本文主要是介绍后端开发面经系列 -- 滴滴C++一面面经,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
滴滴C++一面面经
公众号:阿Q技术站
来源:https://www.nowcoder.com/feed/main/detail/38cf9704ef084e27903d2204352835ef
1、const在C和C++区别,const定义的类成员变量如何初始化?
区别
- C中的const:
- 在C中,
const用于声明只读变量,即变量的值不能被修改。 - C中的常量通常使用
#define预处理指令定义,但是使用const关键字也是一种常见的方式。
- 在C中,
示例:
const int MAX_VALUE = 100;
int main() {const int a = 10;// 在C中,试图修改 const 变量的值会导致编译错误// a = 20; // 错误return 0;
}
- C++中的const:
- 在C++中,
const用于指定不可变数据,包括不可变对象、不可变函数参数以及不可变成员函数。 - 在C++中,还可以使用
const对象来调用const成员函数,但是不能调用非const成员函数。
示例:
class MyClass {
public:void func() const {// const 成员函数可以访问但不能修改非 const 成员变量// value = 100; // 错误}
private:int value;
};int main() {const int b = 20; // 常量MyClass obj;obj.func(); // 调用 const 成员函数return 0;
}
如何初始化?
在C和C++中,const定义的类成员变量在初始化时可以通过初始化列表或构造函数的形式进行初始化。
在C++中,可以在类的构造函数初始化列表中对const成员变量进行初始化,因为const成员变量在创建对象时必须进行初始化。示例如下:
#include <iostream>class MyClass {
public:MyClass(int value) : constMember(value) {// 可以在构造函数的初始化列表中初始化const成员变量}void printConstMember() {std::cout << "constMember: " << constMember << std::endl;}private:const int constMember;
};int main() {MyClass obj(10);obj.printConstMember();return 0;
}
在C语言中没有类的概念,但可以使用结构体来模拟类的功能。对于const成员变量的初始化,可以在结构体的初始化函数中进行初始化。示例如下:
#include <stdio.h>struct MyClass {const int constMember;
};void MyClass_init(struct MyClass *obj, int value) {obj->constMember = value;
}void MyClass_print(const struct MyClass *obj) {printf("constMember: %d\n", obj->constMember);
}int main() {struct MyClass obj;MyClass_init(&obj, 10);MyClass_print(&obj);return 0;
}
在C++中,推荐使用构造函数的初始化列表来初始化const成员变量;在C语言中,使用初始化函数来初始化const成员变量。
2、空的class占用多少内存?
空的类(或结构体)在C++中占用的内存空间取决于编译器的实现。一般情况下,空的类或结构体会占用一个字节的内存空间。这是因为C++标准规定,每个对象(包括空对象)在内存中都应该有独一无二的地址,以便于区分不同的对象。
3、sizeof一个类,类有5个函数,其中2个虚函数,还有一个整型,一个short。sizeof结果?
class MyClass {
public:virtual void func1();virtual void func2();void func3();void func4();void func5();private:int x;short y;
};
根据C++的对齐规则,非静态数据成员的对齐值通常为其自身大小或所在平台的最大对齐值中较小的一个。对于大多数平台,int 的对齐值为4字节,short 的对齐值为2字节。
类 MyClass 的大小计算如下:
- 非静态数据成员
int x;占用4字节。 - 非静态数据成员
short y;占用2字节。 - 虚函数表指针(vptr):对于包含虚函数的类,每个对象都会有一个指向虚函数表的指针,通常占用4字节或8字节(取决于平台)。
- 虚函数
void func1();和void func2();的存在会在虚函数表中占用额外空间,但不会直接影响类的大小。 - 其他非静态函数不会影响类的大小。
在32位平台上,MyClass 类的大小为 4(int x) + 2(short y) + 4(虚函数表指针) = 10 字节。
4、map、set底层,讲讲红黑树,为什么不用哈希表。go字典的底层?
在C++中,std::map 和 std::set 通常使用红黑树作为底层数据结构,而不是哈希表。这是因为红黑树有着良好的平衡性能,在有序性和插入/删除操作的效率之间取得了一个很好的平衡。
红黑树是一种自平衡的二叉查找树,具有以下特性:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色的。
- 每个叶子节点(NIL节点,空节点)是黑色的。
- 如果一个节点是红色的,则它的子节点必须是黑色的(反之不一定成立)。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
红黑树的平衡性质保证了在最坏情况下,查找、插入和删除操作的时间复杂度为 O(log n),其中 n 是树中元素的数量。相比之下,哈希表在理想情况下具有 O(1) 的插入、删除和查找时间复杂度,但在最坏情况下可能达到 O(n)。此外,红黑树提供了有序性,可以方便地进行区间查找和遍历操作。
Go语言中的字典(map)使用了一种称为哈希表的数据结构作为底层实现。哈希表通过将键映射到存储桶(bucket)中的位置来实现快速的查找、插入和删除操作。在Go语言中,哈希表使用了开放定址法和链表结构来解决哈希冲突,当链表长度超过一定阈值时,会将链表转换为红黑树,以提高性能。
5、红黑树如何把key从整型换成类,需要overwrite哪些?
- 比较函数的重写: 红黑树需要比较键的大小来进行插入、查找等操作。当键由整型换成类时,需要重写类的比较函数,使其能够比较两个键的大小。通常需要实现
<、>、==等比较操作符,或者提供自定义的比较函数。 - 哈希函数的重写: 如果使用哈希表来实现红黑树,需要重写类的哈希函数,将键转换为哈希值。哈希函数的设计需要考虑到哈希值的均匀分布,以提高哈希表的性能。
- 节点结构的修改: 红黑树的节点结构通常包括键、值、颜色和指向子节点的指针等信息。当键由整型换成类时,节点结构需要修改,将整型键替换为类对象。同时,需要保留节点的值、颜色和指针等信息。
- 插入、删除和查找操作的修改: 需要根据新的键类型重写插入、删除和查找操作。这些操作需要根据键的大小来决定节点的插入位置、删除方式和查找路径。
- 平衡性维护的修改: 红黑树需要保持平衡性质,插入和删除操作可能会破坏平衡,需要进行旋转等操作来恢复平衡。当键由整型换成类时,需要根据新的键类型进行平衡性维护的修改。
6、bss和data区别,static放在哪,static未初始化放在哪?
- bss段: bss段用于存储未初始化的全局变量和静态变量。在程序加载时,操作系统会将bss段中的变量初始化为0或空值(对于不同编译器和系统可能有所不同)。bss段不占用可执行文件的存储空间,而是在程序加载时由操作系统分配。因此,bss段中的变量在可执行文件中并不占用实际空间,只是在程序运行时分配空间。
- data段: data段用于存储已经初始化的全局变量和静态变量。在程序加载时,操作系统会将data段中的变量初始化为指定的值。与bss段不同,data段中的变量在可执行文件中占用实际空间,因为它们的初始值已经在编译时确定。
- static关键字: 在C/C++中,static关键字用于声明静态变量和函数。静态变量可以放在bss段或data段中,取决于是否进行了初始化。如果静态变量进行了初始化,则存储在data段;如果未进行初始化,则存储在bss段。
- 未初始化的静态变量: 未初始化的静态变量(即在声明时未指定初始值的静态变量)存储在bss段中。当程序加载时,操作系统会将bss段中的未初始化静态变量初始化为0或空值。
7、进程和线程,nginx怎么做多进程,进程通信方式,mmap可以做共享内存吗?
- 进程(Process): 进程是程序的一次执行过程,是操作系统进行资源分配和调度的基本单位。每个进程拥有独立的内存空间、数据栈以及其他资源,进程间相互独立,需要通过进程间通信(IPC,Inter-Process Communication)来进行数据交换和同步。Nginx采用多进程模型来处理客户端请求,每个进程负责处理一部分请求。
- 线程(Thread): 线程是进程的一个执行流,是操作系统能够进行运算调度的最小单位。线程共享所属进程的内存空间和资源,不同线程间可以直接访问共享数据,但也需要考虑线程同步和互斥的问题。线程通常比进程轻量,创建和切换的开销较小。
- 进程间通信方式: 进程间通信有多种方式,包括管道、信号、消息队列、共享内存和套接字等。在Nginx中,多个进程通过共享一个文件描述符来实现进程间通信,可以通过文件锁(flock)等机制来实现进程间的同步和互斥。
- mmap和共享内存: mmap是一种将文件或设备映射到内存的方法,可以实现文件和内存之间的直接映射。共享内存是一种特殊的内存映射,允许多个进程共享同一块物理内存,从而实现进程间的数据共享。在Linux系统中,可以使用mmap系统调用来创建共享内存区域,多个进程可以将同一文件映射到各自的地址空间,实现数据的共享和通信。在Nginx中,也可以使用共享内存来实现进程间的通信和数据共享。
8、关系型数据库特点,redis过期管理,定时器原理?
关系型数据库的特点:
- 数据以表格的形式存储,表格由行和列组成,每行代表一个记录,每列代表一个属性。
- 支持 SQL(Structured Query Language)作为查询语言,可以方便地进行数据查询和操作。
- 支持事务(Transaction)的概念,保证数据的一致性和完整性。
- 支持 ACID(原子性、一致性、隔离性、持久性)特性,保证数据的可靠性和安全性。
- 支持复杂的数据模型和关联查询,适用于处理复杂的数据结构和关系。
Redis过期管理: Redis中可以通过设置过期时间(expire)来管理键值对的过期时间,当键值对的过期时间到达时,Redis会自动删除该键值对。过期时间可以通过EXPIRE命令设置,也可以在设置键值对时直接指定过期时间。Redis使用定期删除(定时器)和惰性删除两种方式来管理过期键值对。定期删除是指Redis每隔一段时间会随机检查一部分键值对的过期时间,删除已过期的键值对。惰性删除是指在获取键值对时,Redis会先检查该键值对是否过期,如果过期则删除。
定时器原理: 定时器通常由操作系统提供,用于在指定的时间间隔内执行某个操作或触发某个事件。在Linux系统中,定时器通常是通过系统调用timer_create创建一个定时器对象,然后通过timer_settime设置定时器的触发时间和间隔。定时器可以是相对时间(相对于当前时间的时间间隔)或绝对时间(具体的时间点)。定时器的触发通常是通过信号(如SIGALRM)来实现的,当定时器到达指定的时间时,操作系统会发送信号给应用程序,应用程序可以通过信号处理函数来处理定时器触发事件。
9、tcp和udp区别,tcp如何解析json,udp会考虑这个问题吗?
区别
- 连接性:TCP是面向连接的协议,建立连接后进行数据传输,保证数据的可靠性和顺序性;而UDP是无连接的协议,发送数据时不需要建立连接,也不保证数据的可靠性和顺序性。
- 数据传输方式:TCP使用流式传输,数据被分割成TCP报文段进行传输,保证数据的完整性;UDP使用数据报传输,每个UDP数据包(数据报)独立传输,不保证数据的完整性。
- 重传机制:TCP具有重传机制,当数据丢失或损坏时会进行重传,保证数据的可靠性;UDP不具有重传机制,一旦数据丢失或损坏就会丢失。
- 面向应用:TCP适用于对数据可靠性要求较高的应用,如文件传输、网页访问等;UDP适用于对实时性要求较高的应用,如音视频传输、在线游戏等。
解析JSON数据通常是在应用层完成的,与传输层协议无关。在TCP中,接收到的数据可以按照JSON格式解析;在UDP中,同样可以接收到JSON格式的数据,但由于UDP不保证数据的完整性,可能需要应用层自行处理丢失或损坏的数据。
10、反转链表
思路
这里给大家讲最经典的双指针法。
- 如果链表为空或者只有一个节点,直接返回头结点head。
- 初始化 pre 为 nullptr,cur 为头结点 head,node 为 cur 的下一个节点。
- 在循环中,不断更新 pre、cur 和 node 的值,使得 cur 的 next 指向 pre,然后将 pre、cur 和 node 分别向后移动一位。
- 当 cur 移动到链表末尾时,pre 就是反转后的新头结点。
演示过程:
初始状态:

第一步:
先定义一个空节点并初始化为nullptr,分别将这两个指针指向这个空节点和头结点,再定义一个节点用来临时存放节点。
ListNode* pre = nullptr; // 初始化 pre 为 nullptr
ListNode* cur = head; // 初始化 cur 为头结点
ListNode* node = nullptr; // 初始化 node 为 nullptr

第二步:
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转

第三步:
pre = cur; // 更新 pre
cur = node; // 更新 cur

到这里,其实我们就可以使用一个循环,让继续这两步操作。不过为了大家更加看明白,我就将这个示例画完吧。
第四步:
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转

第五步:
pre = cur; // 更新 pre
cur = node; // 更新 cur

第六步:
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转

第七步:
pre = cur; // 更新 pre
cur = node; // 更新 cur

第八步:
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转

第九步:
pre = cur; // 更新 pre
cur = node; // 更新 cur

第十步:
node = cur->next; // 保存当前节点的下一个节点
cur->next = pre; // 当前节点的 next 指向 pre,完成反转

第十一步:
pre = cur; // 更新 pre
cur = node; // 更新 cur
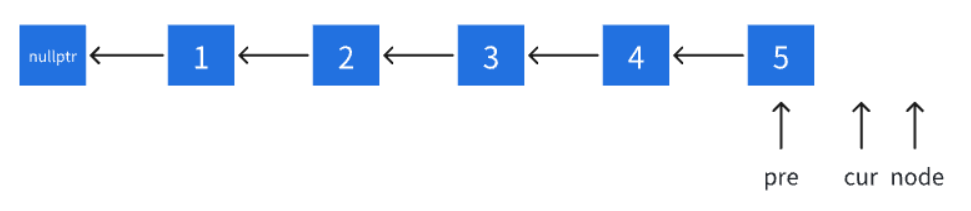
此时cur==nullptr,退出循环。
参考代码
C++
#include <iostream>struct ListNode {int val;ListNode* next;ListNode(int x) : val(x), next(nullptr) {}
};class Solution {
public:ListNode* reverseList(ListNode* head) {if (head == nullptr || head->next == nullptr) {return head; // 如果链表为空或者只有一个节点,直接返回头结点}ListNode* pre = nullptr; // 初始化 pre 为 nullptrListNode* cur = head; // 初始化 cur 为头结点ListNode* node = nullptr; // 初始化 node 为 nullptrwhile (cur != nullptr) {node = cur->next; // 保存当前节点的下一个节点cur->next = pre; // 当前节点的 next 指向 pre,完成反转pre = cur; // 更新 precur = node; // 更新 cur}return pre; // pre 就是反转后的新头结点}
};int main() {ListNode* head = new ListNode(1);head->next = new ListNode(2);head->next->next = new ListNode(3);Solution solution;ListNode* newHead = solution.reverseList(head);while (newHead != nullptr) {std::cout << newHead->val << " ";newHead = newHead->next;}return 0;
}
这篇关于后端开发面经系列 -- 滴滴C++一面面经的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






