本文主要是介绍苹果推出M4芯片,平平无奇?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Apple 发布 M4 芯片,在显示和AI性能方面均有显著改进,为全新iPad Pro提供非凡性能。M4 采用第二代3纳米技术,配备10核CPU和10核GPU,拥有最快的神经引擎,使iPad Pro成为强大的人工智能设备。
Apple 今天发布了 M4,这是一款为全新iPad Pro提供非凡性能的最新芯片。M4 采用第二代 3 纳米技术构建,是一款片上系统 (SoC),它提高了 Apple 芯片行业领先的能效,并实现了 iPad Pro 令人难以置信的轻薄设计。它还配备了全新的显示引擎,可驱动 iPad Pro 上突破性的 Ultra Retina XDR 显示屏实现令人惊叹的精度、色彩和亮度。
新芯片的CPU拥有多达10个核心,而新的10核GPU则建立在M3引入的下一代GPU架构之上,并首次为iPad带来动态缓存、硬件加速光线追踪和硬件加速网格着色功能时间。M4 拥有 Apple 有史以来最快的神经引擎,每秒能够执行高达 38 万亿次操作,这比当今任何 AI PC 的神经处理单元都快。结合更快的内存带宽、CPU 中的下一代机器学习 (ML) 加速器以及高性能 GPU,M4 使新款 iPad Pro 成为一款极其强大的人工智能设备。
苹果硬件技术高级副总裁 Johny Srouji 表示:“搭载 M4 的新款 iPad Pro 是一个很好的例子,展示了如何构建一流的定制芯片来实现突破性产品。” “M4 的高能效性能及其全新显示引擎,使 iPad Pro 的轻薄设计和改变游戏规则的显示成为可能,而 CPU、GPU、神经引擎和内存系统的根本改进使 M4 非常适合了解利用人工智能的最新应用程序。总而言之,这款新芯片使 iPad Pro 成为同类设备中功能最强大的设备。”

台积电第二代3nm工艺
M4 由 280 亿个晶体管组成,采用第二代 3 纳米技术构建,进一步提高了 Apple 芯片的功效。M4 还采用采用开创性技术设计的全新显示引擎,实现 Ultra Retina XDR 显示屏令人惊叹的精度、色彩准确度和亮度均匀性,这是一种通过结合两个 OLED 面板的光线创建的最先进的显示屏。
从这个描述我们可以高度确定。苹果对“第二代 3nm 工艺”的描述与台积电的第二代 3nm 工艺 N3E完全吻合。他们的 3nm 工艺节点的增强版与 M3 系列芯片使用的 N3B 工艺相比有点逊色;N3E 的密度不如 N3B,但根据台积电的说法,它提供了稍微更好的性能和功耗特性。差异非常接近,以至于架构发挥着更大的作用,但在能源效率的竞赛中,苹果将占据他们能获得的任何优势。
多年来,苹果作为台积电新工艺节点发布合作伙伴的地位已经确立,而且苹果似乎是第一家推出 N3E 工艺芯片的公司。然而,它们不会是最后一个,因为几乎所有台积电的高性能客户预计都将在明年采用 N3E。因此,像往常一样,苹果在芯片制造方面的直接优势只是暂时的。
苹果公司早期的领导者地位也可能解释了为什么我们现在看到的是 iPad 上的 M4(苹果公司的一款销量相对较低的设备)而不是 MacBook 系列。到了某个时候,台积电的N3E产能将会迎头赶上,然后再追上一些。我不会冒险猜测苹果公司当时对该系列产品的计划,因为我真的看不到苹果公司这么快就停止生产 M3 芯片,但这也让他们陷入了一个尴尬的境地,不得不在M4存在。
尚未公布新芯片的芯片尺寸(或发布的芯片照片),但晶体管总数为 280 亿个,仅比 M3 的晶体管数量稍多,这表明苹果并没有投入过多的新硬件。
M4 CPU 架构:四个性能核,六个效率核心
从 CPU 方面开始,我们面临着苹果 M4 CPU 核心设计的一个谜。苹果公司守口如瓶,而且缺乏与 M3 的性能比较,这意味着我们没有获得太多有关 CPU 设计比较的信息。因此,M4 是否代表了苹果 CPU 设计的分水岭——新的 Monsoon/A11——还是类似于 A17 中的 Everest CPU 内核的小更新,还有待观察。当然,我们希望后者,但如果没有更多细节,我们将根据我们所知道的情况进行工作。
Apple 关于 SoC 的简短主题演讲指出,性能和效率核心都实现了改进的分支预测,对于性能核心,还实现了更广泛的解码和执行引擎。然而,这些与苹果为 M3 所做的广泛声明相同,因此这本身并不代表新的 CPU 架构。
据苹果介绍,M4 拥有全新的多达 10 核的 CPU,其中最多包含四个性能核心,现在包含六个效率核心。下一代内核具有改进的分支预测功能,为性能内核提供更广泛的解码和执行引擎,为效率内核提供更深层次的执行引擎。这两种类型的核心还具有增强的下一代机器学习加速器。
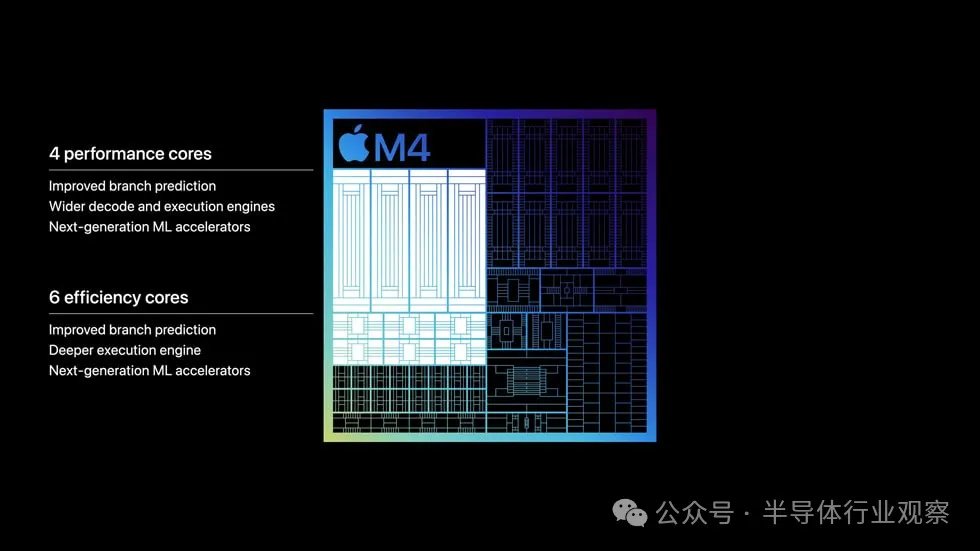
与前代 iPad Pro 中强大的 M2 相比,M4 的 CPU 性能提高了 1.5 倍。1无论是在 Logic Pro 中处理复杂的管弦乐文件,还是在 LumaFusion 中向 4K 视频添加高要求的效果,M4 都能提高整个专业工作流程的性能。
然而,Apple M4 CPU 声称的独特之处在于这两种 CPU 核心类型都是“下一代机器学习加速器”。这与苹果更广泛地关注 M4 中的 ML/AI 性能密切相关,尽管该公司并未详细说明这些加速器的具体用途。由于 NPU 负责完成所有繁重工作,CPU 内核上 AI 增强的目的不再是总吞吐量/性能,而是更多地处理混合在更通用工作负载中的轻型推理工作负载,而无需花费时间和资源来处理专用NPU。
一个有根据的猜测是,苹果已经更新了他们记录很少的 AMX 矩阵单元,这些单元从一开始就是 M 系列 SoC 的一部分。然而,最近的 AMX 版本已经支持常见的 ML 数字格式,如 FP16、BF16 和 INT8,因此,如果 Apple 在此进行更改,那么这并不是添加(更多)常见格式之类的简单明了的事情。同时,如果是 AMX,看到苹果提及它会有点令人惊讶,因为他们对这些设备非常保密。
另一个合理的选择是,Apple 对其 CPU 内的 SIMD 单元进行了一些更改,以添加常见的 ML 数字格式,因为开发人员可以更直接地访问这些单元。但与此同时,Apple 一直在推动开发人员从一开始就使用更高级别的框架(这就是访问 AMX 的方式),因此这实际上可能会发生任何一种情况。
无论如何,无论支撑 M4 的 CPU 核心是什么,有一点是确定的:它们的数量更多。完整的 M4 配置包括 4 个性能核心和 6 个效率核心,比 M3 多 2 个效率核心。精简版 iPad 型号获得 3P+6E 配置,而更高级别的配置则获得完整的 4P+6E 体验,因此对性能的影响可能是显而易见的。
在其他条件相同的情况下,与 M3 的 4P+4E 配置相比,添加两个效率核心不会大幅提高 CPU 性能。但苹果的效率核心也不应该被低估,因为即使苹果的效率核心由于使用了乱序执行而也相对强大。特别是当固定工作负载可以保留在效率核心上而不是提升到性能核心上时,能源效率提升的空间很大。
除此之外,Apple 尚未发布新 SoC/CPU 内核的任何详细性能图表,因此几乎没有什么硬数据可讨论。但该公司声称 M4 的 CPU 性能比 M2 快 50%。这大概是针对可以利用 M4 的 CPU 核心数量优势的多线程工作负载。另外,苹果在主题演讲中还声称他们可以以一半的功耗提供 M2 性能,结合工艺节点改进、架构改进和 CPU 核心数量增加,这似乎是一个合理的主张。
然而,与往常一样,我们必须看看独立基准的结果如何。
M4 GPU 架构:光线追踪和动态缓存
M4 的全新 10 核 GPU 建立在 M3 系列芯片的下一代图形架构之上。它具有动态缓存功能,这是 Apple 的一项创新,可以在硬件中实时动态分配本地内存,从而显着提高 GPU 的平均利用率。这显着提高了最苛刻的专业应用程序和游戏的性能。
与 M4 上的 CPU 情况相比,GPU 情况要简单得多。最近刚刚在 M3 中引入了新的 GPU 架构(Apple 不像 CPU 那样频繁迭代这种核心类型),Apple 几乎已经确认 M4 中的 GPU 与 M3 中的架构相同。
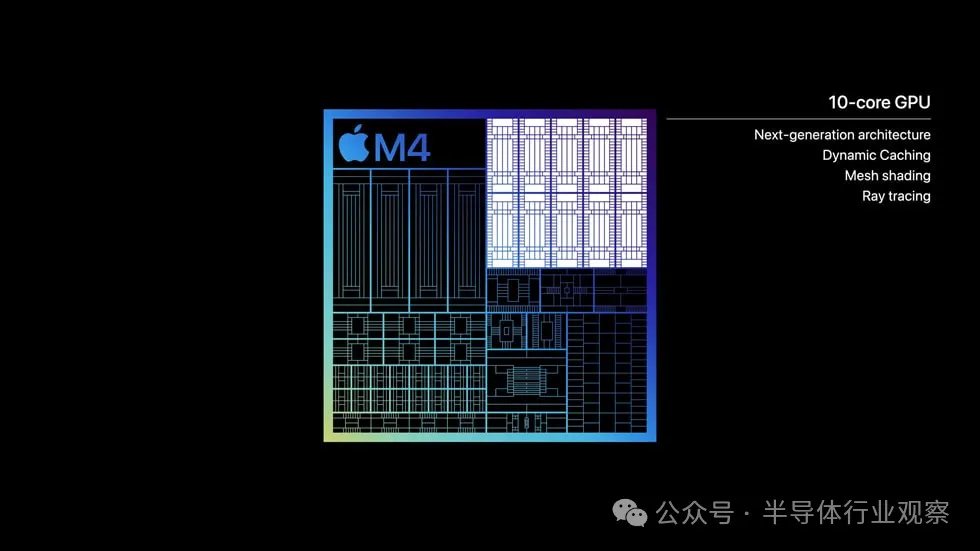
拥有 10 个 GPU 核心,高级配置与 M3 上的配置相同。这是否意味着各种块和缓存与 M3 真正相同还有待观察,但苹果并没有对 M4 的 GPU 性能做出任何声明,无论以何种方式都可以解释为它优于 M3 的 GPU。事实上,iPad 较小的外形尺寸和更有限的冷却能力意味着 GPU 在任何持续的工作负载下都会受到热量限制,特别是与 M3 在 14-14 等主动冷却设备中的表现相比。英寸 MacBook Pro。
无论如何,这意味着 M4 配备了 M3 GPU 引入的所有主要新架构功能:光线追踪、网格着色和动态缓存。苹果也强调,硬件加速光线追踪也首次登陆 iPad,在游戏和其他图形丰富的体验中实现更真实的阴影和反射。硬件加速网格着色也内置于 GPU 中,可提供更强大的几何处理能力和效率,从而在游戏和图形密集型应用程序中实现视觉上更加复杂的场景。M4 使 Octane 等应用程序中的专业渲染性能得到了巨大提升,现在比 M2 快四倍。
这里,我们不强调光纤追踪,但网格着色是一种重要的下一代几何处理方法。与此同时,动态缓存是 Apple 对其在 M 系列芯片上改进的内存分配技术的术语,该技术可以避免从 Apple 统一的内存池中向 GPU 过度分配内存。
通过对 CPU 和 GPU 的这些改进,M4 保持了 Apple 芯片业界领先的每瓦性能。M4 只需一半的功耗即可提供与 M2 相同的性能。与轻薄笔记本电脑中最新的 PC 芯片相比,M4 只需四分之一的功耗即可提供相同的性能。
除了 GPU 渲染之外,M4 还获得了 M3 更新的媒体引擎块,该块来自 M2,对于 iPad 使用来说是一个相对重要的事情。最值得注意的是,M3/M4 的媒体引擎模块增加了对 AV1 视频解码(下一代开放视频编解码器)的支持。虽然 Apple 非常乐意为 HEVC/H.265 支付版税以确保其在其生态系统中可用,但免版税的 AV1 编解码器预计将在未来几年中发挥重要作用和使用,而 iPad Pro可以更好地使用最新的编解码器(或者至少不必在软件中低效地解码 AV1)。
然而,M4 在显示方面的创新之处在于新的显示引擎。该模块负责合成图像并驱动设备上连接的显示器,Apple 从未给予该模块特别多的关注,但当他们对其进行更新时,它通常会立即带来一些功能改进。
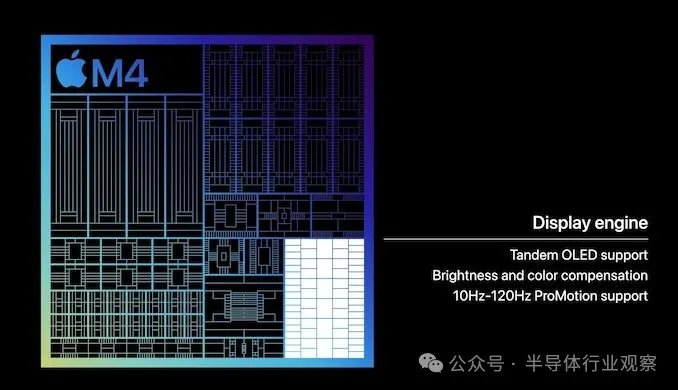
这里的关键变化似乎是启用苹果新的夹层“串联”OLED 面板配置,该配置在 iPad Pro 中首次亮相。iPad 的 Ultra Retina XDR 显示屏将两块 OLED 面板直接叠置在一起,以便显示屏能够累计达到苹果 1600 尼特的亮度目标,而单块 OLED 面板显然无法做到这一点。这反过来又需要一个知道如何操纵面板的显示控制器,不仅要驱动一组镜像显示器,还要考虑由于一个面板位于另一个面板之下而导致的性能损失。
虽然与 iPad Pro 没有直接关系,但看看苹果是否利用这个机会增加 M4 可以驱动的显示器总数将会很有趣,因为普通的 M 系列 SoC 通常仅限于 2 个显示器,这对于MacBook 用户的惊愕。事实上,M4 可以驱动串联 OLED 面板和外部 6K 显示器,这一点是有希望的,但当 M4 登陆 Mac 时,我们将看到这如何转化为 Mac 生态系统。
M4 NPU 架构:新的东西,更快的东西
可以说,苹果 M4 SoC 的最大焦点是该公司的 NPU,也称为神经引擎。自 M1 以来,该公司一直在推出 16 核设计(在此之前的 A 系列芯片上也采用了较小的设计),每一代都提供了适度的性能提升。但苹果表示,随着 M4 一代的出现,他们的性能有了更大的飞跃。
M4 NPU 仍采用 16 核设计,额定速度为 38 TOPS,仅是 M3 中 18 TOPS 神经引擎的两倍多。巧合的是,仅比 A17 中的神经引擎高几个 TOPS。因此,作为基准声明,苹果宣称 M4 NPU 比 M3 中的 NPU 强大得多,更不用说为以前的 iPad 提供动力的 M2,甚至更早,比 A11 的 NPU 快 60 倍。
不幸的是,问题(再一次)出现在细节中,因为 Apple 没有列出所有重要的精度信息 - 无论该数字是基于 INT16、INT8 还是 INT4 精度。作为目前 ML 推理的法律精度,INT8 是最有可能的选择,特别是因为这是苹果去年 A17 的报价。但自由地混合精度,甚至只是不披露它们,至少可以说是令人头痛的。这使得同类规格的比较变得困难。
无论如何,即使大部分性能改进来自 INT8 支持而不是 INT16/FP16 支持,M4 NPU 也有望为 AI 性能带来显著的性能改进,类似于 A17 已经发生的情况。由于苹果是第一批推出带有我们现在所称的 NPU 的消费级 SoC 的芯片供应商之一,因此该公司并不害怕在这个问题上大肆宣扬,尤其是与市场上正在发生的事情进行比较。电脑领域。特别是由于苹果提供的是一个完整的硬件/软件生态系统,该公司的优势在于能够使用自己的 NPU 来塑造他们的软件,而不是等待为其发明杀手级应用程序。
按照苹果的描述,M4 拥有速度极快的神经引擎,这是芯片中专门用于加速 AI 工作负载的 IP 模块。这是 Apple 有史以来最强大的神经引擎,每秒能够执行惊人的 38 万亿次操作,比 A11 Bionic 中的第一个神经引擎快了惊人的 60 倍。神经引擎与 CPU 中的下一代机器学习加速器、高性能 GPU 和更高带宽的统一内存一起,使 M4 成为一款极其强大的 AI 芯片。借助 iPadOS 中的 AI 功能(例如用于实时音频字幕的 Live Captions 以及识别视频和照片中的对象的 Visual Look Up),新款 iPad Pro 允许用户在设备上快速完成令人惊叹的 AI 任务。
配备 M4 的 iPad Pro 只需轻按一下即可轻松将 Final Cut Pro 中的 4K 视频中的主题与其背景分离,并且只需聆听某人弹钢琴即可在 StaffPad 中自动实时创建乐谱。推理工作负载可以高效、私密地完成,同时最大限度地减少对应用内存、应用响应能力和电池寿命的影响。M4 中的神经引擎是 Apple 迄今为止功能最强大的神经引擎,比当今任何 AI PC 中的任何神经处理单元都更强大。
M4内存:采用更快的LPDDR5X
最后但同样重要的一点是,M4 SoC 的内存功能也得到了显着改进。鉴于苹果为 M4 报价的内存带宽数据(120GB/秒),所有迹象都表明他们最终在其新 SoC 中采用了 LPDDR5X。
LPDDR5X 是 LPDDR5 标准的中期更新,可提供比 LPDDR5 更高的内存时钟速度,最高可达 6400 MT/秒。虽然 LPDDR5X 目前的速度高达 8533 MT/秒(并且还会有更快的速度),但根据 Apple M4 的 120GB/秒的数据,这使得内存时钟速度约为 LPDDR5X-7700。
由于 M4 将首先应用于 iPad,目前我们还不清楚它的最大内存容量。M3 可以容纳高达 24GB 的内存,虽然苹果在这方面不太可能退步,但也没有迹象表明他们是否能够将内存增加到 32GB。与此同时,iPad Pro 都将配备 8GB 或 16GB RAM,具体取决于具体型号。
这篇关于苹果推出M4芯片,平平无奇?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









