异操作:对个体进行变异以保持种群的多样性。
- 新一代种群:根据上述步骤生成新的种群。
- 终止条件:若达到预设的迭代次数或解的质量满足要求,则停止算法。
6. 结果分析
优化算法运行结束后,我们可以得到一个解集,前沿。这个前沿上的解在多个目标之间提供了不同的权衡。我们可以根据实际情况选择最合适的解。
7. 验证和调整
最后,需要通过实验验证所得到的最优混合比例是否真正提高了产物利用率和能源转化效率。根据实验结果,可能需要对模型进行调整和优化。
问题四
1. 数据整理
确保每个共热解组合都有对应的实验值和理论计算值。
2. 配对样本t检验
配对样本t检验用于比较两个相关样本均值的差异是否显著。在本问题中,两个相关样本是实验值(X)和理论计算值(Y)。
5. 结果分析
根据t检验的结果和效应量,我们可以得出结论,说明实验值和理论计算值之间是否存在显著性差异,以及这种差异的实际重要性。
6. 子组分析
如果发现显著性差异,可以进一步对不同共热解组合的数据进行子组分析,以确定差异在哪些混合比例上体现。这可以通过分别对每个混合比例的实验值和理论计算值进行配对样本t检验来实现。
注意事项
- 在进行t检验之前,需要检查数据是否满足正态分布的假设。如果不满足,可能需要使用非参数的检验方法,如Wilcoxon符号秩检验。
- 配对样本t检验适用于样本量较小的情况。如果样本量较大,可以使用z检验代替t检验。
- 显著性检验只能说明是否存在统计学上的显著差异,不能说明差异的实际重要性,因此效应量是一个重要的补充。
思路二:
2024年数维杯数学建模B题主要关注生物质和煤共热解问题的研究。题目要求参赛者通过数学建模来分析和预测共热解过程中产物的产率和品质,以及优化共热解的混合比例。以下是针对每个小问的解题思路:
(1)分析正己烷不溶物(INS)对热解产率的影响
- 解题思路:
- 从附件一的数据中提取正己烷不溶物(INS)的数值。
- 分析INS与焦油产率、水产率、焦渣产率之间的相关性。
- 利用统计分析方法(如回归分析)来确定INS对产率的影响是否显著。
- 通过绘制散点图或箱线图等可视化手段来展示INS与产率之间的关系。
(2)分析正己烷不溶物(INS)和混合比例的交互效应
- 解题思路:
- 确定混合比例的不同等级(如5/100, 10/100, ..., 50/100)。
- 分析在不同混合比例下,INS对热解产物产量的影响是否有变化。
- 使用方差分析(ANOVA)等方法来检验交互效应的存在及其显著性。
- 如果存在交互效应,进一步分析在哪些热解产物上这种效应最为明显。
(3)建立模型优化共热解混合比例
- 解题思路:
- 根据附件一的数据,分析不同混合比例对共热解产物特性和组成的影响。
- 建立数学模型(如线性规划、动态规划或非线性优化模型)来最大化产物利用率和能源转化效率。
- 使用优化算法(如梯度下降、遗传算法等)来求解模型,找到最优的混合比例。
(4)分析产物收率实验值与理论计算值的差异
- 解题思路:
- 比较附件二中提供的每种共热解组合的产物收率实验值与理论计算值。
- 使用假设检验(如t检验)来分析实验值与理论值之间是否存在显著性差异。
- 如果存在差异,通过子组分析确定差异在哪些混合比例上体现得最为明显。
(5)建立模型预测热解产物产率
- 解题思路:
- 利用附件一的实验数据,选择合适的预测模型(如时间序列分析、机器学习模型等)。
- 对模型进行训练和验证,确保其预测准确性。
- 使用训练好的模型来预测不同条件下的热解产物产率。
在解题过程中,需要注意以下几点:
- 数据预处理:对数据进行清洗,处理缺失值和异常值。
- 模型选择:根据问题特性和数据特点选择合适的数学模型和算法。
- 结果验证:通过交叉验证等方法确保模型的泛化能力。
- 报告撰写:清晰地展示解题过程、模型假设、求解步骤和结果分析
这篇关于2024数维杯B题完整思路24页+配套代码1-4问+可视化结果图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






