本文主要是介绍【经验01】spark执行离线任务的一些坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目背景:
目前使用spark跑大体量的数据,效率还是挺高的,机器多,120多台的hadoop集群,还是相当的给力的。数据大概有10T的量。
最近在出月报数据的时候发现有一个任务节点一直跑不过去,已经超过失败次数的阈值,报警了。
预警很让人头疼,不能上班摸鱼了。
经过分析发现报错日志如下:
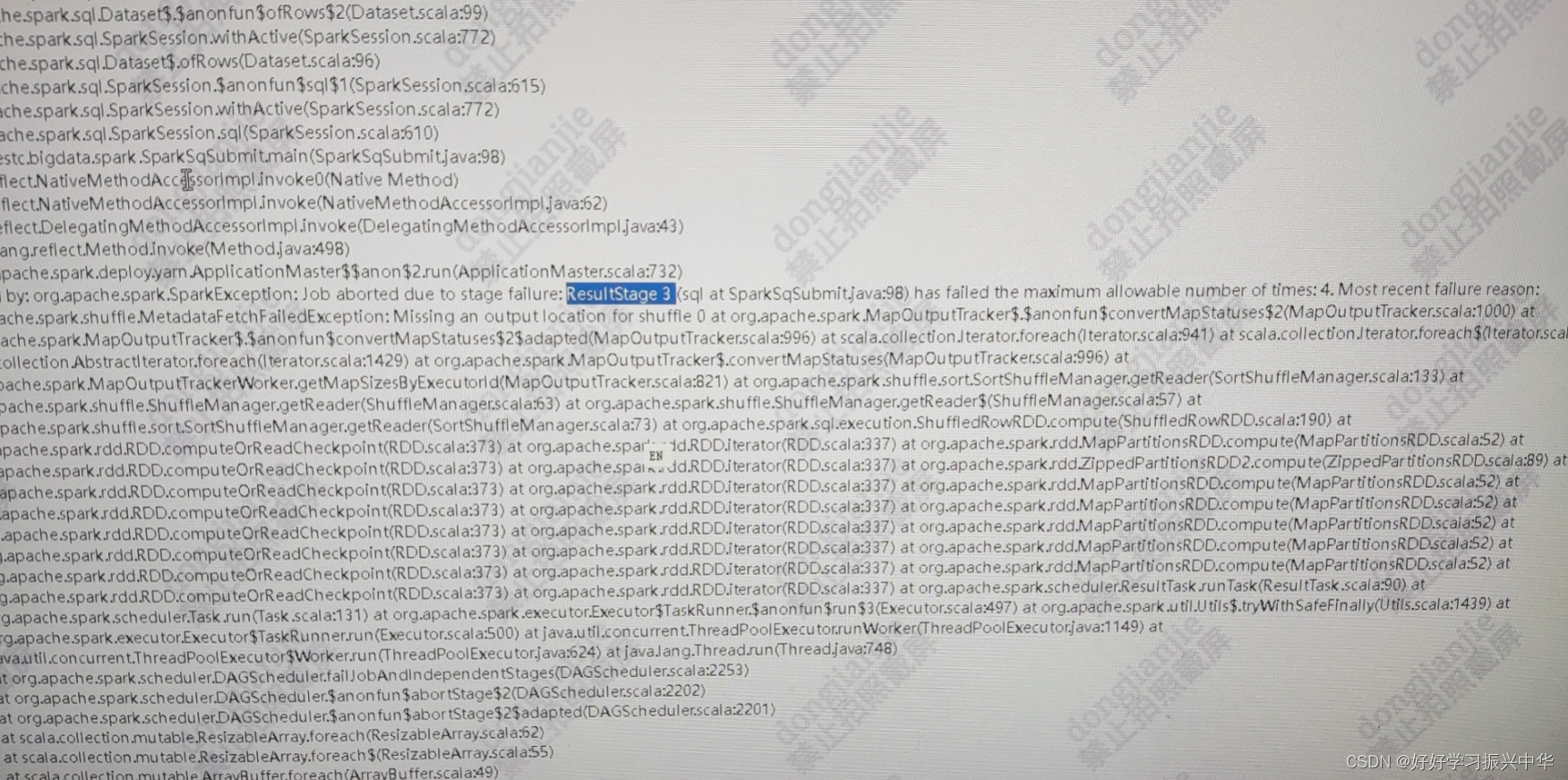
逻辑处理也很简单,两张表做关联,做聚合预算(聚合字段有30多个)相当于一个宽表了。
DWD层的dwd_temp
这篇关于【经验01】spark执行离线任务的一些坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





