本文主要是介绍【bash】笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在Shell脚本中,-e 是一个测试运算符,用于检查给定的文件或目录是否存在。
| 是通道符,会把前面的输出给后面作为输入。
sudo tee命令在这里用于同时更新文件和在终端显示输出(尽管 > /dev/null 将标准输出重定向到黑洞,即不显示任何内容)。这样做的目的是在不影响用户交互的情况下安全地更新系统设置。

在Shell脚本中,$0是一个特殊变量,它代表脚本本身的文件名(包含路径)。当脚本被执行时,$0就保存了这个脚本的名字。这在脚本内部需要引用脚本名称或者路径时非常有用,比如在打印日志、错误信息或者像上面提到的帮助信息中显示脚本名。

在Shell脚本中,$#是一个特殊变量,表示传递给脚本或函数的参数个数。
-gt 是大于(greater than)的比较运算符。

在Shell脚本中,$1是一个特殊变量,它代表传递给脚本或函数的第一个命令行参数。当你运行一个脚本并提供一些参数,$1将存储第一个参数的值,$2存储第二个参数,以此类推,$0存储脚本本身的名字。
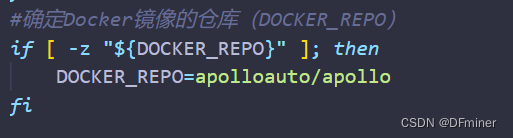
-z 后面么有就是真。
所以,如果${DOCKER_REPO}没有被设置或者值为空,脚本将把DOCKER_REPO设置为apolloauto/apollo。这确保了在没有指定Docker镜像仓库的情况下,有一个默认的仓库值可供使用。
在Docker容器内使用CUDA,你需要确保几个关键步骤都已完成:
-
使用支持CUDA的Docker镜像:首先,你需要一个包含CUDA和NVIDIA驱动的Docker镜像。NVIDIA提供了官方的CUDA镜像,这些镜像是基于不同的基础镜像(如Ubuntu、Debian等)构建的,并且已经包含了CUDA和NVIDIA驱动。你可以通过
docker pull命令从Docker Hub拉取这些镜像。 -
启用NVIDIA Docker插件:NVIDIA Docker工具包允许你在Docker中充分利用NVIDIA GPU。你需要安装NVIDIA Container Toolkit,它提供了运行CUDA容器所需的驱动和库。
-
设置环境变量:在运行Docker容器时,可以通过
-e选项设置环境变量,比如CUDA_VISIBLE_DEVICES来指定哪个GPU可以被容器看到和使用。 -
挂载CUDA库:如果需要访问主机上的CUDA安装,可以通过
-v选项挂载CUDA库的路径,如/usr/local/cuda,这样容器内可以访问到这些库。不过,通常情况下,如果你使用的是带有CUDA的预配置镜像,这些库应该已经包含在镜像内。
一个基本的Docker运行命令可能如下所示:
--gpus all允许容器访问所有的GPU。-e CUDA_VISIBLE_DEVICES=0设置环境变量,指定GPU 0 可见。-v /usr/local/cuda:/usr/local/cuda挂载主机上的CUDA路径到容器内。
docker run
--gpus all
-e CUDA_VISIBLE_DEVICES=0
-v /usr/local/cuda:/usr/local/cuda -it nvidia/cuda:11.0-base bash
-v /usr/local/cuda:/usr/local/cuda
这篇关于【bash】笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






