本文主要是介绍从tflearn Example中学习CNN(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本人水平有限,难免会有错误,如果发现希望可以及时指出来,利人利己。哈哈哈~这是博客写的第一篇文章,主要想从tflearn的例子代码一步步理解CNN模型。这里插一句话,tflearn是tensorflow接口的更高层次的封装,与keras的区别时debug时可以看到源码,并且tflearn代码写的非常工整,适合我这样的菜鸟学习。
现在深度学习异常火热,如果不会点深度学习,出门都不好意思和人家打招呼。
这篇博客主要讲解下tflearn例子里的examples/images/convnet_mnist.py,对于每个函数中涉及的参数我会一一的给出中文说明,下一篇主要讲解每个参数在CNN中的含义,以及系统讲解下CNN的构建过程。废话不多说,先看代码。
- from __future__ import division, print_function, absolute_import
- import tflearn
- from tflearn.layers.core import input_data, dropout, fully_connected
- from tflearn.layers.conv import conv_2d, max_pool_2d
- from tflearn.layers.normalization import local_response_normalization
- from tflearn.layers.estimator import regression
- #加载大名顶顶的mnist数据集(http://yann.lecun.com/exdb/mnist/)
- import tflearn.datasets.mnist as mnist
- X, Y, testX, testY = mnist.load_data(one_hot=True)
- X = X.reshape([-1, 28, 28, 1])
- testX = testX.reshape([-1, 28, 28, 1])
- network = input_data(shape=[None, 28, 28, 1], name='input')
- # CNN中的卷积操作,下面会有详细解释
- network = conv_2d(network, 32, 3, activation='relu', regularizer="L2")
- # 最大池化操作
- network = max_pool_2d(network, 2)
- # 局部响应归一化操作
- network = local_response_normalization(network)
- network = conv_2d(network, 64, 3, activation='relu', regularizer="L2")
- network = max_pool_2d(network, 2)
- network = local_response_normalization(network)
- # 全连接操作
- network = fully_connected(network, 128, activation='tanh')
- # dropout操作
- network = dropout(network, 0.8)
- network = fully_connected(network, 256, activation='tanh')
- network = dropout(network, 0.8)
- network = fully_connected(network, 10, activation='softmax')
- # 回归操作
- network = regression(network, optimizer='adam', learning_rate=0.01,
- loss='categorical_crossentropy', name='target')
- # Training
- # DNN操作,构建深度神经网络
- model = tflearn.DNN(network, tensorboard_verbose=0)
- model.fit({'input': X}, {'target': Y}, n_epoch=20,
- validation_set=({'input': testX}, {'target': testY}),
- snapshot_step=100, show_metric=True, run_id='convnet_mnist')
关于conv_2d函数,在源码里是可以看到总共有14个参数,分别如下:
1.incoming: 输入的张量,形式是[batch, height, width, in_channels]
2.nb_filter: filter的个数
3.filter_size: filter的尺寸,是int类型
4.strides: 卷积操作的步长,默认是[1,1,1,1]
5.padding: padding操作时标志位,"same"或者"valid",默认是“same”
6.activation: 激活函数(ps:这里需要了解的知识很多,会单独讲)
7.bias: bool量,如果True,就是使用bias
8.weights_init: 权重的初始化
9.bias_init: bias的初始化,默认是0,比如众所周知的线性函数y=wx+b,其中的w就相当于weights,b就是bias
10.regularizer: 正则项(这里需要讲解的东西非常多,会单独讲)
11.weight_decay: 权重下降的学习率
12.trainable: bool量,是否可以被训练
13.restore: bool量,训练的模型是否被保存
14.name: 卷积层的名称,默认是"Conv2D"
关于max_pool_2d函数,在源码里有5个参数,分别如下:
1.incoming ,类似于conv_2d里的incoming
2.kernel_size:池化时核的大小,相当于conv_2d时的filter的尺寸
3.strides:类似于conv_2d里的strides
4.padding:同上
5.name:同上
看了这么多参数,好像有些迷糊,我先用一张图解释下每个参数的意义。
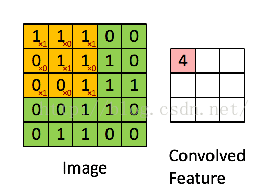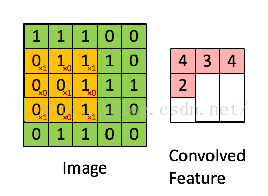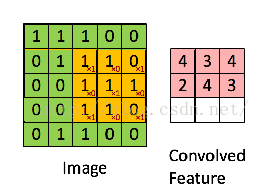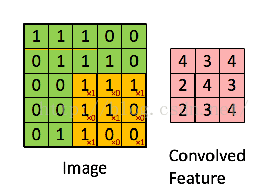
其中的filter就是[1 0 10 1 01 0 1],size=3,由于每次移动filter都是一个格子,所以strides=1.关于最大池化可以看看下面这张图,这里面 strides=1,kernel_size =2(就是每个颜色块的大小),图中示意的最大池化(可以提取出显著信息,比如在进行文本分析时可以提取一句话里的关键字,以及图像处理中显著颜色,纹理等),关于池化这里多说一句,有时需要平均池化,有时需要最小池化。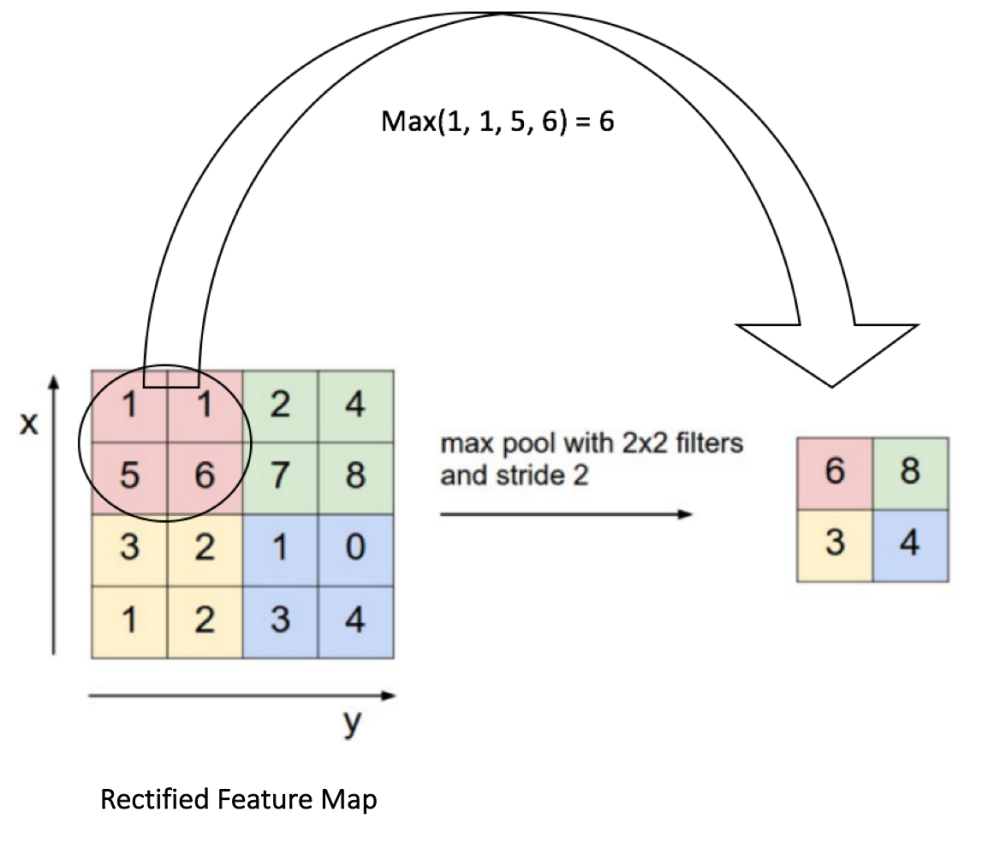
下面说说其中的padding操作,做图像处理的人对于这个操作应该不会陌生,说白了,就是填充。比如你对图像做卷积操作,比如你用的3×3的卷积核,在进行边上操作时,会发现卷积核已经超过原图像,这时需要把原图像进行扩大,扩大出来的就是填充,基本都填充0。一下关于padding的操作转自:http://www.jianshu.com/p/05c4f1621c7e
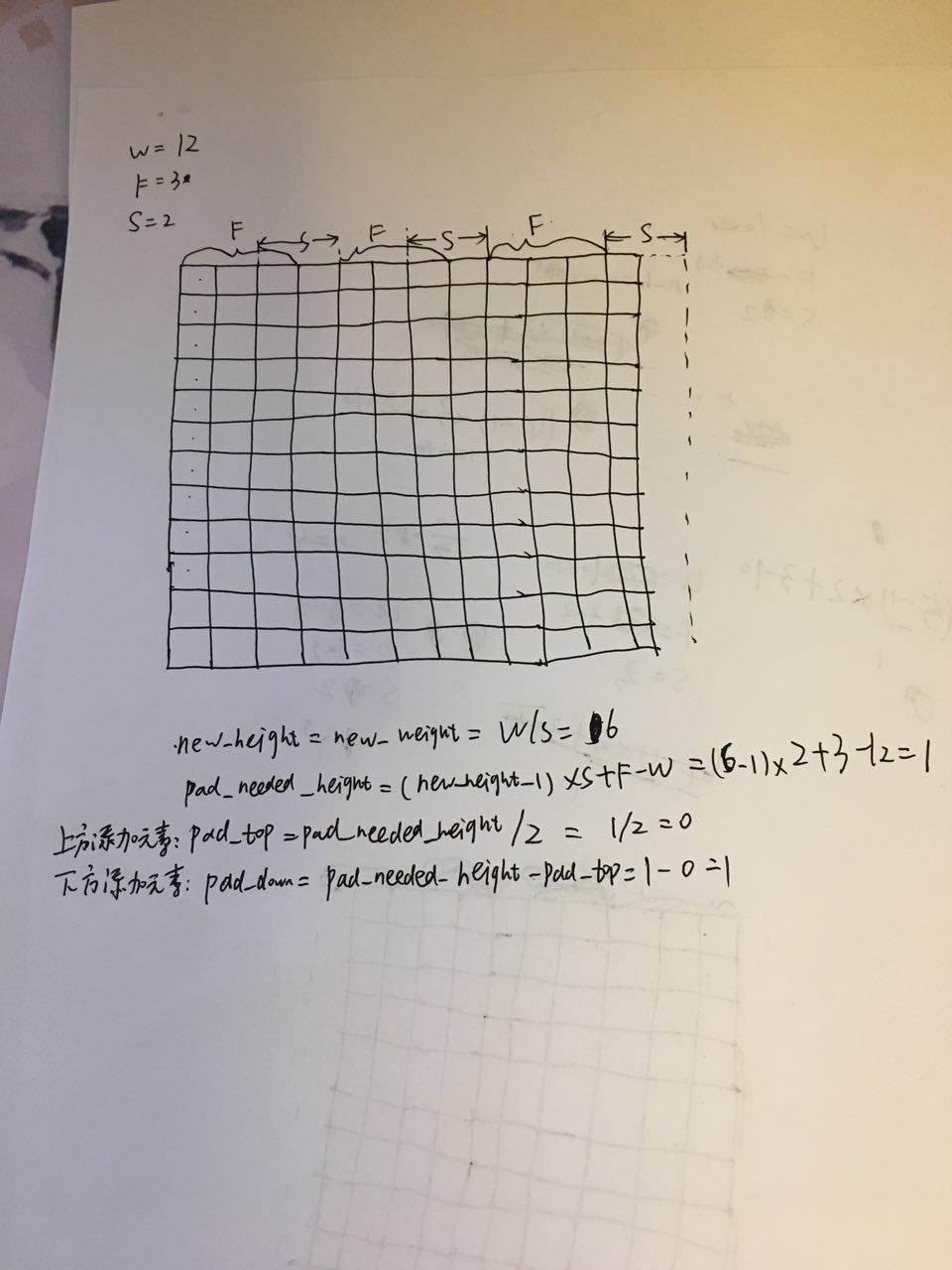
1.输入W×W的矩阵,(这里讨论长宽相等情况,不相等的话,推导方法有区别),现在想象一下脑子里有一副W*W的图像
2.假定filter的大小是F×F,卷积核
3.步长stride为S
4.输出的宽高为new_w,new_h
上面已经提到padding总共有两种方式,same,valid
当取valid时
new_weight=new_height=(W-F+1)/S(结果向上取整),
此时输出的矩阵大小比输入时小(这里不讨论F=1时的情况,说到1*1的卷积核,大家可以看看GoogLeNet模型,其中用到1*1卷积核,这个用来降维的,tflearn代码里有GoogLeNet的复现)
当取same时,
new_height = new_weight= W/S(结果向上取整)
在高度上需要pad的像素数为
pad_needed_height = (new_height – 1) × S + F - W
根据上式,输入矩阵上方添加的像素数为
pad_top = pad_needed_height / 2 (结果取整)
下方添加的像素数为
pad_down = pad_needed_height - pad_top
以此类推,在宽度上需要pad的像素数和左右分别添加的像素数为
pad_needed_width = (new_width – 1) × S + F - W
pad_left = pad_needed_width / 2 (结果取整)
下面看图示以及计算过程:pad_right = pad_needed_width – pad_left
参考文献:
这篇关于从tflearn Example中学习CNN(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








