本文主要是介绍OpenAI推出DALL·E 3识别器、媒体管理器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
5月8日,OpenAI在官网宣布,将推出面向其文生图模型DALL·E 3 的内容识别器,以及一个媒体管理器。
随着ChatGPT、DALL·E 3等生成式AI产品被大量应用在实际业务中,人们越来越难分辨AI和人类创建内容的区别,这个识别器可以帮助开发人员快速识别内容的真假。
目前,OpenAI已经开放了DALL·E 3识别器的API,开发人员从今天开始至7月31日可申请试用。OpenAI会在8月31日之前公布获取使用权限的名单。
这个媒体管理器主要是面向媒体行业、内容创作者的产品,帮助控制自己的知识产权内容是否会被OpenAI搜集用于训练AI模型。
DALL·E 3内容识别器申请地址:https://openai.smapply.org/prog/dalle_detection_classifier_access_program/

AI生成的内容真假难辨
由于DALL·E 3等大模型生成的图片能达到以假乱真的效果,例如,AI合成的斯威夫特色情照片被疯传。
早在今年2月7日,OpenAI宣布在DALL·E 3生成的图片中嵌入了 C2PA的元数据,以防止图片被非法乱用。即将发布的文生视频模型Sora,也会集成C2PA元数据。
C2PA是一种开放数据标准,允许出版商、企业、开发者等,通过元数据来跟踪和验证数字内容,例如,图片、视频、文档等,最初来源、真实性和完整性等。
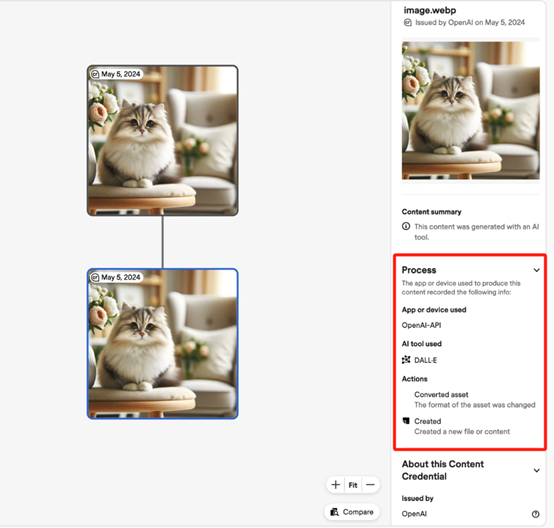
但这些还远远不够,因为可以通过技术手段去除这些元数据,使得人们在视觉上还是无法分辨。所以,OpenAI开发了这款内容识别器帮助开发人员、用户来识别内容真假。
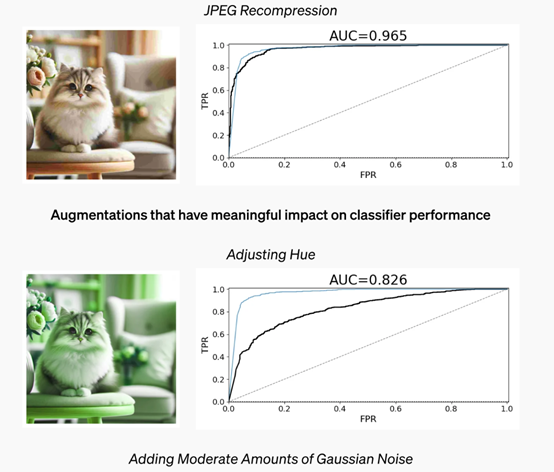
OpenAI表示,即便对AI生成的图片进行压缩、裁剪、更改饱和度/颜色、去除水印、改变形状等各种常规操作,识别器的准确率仍高达98%。
此外,AI生成语音的造假能力比文本、图片、视频高出好几倍,并且已经有人被AI语音诈骗过钱财。
OpenAI还开发了一种音频水印,将其集成在自定义语音模型 Voice Engine中,目前处于产品预览阶段。
媒体管理器,保护知识产权
前不久,《纽约日报》、《芝加哥论坛报》、《奥兰多前哨报》、《水星报》等8家知名媒体联名状告OpenAI,在没有获取授权的情况下使用其文章训练AI模型。而谷歌也因为非法搜集数据,同样被起诉过。

目前,OpenAI用于训练AI模型的数据主要有两个渠道:第一个,付费知识产权渠道,例如,OpenAI与《金融时报》、《世界报》、Prisa Media、Axel Springer等媒体签订的数据合作协议,每年支付他们上千万欧元以获取使用数据的权利。
第二个,公开渠道,这包括大量的开源数据集和通过爬虫获取到的数据。爬虫在抓取的过程中可能会非法搜集一些知名网站的数据,就会出现那8家媒体状告OpenAI的情况。
因此,OpenAI正在开发一款“媒体管理器”,可以轻松管理知识产权内容,哪些可以被AI搜集,哪些不可以。预计该产品将在2025年之前发布。
OpenAI最近还对ChatGPT生成的内容加上了原始网站链接,例如,达拉斯最适合午夜约会的5家餐厅。ChatGPT会在回答的每一条内容上加上餐厅的官网地址。
一方面,可以保护知识产权增加内容的可信度;另一方面,正在为其推出的搜索引擎做铺垫,可以像谷歌搜索那样列出所有答案的原始链接。
本文素材来源OpenAI官网,如有侵权请联系删除
END
这篇关于OpenAI推出DALL·E 3识别器、媒体管理器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









