本文主要是介绍数据库(MySQL)—— 索引,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据库(MySQL)—— 索引
- 什么是索引
- 创建索引
- 使用 `CREATE INDEX` 语句
- 使用 `ALTER TABLE` 语句
- 在创建表时定义索引
- 特殊类型索引
- 注意事项
- 举个例子
- 无索引的情况
- 有索引的情况
- 为什么索引快
- 索引的结构
今天我们来看看MySQL中的索引:
什么是索引
MySQL中的索引是一种数据结构,主要用于提高数据库查询效率。它类似于书籍的目录,让你能够快速找到所需内容而无需逐页浏览整本书。在数据库中,索引使得MySQL能够快速定位到表中特定数据行的位置,从而加速数据检索过程。
以下是关于MySQL索引的一些关键点:
- 数据结构:最常见的索引类型是B-Tree索引,它利用了平衡树的数据结构,保持数据排序,便于执行范围查询和排序操作。此外,还有哈希索引、全文索引等其他类型,分别适用于不同的查询需求。
- 存储位置:索引存储在数据库表的一个独立的结构中,不与实际数据混在一起。对于InnoDB存储引擎,聚簇索引(Clustered Index)会直接存储数据在叶子节点,而非聚簇索引(Secondary Index)则存储指向聚簇索引的指针。
- 提高查询速度:当执行查询时,数据库系统首先查看索引,直接定位到数据行,而不是遍历整个表,显著减少了查询时间,特别是在处理大数据量时。
- 索引选择:不是所有列都适合创建索引,一般在以下情况考虑创建索引:频繁作为查询条件的列、经常需要排序或分组的列、用于连接操作的列。但同时要注意,索引也会占用存储空间,并可能降低写入(插入、更新、删除)操作的性能,因为每次数据变更都需要同步更新索引。
- 复合索引:当一个索引包含多个列时,称为复合索引或多列索引。在复合索引中,最左侧原则是一个重要概念,即查询条件从索引的最左列开始进行匹配。但在MySQL 5.6及以上版本引入了索引下推功能,可以在一定程度上放宽这一限制。
- 管理索引:可以通过
CREATE INDEX语句创建索引,使用ALTER TABLE语句添加或删除索引,以及使用DROP INDEX语句来删除索引。
综上所述,MySQL索引是优化数据库性能的关键工具,合理设计和使用索引对于提升应用的响应速度至关重要。
创建索引
在MySQL中,创建索引可以通过几种方式来实现,具体取决于你的需求和所使用的SQL语句。下面是几种常见的创建索引的方法:
使用 CREATE INDEX 语句
这是创建索引的最基本方式,适用于已存在的表。基本语法如下:
CREATE INDEX index_name ON table_name(column_name(length));
index_name是你给索引指定的名字。table_name是你要在其上创建索引的表的名称。column_name是你想要索引的列名,可选的(length)指定索引的长度,仅对字符串类型列有效,可以减少索引大小但可能影响前缀匹配查询。
示例:
CREATE INDEX idx_lastname ON employees(lastname);
使用 ALTER TABLE 语句
如果你在创建表后想添加索引,也可以使用 ALTER TABLE 语句:
ALTER TABLE table_name ADD INDEX index_name(column_name);
或者,如果想创建唯一索引(不允许重复值):
ALTER TABLE table_name ADD UNIQUE INDEX index_name(column_name);
示例:
ALTER TABLE students ADD INDEX idx_email ON(email);
在创建表时定义索引
你也可以在创建表的同时定义索引:
CREATE TABLE table_name (column1 datatype,column2 datatype,...INDEX index_name(column_name),UNIQUE INDEX unique_index_name(column_name)
);
特殊类型索引
- 全文索引:适用于全文本搜索。
CREATE FULLTEXT INDEX ft_index ON articles(content);
- 空间索引:用于地理空间数据类型。
CREATE SPATIAL INDEX sp_index ON places(location);
注意事项
- 在创建索引之前,应评估索引对查询性能的提升以及对数据插入、更新和删除操作的影响。
- 避免对经常更新的列创建过多索引,因为这会增加维护索引的成本。
- 使用
EXPLAIN语句分析查询计划,以帮助决定最佳的索引策略。- 根据实际情况选择合适的索引类型,比如是否需要唯一索引、全文索引等。
通过上述方法,你可以根据数据库的具体需求灵活地创建不同类型的索引。
举个例子
我们创建一张表:
-- 学生表
CREATE TABLE stu(id int COMMENT '学生id',name varchar(10) COMMENT '姓名',tele_number varchar(11) COMMENT '电话号码'
)COMMENT '学生表';
我们插入一些数据:
-- 插入第一条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (1, '张三', '13800138000');-- 插入第二条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (2, '李四', '13912345678');-- 插入第三条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (3, '王五', '13777777777');-- 插入第四条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (4, '赵六', '13600000000');-- 插入第五条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (5, '陈七', '13555555555');-- 插入第六条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (6, '周八', '13411111111');-- 插入第七条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (7, '吴九', '13322222222');-- 插入第八条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (8, '郑十', '13233333333');-- 插入第九条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (9, '钱十一', '13144444444');-- 插入第十条学生记录
INSERT INTO stu (id, name, tele_number)
VALUES (10, '孙十二', '13055555555');
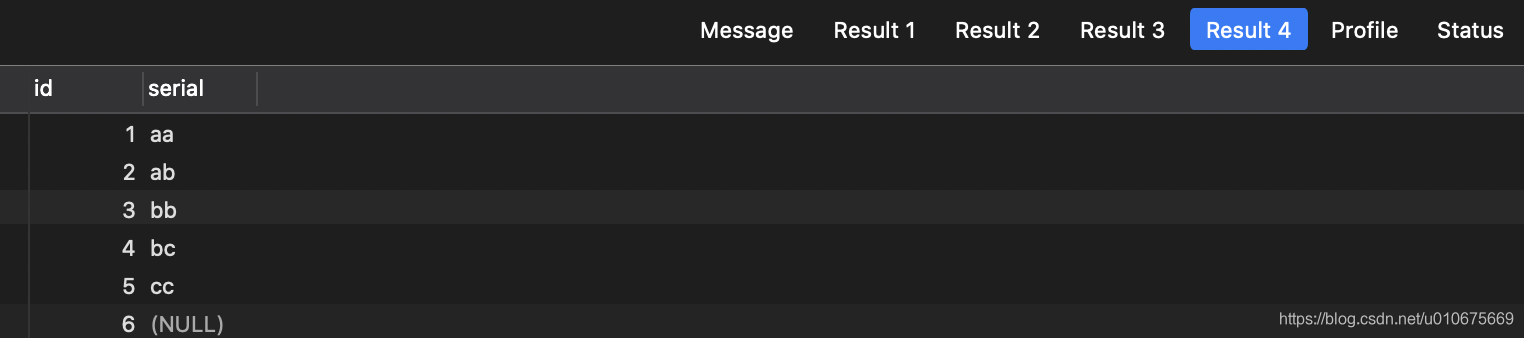
无索引的情况
我们执行下面的语句:
SET profiling = 1; -- 开启查询性能分析(MySQL特有)
SELECT SQL_NO_CACHE * FROM stu WHERE tele_number = '13800138000';
SHOW PROFILES; -- 显示最近的查询性能分析结果
找到下面的这条:
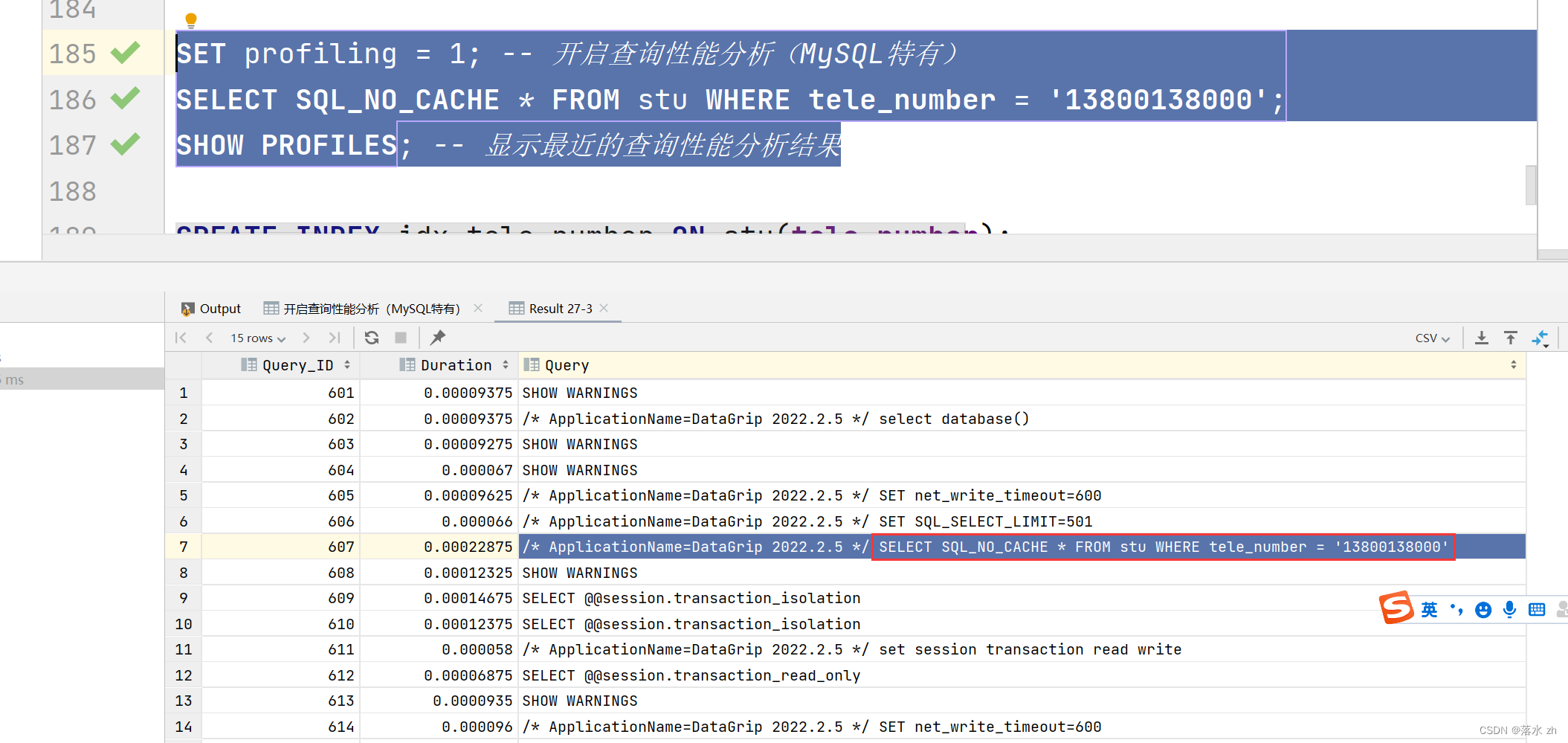
前面的时间就是执行查询语句的时间,我们看到时间是0.00022875秒。
当然,如果我们重复执行,每一次的时间都不一样,这个很正常。
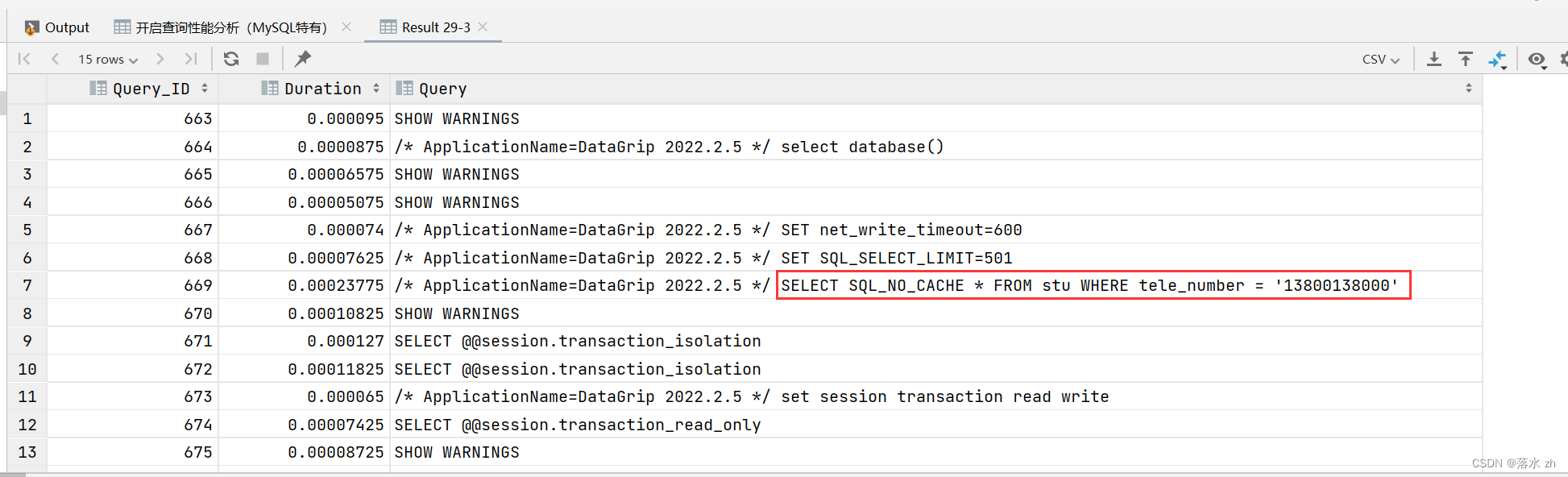 这次是0.00023775。
这次是0.00023775。
有索引的情况
我们对stu的tele_num创建索引:
CREATE INDEX idx_tele_number ON stu(tele_number);
然后,再执行上面的三句话:
SET profiling = 1; -- 开启查询性能分析(MySQL特有)
SELECT SQL_NO_CACHE * FROM stu WHERE tele_number = '13800138000';
SHOW PROFILES; -- 显示最近的查询性能分析结果
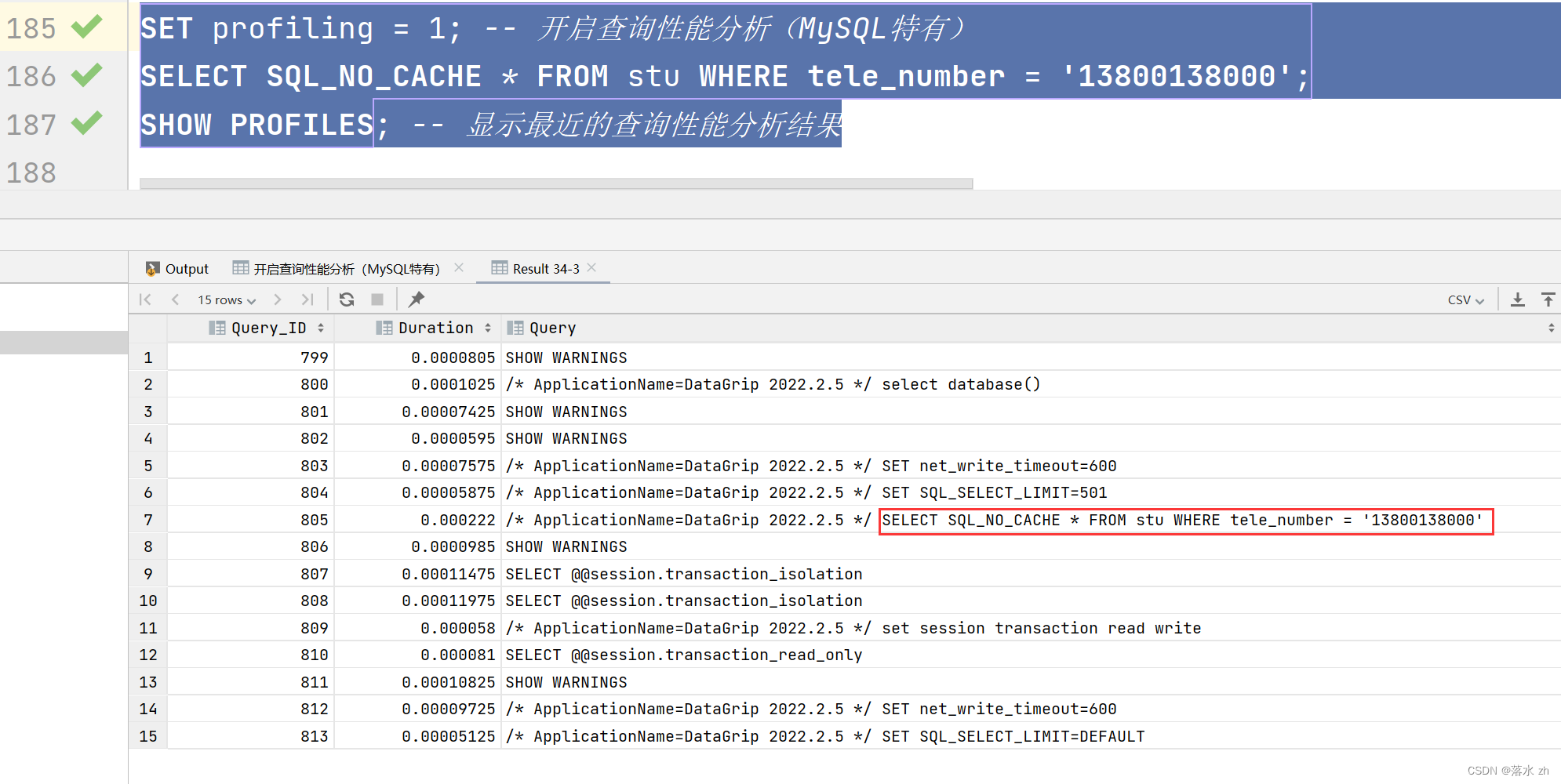
时间是0.000222,唉,时间好像没有节省很多哎。这里我们的数据比较少,看不出什么区别,如果数据量一旦很大,就可以看出索引的厉害了。
其实,索引的本质就是空间换时间,索引本身会占空间,但是通过索引我们可以提高检索速度。
为什么索引快
索引之所以快,是因为索引创建之后,数据的排序结构发生了变化(变成了索引结构)。
如果没有索引,MySQL会进行全表查找:
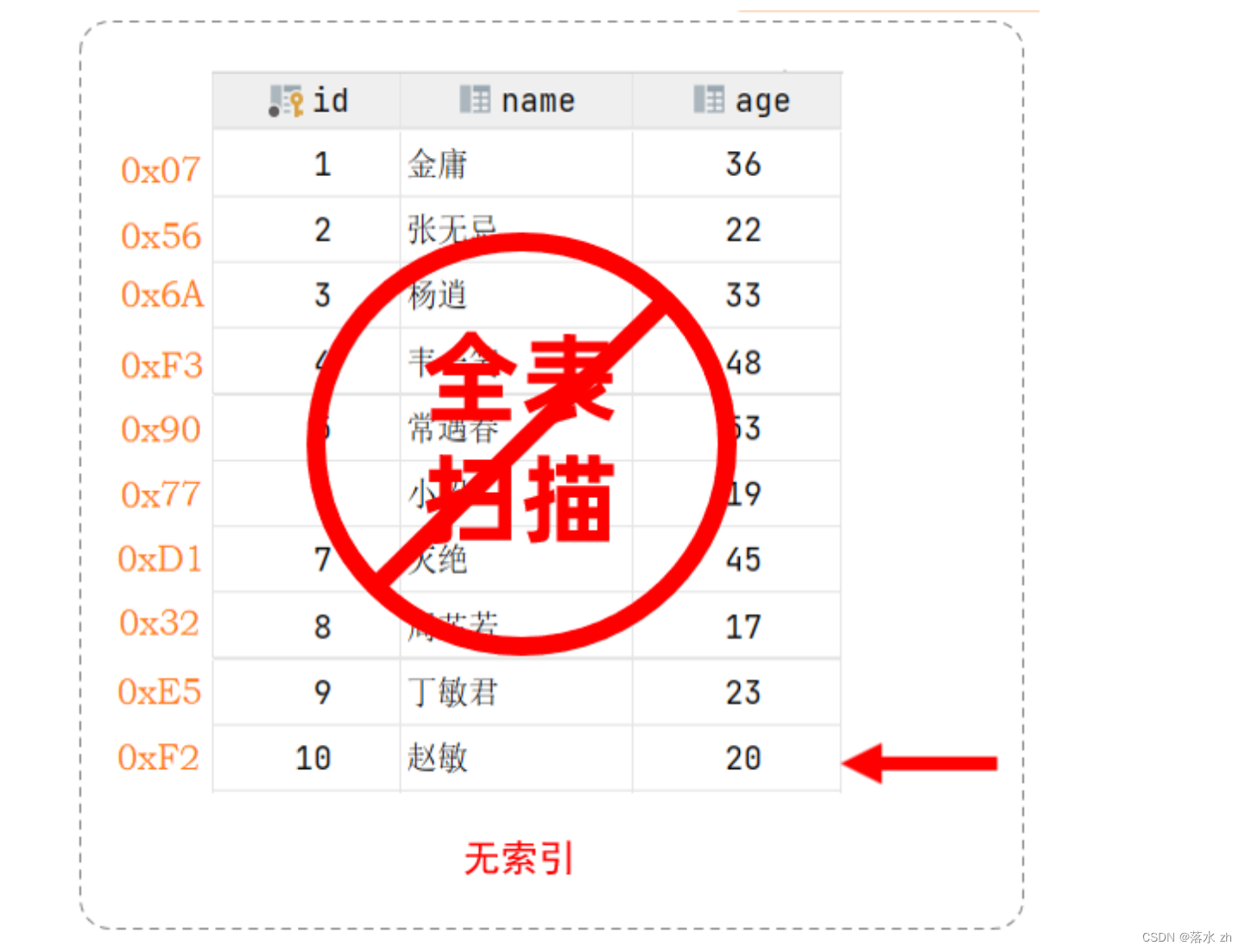 在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为 全表扫描,性能很低。
在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为 全表扫描,性能很低。
但是如果我们创建了索引,数据的排序结构就发生变化,比如变成二叉树:
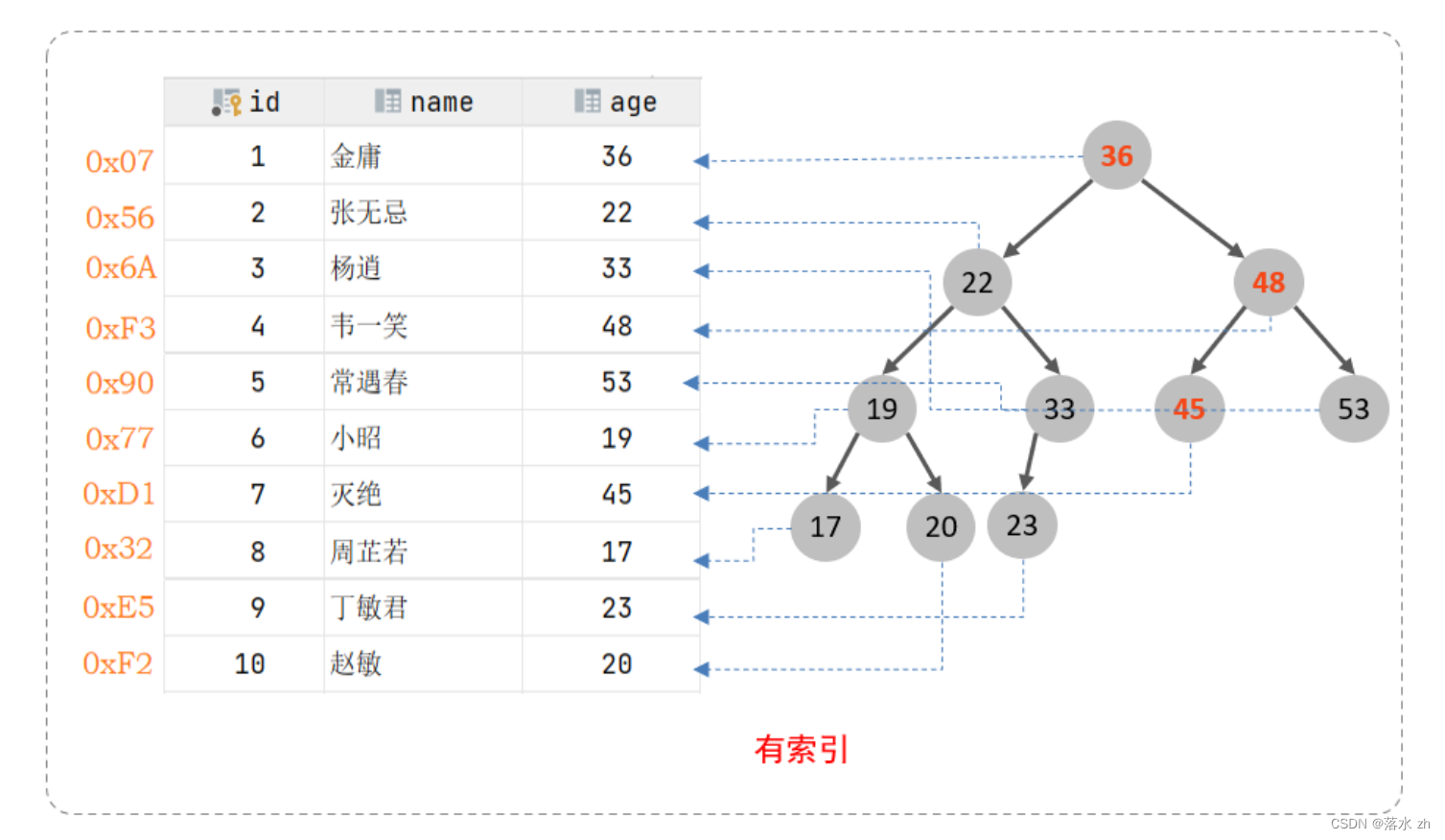
此时我们在进行查询时,极大的提高的查询的效率。
索引的结构
索引的底层结构会有这几种:
| 索引类型 | 结构描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,适用于大多数数据库引擎,如InnoDB。它通过层级的树状结构存储数据,每个节点可以包含多个键值对以及指向子节点的指针。叶子节点包含了实际的数据记录或数据记录的指针,并且叶子节点间通过指针相连,形成了一个有序链表,这有助于范围查询和排序操作。 |
| Hash索引 | 底层基于哈希表实现,适用于等值查询,特别是键值唯一或高度重复的情况。哈希索引通过计算索引列的哈希值并直接定位到对应的值或行,查询速度快。但由于哈希冲突的存在,它不支持范围查询,也无法用于排序或最左前缀匹配。 |
| R-tree索引(空间索引) | 一种特殊类型的索引,主要由MyISAM引擎支持,用于高效地存储和查询多维空间数据,如地理坐标。R-tree通过将多维空间划分为重叠的区域来组织数据,使得空间查询(如“附近的所有地点”)变得高效。 |
| Full-text索引(全文索引) | 专为文本内容设计的索引,能够支持复杂的文本搜索,包括词根搜索、同义词匹配等。它通过构建倒排索引来实现,即索引项是单词,而值是一系列包含该单词的文档位置。这种索引适用于大文本字段的模糊查询和全文搜索,常见于博客、文档数据库等应用场景。 |
这篇关于数据库(MySQL)—— 索引的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!