本文主要是介绍MybatisPlus 构造器wrapper的使用与原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
MyBatis缓存原理
Mybatis plugin 的使用及原理
MyBatis+Springboot 启动到SQL执行全流程
数据库操作不再困难,MyBatis动态Sql标签解析
Mybatis的CachingExecutor与二级缓存
使用MybatisPlus还是MyBaits ,开发者应该如何选择?

上一次我们给大家讲解了何为MybatisPlus,我们使用它的目的以及它的主要特性。不过,对于一线开发而言,如何在代码中使用上它的特性才是重中之重,本期我们就来好好讲一下 MybatisPlus 中的条件构造器
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 MyBatis专栏 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis kafka docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、构造器的分类
我们还是使用一张老图来说明
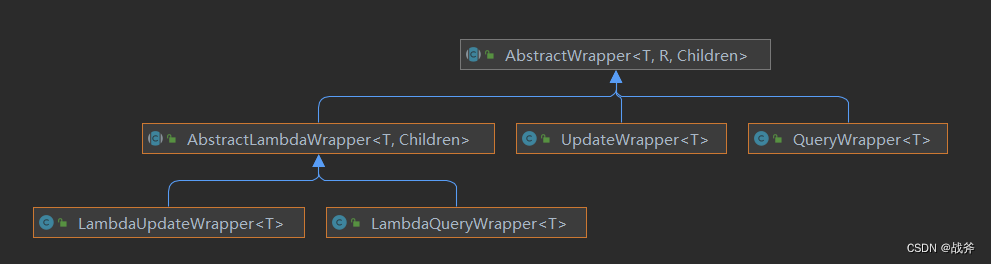
构造器都有一个核心父类= AbstractWrapper =,其他的构造器都是它的子类,现在两种分类方式,一种分类是用途;即查询 或 更新 构造器,另一种则是按使用方式,即一般 或 lambda 构造器。两种分类交错,最后我们就看到了四个构造器实现类。
1. AbstractWrapper 的作用
作为所有条件构造器的父类,AbstractWrapper 肩负着绝大部分的功能,来帮助我们实现各类复杂的SQL. 它实现了下面几个接口:
Compare:
-定义了一组方法用于比较操作,包括等于(eq)、不等于(ne)、大于(gt)Nested:
-定义了一组方法用于构建嵌套条件,即在查询条件中可以使用括号包裹的子条件Join:
-用于实现表的关联查询,通过指定关联条件、连接方式,可以将多个表的数据进行关联查询。Func:
-定义了一组方法用于构建SQL函数表达式,包括COUNT、SUM、AVG、MAX、MIN等函数
2. 普通构造器与lambda构造器
我们首先看带不带lambda有什么区别,其实两者几乎一致,我们以查询为例,也就是对比一下LambdaQueryWrapper和QueryWrapper ,不难发现,两者的差异重点是因为两人实现Query接口的定义不一样


普通的构造器实现query,定义了只能使用String,而Lambda构造器的入参则是允许是一个function函数。这样的区别,将导致两种不同的写法,见如下:
// 普通构造器QueryWrapper<CsdnUserInfo> wrapper = new QueryWrapper<>();wrapper.eq("is_delete", 0);wrapper.orderByDesc("user_weight");return this.list(wrapper);
// lambda构造器LambdaQueryWrapper<CsdnUserInfo> lambdaWrapper = new LambdaQueryWrapper<>();lambdaWrapper.eq(CsdnUserInfo::getIsDelete, 0);lambdaWrapper.orderByDesc(CsdnUserInfo::getUserWeight);return this.list(lambdaWrapper);
普通构造器在使用时,字段名只能直接写字符串,而lambda构造器只能写方法。因为直接写字符串出错了不容易发现,因此推荐大家还是尽量使用lambda构造器,以方便在编码阶段就减少错漏可能性
3. query构造器与update构造器
首先两者因为都继承了 AbstractWrapper 的,所以大部分的SQL功能两者是都具备的,比如SQL中where子句、join、排序那些东西。两者最大的区别是它们分别实现了两个不同的接口,一个继承Query,一个继承Update
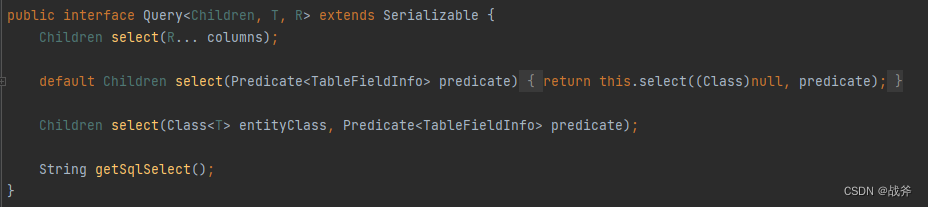
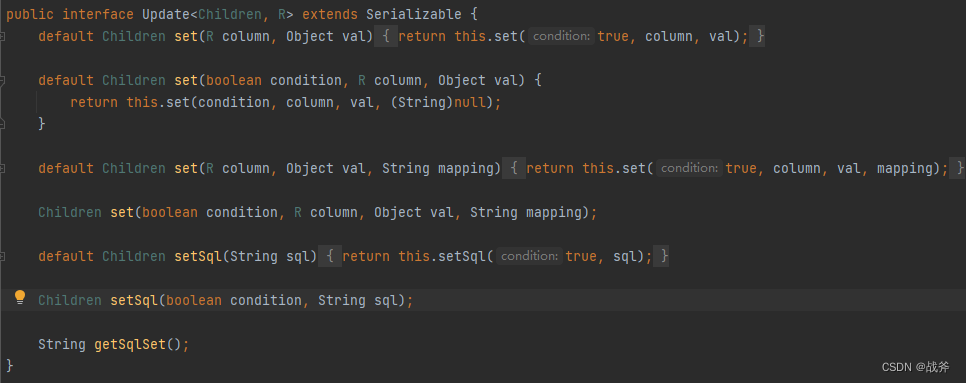
不难看出,两者核心的不同就是语法的区别,查询哪些字段或更新哪些字段
二、使用方式
关于构造器的基本方法,内容非常多,我们不再做搬运工,大家可以直接去下面的官网看方法的文档:条件构造器文档
1. 基础使用
我们以举例说明,比方说现在我们想要实现一个查询功能,根据以下条件来获取学生的信息:
性别为男性; 年龄在18到20岁之间; 成绩大于80分; 班级为A班,然后按成绩由高到底排
使用QueryWrapper来实现这个查询的代码如下
QueryWrapper<Student> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("gender", "男性").between("age", 18, 20).gt("score", 80).eq("class", "A班").orderByDesc("score");List<Student> students = studentMapper.selectList(queryWrapper);
又比如说 我们想将姓名为"张三"的学生年龄更新为20。则可以使用UpdateWrapper实现
String name = "张三";
Integer newAge = 20;UpdateWrapper<Student> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name", name).set("age", newAge);int result = studentMapper.update(null, updateWrapper);
2. 易错点-逻辑范围
由于条件构造器的语法非常符合自然语言,所以有的时候反而让人疏忽,我们仍举一个例子,比如我们想获取这样的用户
用户状态为有效的,名字为 张三 或 李四 或 王五 的用户
你可能想当然写成如下的样子
// 错误写法
Set<String> set = new HashSet<>();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");LambdaQueryWrapper<CsdnUserInfo> wrapper = new LambdaQueryWrapper<>();wrapper.eq(CsdnUserInfo::getIsDelete, 0);
for (String name : set) {wrapper.or(item -> item.eq(CsdnUserInfo::getUserName, name));
}
return this.list(wrapper);
但事实上,最终预编译产生的SQL是这样的:
SELECT id,user_name,nick_name,like_status,collect_status,comment_status,user_weight,user_home_url,curr_blog_url,article_type,create_time,update_time,is_delete FROM csdn_user_info WHERE (is_delete = ? OR (user_name = ?) OR (user_name = ?) OR (user_name = ?))
不难发现这样我们用户状态筛选 和 用户名筛选 用 or 关联起来了,这样其实就会查出所有有效的用户,不符合我们的预期。产生这种问题的原因,其实是少用了个括号。我们应该把用户名的 or 限制在一个括号内,不能让它扩散出去。
此时我们可以使用 nested 来修复这个问题,把我们的for循环扔进 nested 中
Set<String> set = new HashSet<>();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
wrapper.eq(CsdnUserInfo::getIsDelete, 0);
wrapper.nested(wp -> {for (String name : set) {wp.or(item -> item.eq(CsdnUserInfo::getUserName, name));}
});
return this.list(wrapper);
这样最后的编译的SQL是这样的
SELECT id,user_name,nick_name,like_status,collect_status,comment_status,user_weight,user_home_url,curr_blog_url,article_type,create_time,update_time,is_delete FROM csdn_user_info WHERE (is_delete = ? AND ((user_name = ?) OR (user_name = ?) OR (user_name = ?)))
3. 易错点-null处理
使用 MybatisPlus 还有一个坑点容易被忽略,那就是 null 值的处理,比如我们在插入或更新一条数据时,如果我们对象内某一个字段为null,这个null值可能不会插入或更新进表中。如果 null 在你的表中有业务意义,此刻就格外需要注意了。
比如我们想把张三的昵称置为空,写了这么一段代码
CsdnUserInfo user = new CsdnUserInfo();
user.setId(99999);
user.setUserName("张三");
user.setNickName(null);
csdnUserInfoService.updateById(user);
但我们的目的是不会生效的,因为此时 NickName 根本不会更新,它的SQL是这样的
UPDATE csdn_user_info SET user_name=? WHERE id=?
此时我们可以在实体类上加一个注解 @TableField(updateStrategy= FieldStrategy.IGNORED) 这是因为对字段的变更默认会有空值校验,只有显示的指定为 忽略校验 才能把空值更新进表中
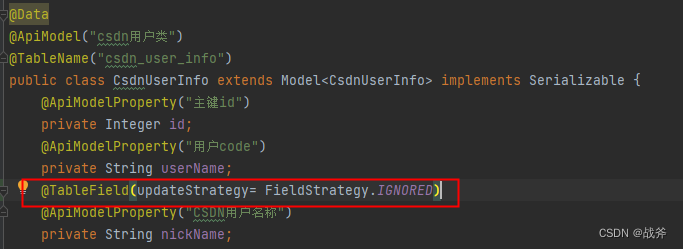
经过这样的改动,我们再来看看编译的SQL
UPDATE csdn_user_info SET user_name=?, nick_name=? WHERE id=?
nick_name 的 null 就可以成功更新进表中了。
三、生效原理
如果你看过我们之前的《MyBatis+Springboot 启动到SQL执行全流程》,就不难理解,我们其实可以把整个 MybatisPlus 分为项目启动阶段做的准备阶段,和真正要执行某段SQL的执行阶段。准备阶段就是把我们写在xml的SQL进行解析,构造出一个个映射声明(Mappedstatement),里面包含了我们的SQL主体。执行阶段则是通过方法全称找到自己的映射声明(Mappedstatement),对其进行拼接形成真正的可执行SQL。
那在MybatisPlus下,我们明明没写SQL,SQL又是从哪来的呢?
正如上面说的,比如一个简单的插入,我们没有写SQL,甚至连xml文件都没有,而是直接使用的BaseMapper 中的 insert 方法。
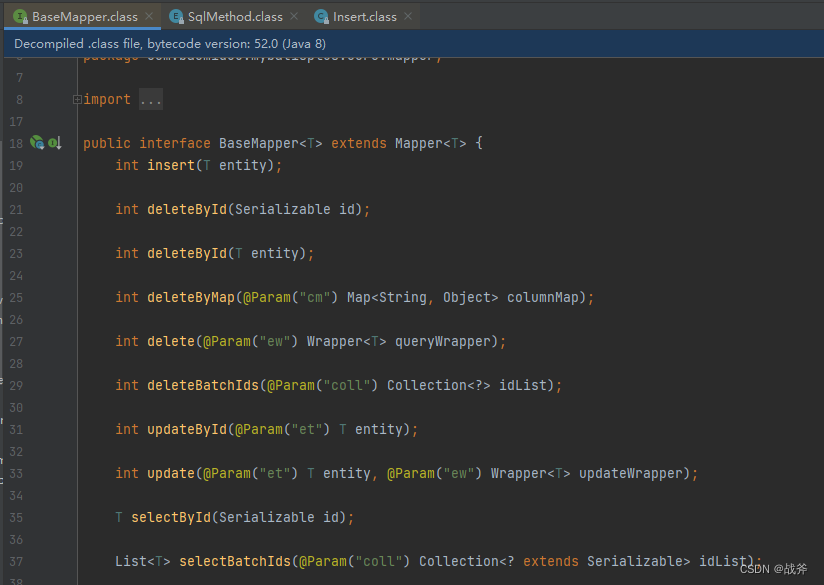
所以在启动的时候,如下面的 service其实就在做准备工作了,如果说我们以前的xml文件写了现成的SQL语句,从而解析XML文件内容,产生mappedStatement,
而像下面这种service其实也是这样,不过他多了一步,它得先把service翻译成xml格式,然后再来转成mappedStatement。
@Service
public class AlgorithmicProblemServiceImpl extends ServiceImpl<AlgorithmicProblemMapper, AlgorithmicProblem> implements AlgorithmicProblemService {}
就拿上面的 insert 举例,MybatisPlus 中有一个 insert 类,即 com.baomidou.mybatisplus.core.injector.methods.Insert 其中就有关键方法
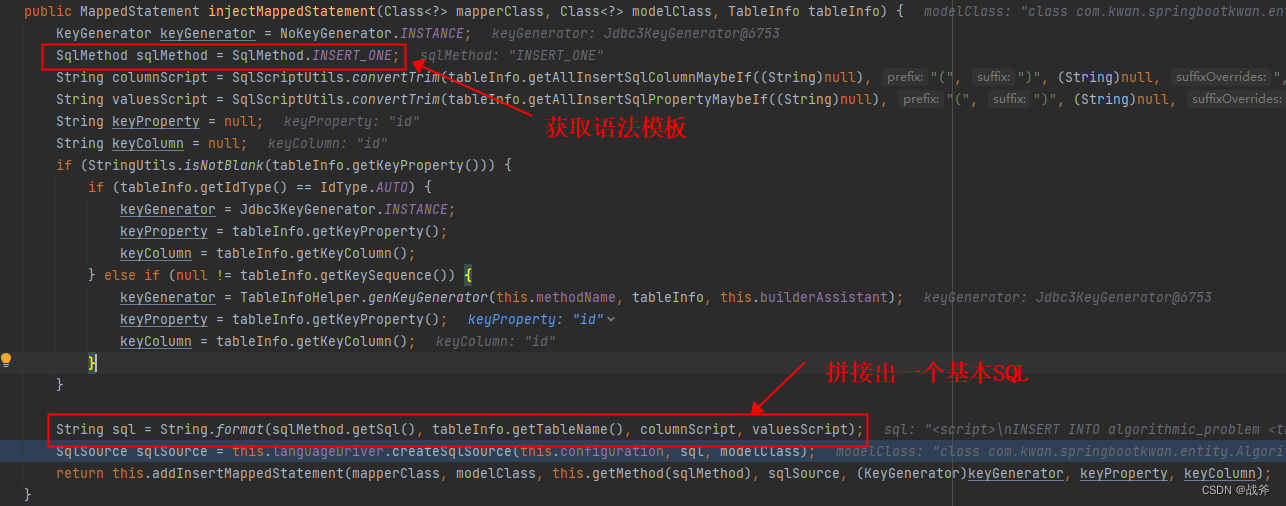
1. 获取语法模板SQL
所谓获取模板SQL,其实就是在MybatisPlus中内置了很多方法的基本语法,这些内容只要在填上对应的表名、字段名就能构成一个基础 SQL 的轮廓了
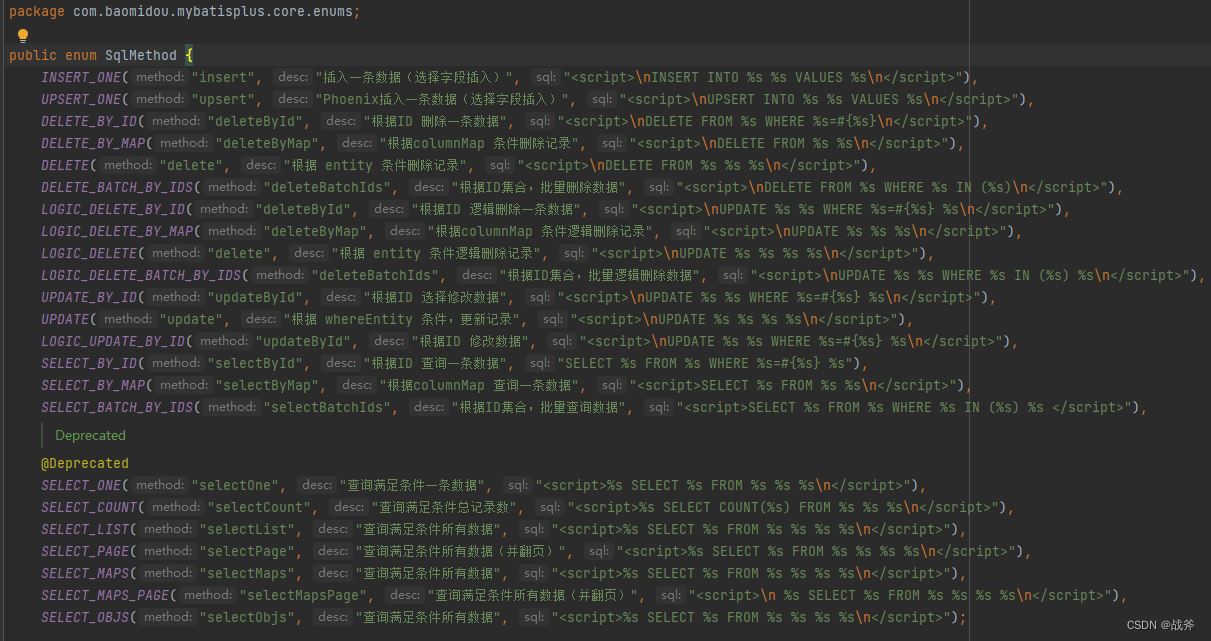
还是以我们的插入语句为例,比如我们想插入一条数据,它的基础语法模板就是
"<script>\nINSERT INTO %s %s VALUES %s\n</script>"
其中三个 ‘%s’ 就是待定的表名和字段名信息,将在后面代入表信息
2. 代入表及字段信息
我们上面看到了这样一句话,它的作用就是根据语法模板,和表信息,构造出一个基础的SQL
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
上面的第一个入参 sqlMethod.getSql() 就是我们上面说的语法模板,第二个入参是表名,三和四字段则是根据字段名拼出来的SQL,表名的话,我们在实体类里已经写了,即 @TableName 注解后面的内容
@Data
@ApiModel("算法题实体类")
@TableName("algorithmic_problem")
public class AlgorithmicProblem extends Model<AlgorithmicProblem> {@ApiModelProperty("主键id")private Integer id;@ApiModelProperty("问题名称")private String questionName;@ApiModelProperty("问题类型")private String questionType;@ApiModelProperty("1~10的分值")private Integer degreeOfImportance;@ApiModelProperty("1:简单;2:中等;3:困难")private Integer degreeOfDifficulty;@ApiModelProperty("困难指数")private Integer difficultyOfScore;@ApiModelProperty("力扣的问题号")private Integer leetcodeNumber;@ApiModelProperty("力扣的问题链接")private String leetcodeLink;@ApiModelProperty("标签")private String tag;@ApiModelProperty("创建时间")private Date createTime;@ApiModelProperty("逻辑删除,0未删除,1已删除")private Integer isDelete;
}
而后面的 columnScript, valuesScript 则是根据我们的字段值,生成的一些脚本,其中包含了我们以前在mybatis 的 xml 文件中会写的动态标签,这些标签的作用可以参考此片文章《数据库操作不再困难,MyBatis动态Sql标签解析》
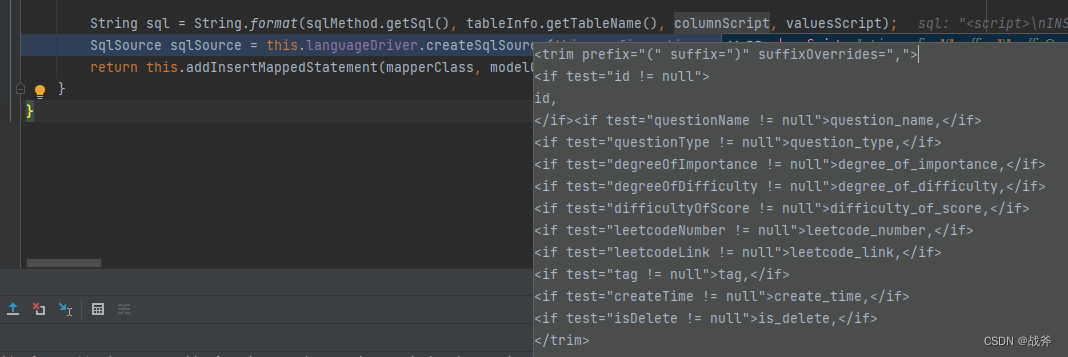
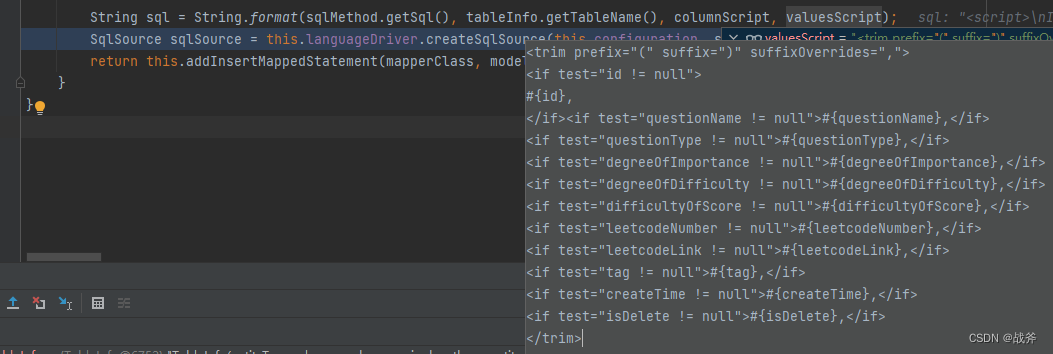
通过上面的操作,不难发现,我们以前在XML文件里需要写的 SQL 在此刻就被拼接出来了,它们形式是一样的。需要注意的是,这里的字段全都是非空才会插入的。
<script>
INSERT INTO algorithmic_problem <trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id != null">
id,
</if><if test="questionName != null">question_name,</if>
<if test="questionType != null">question_type,</if>
<if test="degreeOfImportance != null">degree_of_importance,</if>
<if test="degreeOfDifficulty != null">degree_of_difficulty,</if>
<if test="difficultyOfScore != null">difficulty_of_score,</if>
<if test="leetcodeNumber != null">leetcode_number,</if>
<if test="leetcodeLink != null">leetcode_link,</if>
<if test="tag != null">tag,</if>
<if test="createTime != null">create_time,</if>
<if test="isDelete != null">is_delete,</if>
</trim> VALUES <trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id != null">
#{id},
</if><if test="questionName != null">#{questionName},</if>
<if test="questionType != null">#{questionType},</if>
<if test="degreeOfImportance != null">#{degreeOfImportance},</if>
<if test="degreeOfDifficulty != null">#{degreeOfDifficulty},</if>
<if test="difficultyOfScore != null">#{difficultyOfScore},</if>
<if test="leetcodeNumber != null">#{leetcodeNumber},</if>
<if test="leetcodeLink != null">#{leetcodeLink},</if>
<if test="tag != null">#{tag},</if>
<if test="createTime != null">#{createTime},</if>
<if test="isDelete != null">#{isDelete},</if>
</trim>
</script>
3. 代入条件构造器逻辑
上面的部分对于简单的 insert来说,其实已经够用了,但是对于一些用户的查询或修改逻辑,比如我们在 servece 中写的那些筛选条件,排序等,它们又是如何起作用的呢?这里我们要分两个阶段来说:启动阶段、执行阶段
1. 启动阶段的 “ew” 参数
首先,我们在代码中写的所有wrapper(条件构造器),这些wrapper包含了筛选条件,排序规则之类的,其实最终都被视为一个参数“ew”(Entity Wrapper)放入BaseMapper中进行操作
// service 层@Override
public List<CsdnUserInfo> allUser() {QueryWrapper<CsdnUserInfo> wrapper = new QueryWrapper<>();wrapper.eq("is_delete", 0);wrapper.orderByDesc("user_weight");return this.list(wrapper);
}// IService 类
default List<T> list(Wrapper<T> queryWrapper) {return this.getBaseMapper().selectList(queryWrapper);
}// BaseMapper 类
List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
这个ew参数在下面就是核心,我们上面提到了,在应用启动阶段,经过基本语法和表的代入后,可以形成一些基础SQL脚本。而对于像selectList 这种,会带有ew参数的,他们的基础SQL就会比较复杂了,它们会在SQL中大量预留ew参数相关的内容。比如selectList 最终就会生成如下的一大串脚本:
<script>
<if test="ew != null and ew.sqlFirst != null">${ew.sqlFirst}
</if>
SELECT
<choose><when test="ew != null and ew.sqlSelect != null">${ew.sqlSelect}</when>
<otherwise>id,user_name,nick_name,like_status,collect_status,comment_status,user_weight,user_home_url,curr_blog_url,article_type,create_time,update_time,is_delete</otherwise>
</choose> FROM csdn_user_info <if test="ew != null"><where><if test="ew.entity != null"><if test="ew.entity.id != null">id=#{ew.entity.id}</if><if test="ew.entity['userName'] != null"> AND user_name=#{ew.entity.userName}</if><if test="ew.entity['nickName'] != null"> AND nick_name=#{ew.entity.nickName}</if><if test="ew.entity['likeStatus'] != null"> AND like_status=#{ew.entity.likeStatus}</if><if test="ew.entity['collectStatus'] != null"> AND collect_status=#{ew.entity.collectStatus}</if><if test="ew.entity['commentStatus'] != null"> AND comment_status=#{ew.entity.commentStatus}</if><if test="ew.entity['userWeight'] != null"> AND user_weight=#{ew.entity.userWeight}</if><if test="ew.entity['userHomeUrl'] != null"> AND user_home_url=#{ew.entity.userHomeUrl}</if><if test="ew.entity['currBlogUrl'] != null"> AND curr_blog_url=#{ew.entity.currBlogUrl}</if><if test="ew.entity['articleType'] != null"> AND article_type=#{ew.entity.articleType}</if><if test="ew.entity['createTime'] != null"> AND create_time=#{ew.entity.createTime}</if><if test="ew.entity['updateTime'] != null"> AND update_time=#{ew.entity.updateTime}</if><if test="ew.entity['isDelete'] != null"> AND is_delete=#{ew.entity.isDelete}</if></if><if test="ew.sqlSegment != null and ew.sqlSegment != '' and ew.nonEmptyOfWhere"><if test="ew.nonEmptyOfEntity and ew.nonEmptyOfNormal"> AND </if>${ew.sqlSegment}</if></where><if test="ew.sqlSegment != null and ew.sqlSegment != '' and ew.emptyOfWhere">${ew.sqlSegment}</if></if>
<if test="ew != null and ew.sqlComment != null">${ew.sqlComment}
</if>
</script>
这里面,我们看到这段SQL中,涉及ew参数的有这么几个非常重要的元素:
-
ew.sqlFirst:表示SQL片段,可以自定义SQL片段放在SQL的最开始位置 -
ew.sqlSelect:表示要查询的字段,默认为"*",即查询所有字段。可以通过该属性指定要查询的字段,多个字段之间用逗号分隔 -
ew.entity:表示要查询的实体对象。可以通过该属性指定要查询的实体对象,可以根据实体对象的属性进行条件封装 -
ew.sqlSegment:表示SQL片段,可以自定义SQL片段,用于在动态SQL中添加自定义的SQL语句 -
ew.sqlComment:表示SQL注释,可以为SQL语句添加注释。可以通过该属性指定要为SQL语句添加的注释内容。
2. 执行阶段的 “ew” 参数
以我们上面提到过的代码为例
public List<CsdnUserInfo> allUser() {QueryWrapper<CsdnUserInfo> wrapper = new QueryWrapper<>();wrapper.eq("is_delete", 0);wrapper.orderByDesc("user_weight");return this.list(wrapper);
}
这样的 wrapper 最终会形成这样一个对象,我们为它添加了两个属性,即
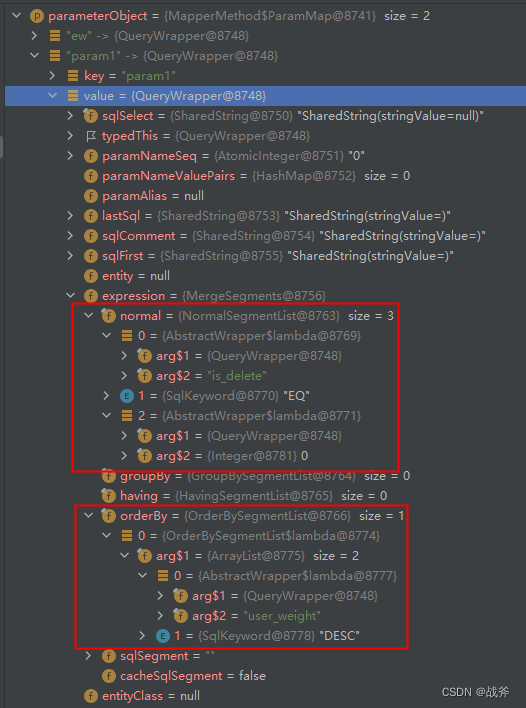
有些眼尖的同学发现了,xml中用的是 ew.sqlSegment, 而我们这里的条件全部都进了 ew.expression 中,这两也没对上啊。其实在条件构造器中 ew.sqlSegment = expression.getSqlSegment + lastSql
// AbstractWrapper
public String getSqlSegment() {return this.expression.getSqlSegment() + this.lastSql.getStringValue();
}
而 expression.getSqlSegment() 又是其下的各个小 Segment 拼出来的
this.sqlSegment = this.normal.getSqlSegment() + this.groupBy.getSqlSegment() + this.having.getSqlSegment() + this.orderBy.getSqlSegment();
如此一来,利用ognl,筛选条件也被我们拼凑出来了,最后拼接出 ew.sqlSegment 实际解析成为了一个字符串
(is_delete = #{ew.paramNameValuePairs.MPGENVAL1}) ORDER BY user_weight DESC
这个时候,又有眼尖的同学发现了,我们在代码中明明已经写死了 is_delete = 0,为什么解析完却成了 is_delete = #{ew.paramNameValuePairs.MPGENVAL1}
实际上这里有一个兼容的作用,我们可以在业务代码里写 wrapper.eq(“is_delete”, 0),也可以填上一个未知的变量 wrapper.eq(“is_delete”, var1),我们都知道为了防止SQL注入,实际上对于入参我们都是在最后才提交进SQL中的,不可能因为你是写死的0,就提前把0填写在这里。所以,此处会先把你填的东西存放在 paramNameValuePairs 参数键值对中,再后面提交SQL的时候才取出来。其源码如下:
// AbstractWrapper// 把一个条件翻译sqlSegment,以上述wrapper.eq("is_delete", 0)为例,此处column 为字符串“is_delete” ;sqlKeyword 为EQ的枚举值,会被翻译成字符串,最后的参数值则会被翻译成成如 {ew.paramNameValuePairs.MPGENVAL}=protected Children addCondition(boolean condition, R column, SqlKeyword sqlKeyword, Object val) {return this.maybeDo(condition, () -> {this.appendSqlSegments(this.columnToSqlSegment(column), sqlKeyword, () -> {return this.formatParam((String)null, val);});});}protected final String formatParam(String mapping, Object param) {String genParamName = "MPGENVAL" + this.paramNameSeq.incrementAndGet();String paramStr = this.getParamAlias() + ".paramNameValuePairs." + genParamName;this.paramNameValuePairs.put(genParamName, param);return SqlScriptUtils.safeParam(paramStr, mapping);}
那么现在我们已经拥有了两件东西:1.一个大而全的基础SQL语句(里面依赖了大量的ew内容),2.一个完整的“ew”对象。同时拥有这两者后,就能够利用 Mybatis 的动态解析能力去构建出一个真正的可执行的SQL了
总结
本次我们介绍了MybatisPlus 构造器wrapper的使用方式及其易错点,同时也针对其运行的原理进行了解释,只有深刻理解了它的原理,我们才能更灵活的使用,并且更快的排查出问题。所以也希望大家能结合源码再思考一下,以便更好地掌握这部分内容。
这篇关于MybatisPlus 构造器wrapper的使用与原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







