本文主要是介绍Hyperledger Fabric(1) - 整体架构和源码结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.背景
目前区块链处在一个底层蓬勃发展和尝试应用落地的阶段。从业务分类上大致可将区块链分为公链(BTC/ETH/EOS)、联盟链(Hyperledger Fabric)和私有链(自己使用)。
公链可理解为与币圈挂钩,也是笔者一直所在的行业,目前天朝对币圈的政策可谓是不鼓励不反对。从近几年来,国家都在鼓励区块链的发展,其实是对联盟链一个很大的鼓励信号。
由于联盟链的出发点是解决一些行业的溯源、去信任、公开透明等问题,所以某种程度上是不需要所谓的通证(Token)来进行系统激励,特别地联盟链引入许可机制,所以架构上同大多数公链相差比较大。最近本身工作的问题,有在接触和了解到Hyperledger Fabric这个项目。所以从现有资料和源码入手,分析项目的架构和部分细节。
2. 资料和源码
2.1. hyperledger-fabric Github仓库
2.2. hyperledger-fabric 开发者文档
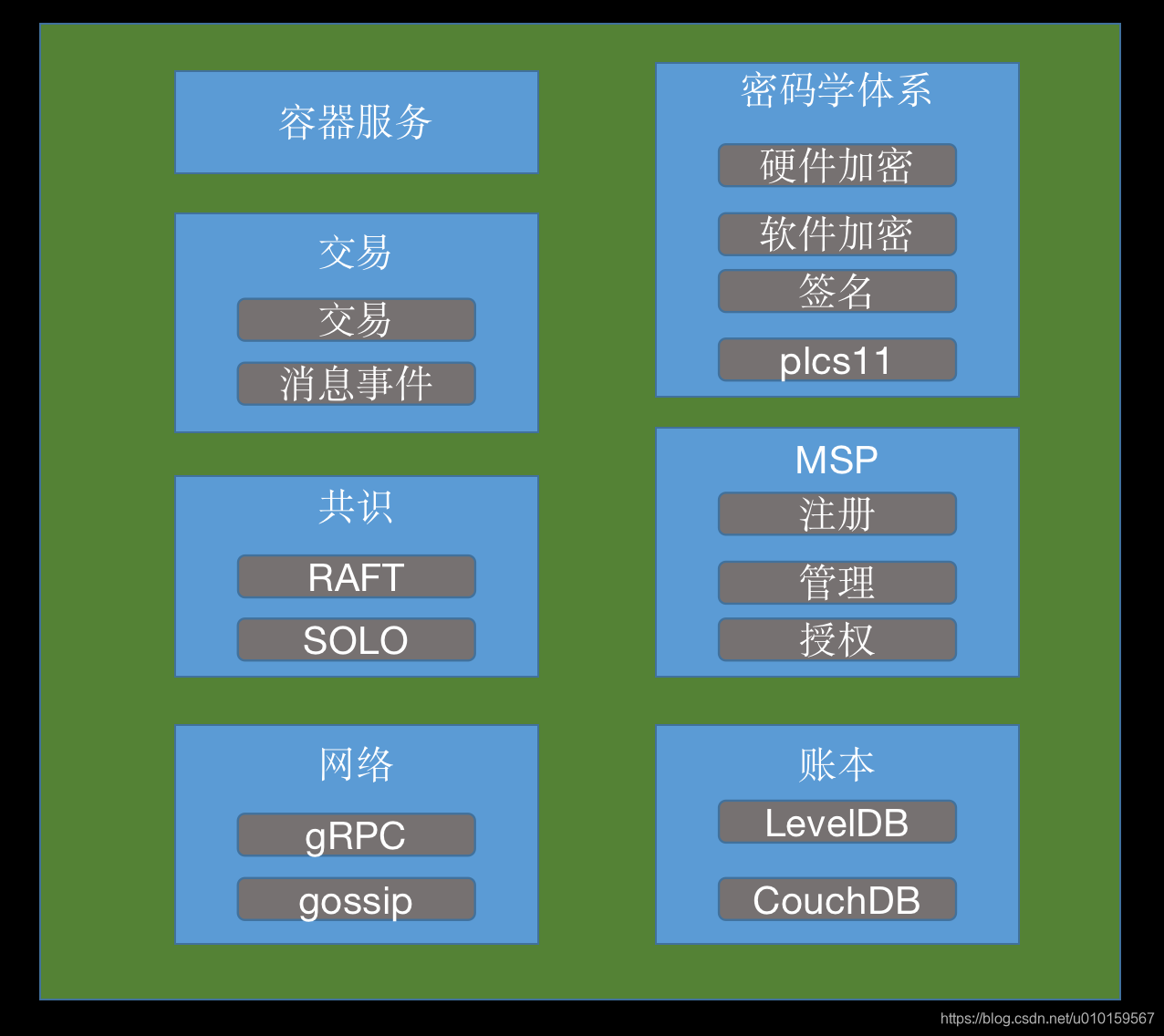
3. 整体架构
3.1 系统架构
4.代码目录结构
如下为fabric 2.0代码目录结构和功能说明
wujinquan@wujinquandeMacBook-Pro ~/workspace/gospace/src/github.com/hyperledger/fabric tree -L 1
.
├── CHANGELOG.md
├── CODEOWNERS
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Gopkg.lock
├── Gopkg.toml
├── LICENSE
├── MAINTAINERS.md
├── Makefile
├── README.md
├── SECURITY.md
├── bccsp //密码学相关,用于签名、加密等
├── ci //常用脚本文件
├── ci.properties
├── cmd //项目命令行,可从此目录入手了解整个项目,包含节点的启动、功能配置、停止等操作
├── common //公用代码
├── core //项目的核心代码,包含包括权限控制、 chaincode 、committer、 endorser、 ledger、 等功能 代码实现
├── discovery //为客户端程序提供服务发现的功能
├── docker-env.mk
├── docs
├── go.mod
├── gossip //是 Fabric 在节点间达成最终一致性, 实现的信息传播的模块
├── gotools.mk
├── idemix
├── images
├── integration
├── internal
├── msp //全称为 Membership service provider ,为 Fabric 提供成员服务
├── orderer //进行全局的交易排序以及切块
├── pkg
├── protoutil
├── release_notes
├── sampleconfig//配置示例
├── scripts //常见脚本
├── test-pyramid.png
├── testingInfo.rst
├── tox.ini
├── vagrant
└── vendor //Golang 第三方包管理器21 directories, 18 fileswujinquan@wujinquandeMacBook-Pro ~/workspace/gospace/src/github.com/hyperledger/fabric
5. 节点概念
节点: 是区块链的通信实体,是一个逻辑概念,不同类型的多个节点可以运行在同一个物理服务器上。节点主要有以下四种:
5.1 客户端节点
客户端必须连接到某一个peer节点或排序服务节点上才能与区块链网络进行通信。客户端向背书节点(endorser)提交交易提案(transaction proposal),当收集到足够背书后,向排序服务节点广播交易提案,进行排序,生成区块。
5.2 节点peer
peer节点根据所承担的角色又可以分为记账节点(committer)、背书节点(endorser)、主节点(leader)和锚节点(anchor)。
5.2.1 记账节点
所有的peer节点都是记账节点(committer),负责验证排序服务节点区块里的交易,维护状态和总账(Ledger)的副本。该节点会定期从orderer节点获取包含交易的区块,在对这些区块进行核发验证之后,会把这些区块加入到区块链中。committer节点无法通过配置文件配置,需要在当前客户端或者命令行发起交易请求的时候手动指定相关的committer节点。记账节点可以有多个。
5.2.2 背书节点
部分节点还会执行交易并对结果进行签名背书,充当背书节点(endorser)的角色。背书节点是动态的角色,是与具体链码绑定的。每个链码在实例化的时候都会设置背书策略,指定哪些节点对交易背书后交易才是有效的。并且只有应用程序向它发起交易背书请求的时候才是背书节点,其他时候都是普通的记账节点,只负责验证交易并记账。背书节点也无法通过配置文件指定,而是由发起交易请求的客户端指定。背书节点可以有多个。
5.2.3 锚节点
peer节点还可以是锚节点(anchor peer),锚节点主要负责代表组织和其他组织进行信息交换。每个组织都有一个锚节点,锚节点对于组织来说非常重要,如果锚节点出现问题,当前组织就会与其他组织失去联系。锚节点的配置信息是在configtxgen模块的配置文件configtx.yaml中配置的。锚节点只能有一个。
5.2.4 主节点
peer节点还可以是主节点(leader peer),能与排序服务节点通信,负责从排序服务节点获取最新的区块并在组织内部同步。主节点在整个组织中只能有一个。
5.3 排序服务节点orderer
接收包含背书签名的交易,对未打包的交易进行排序生成区块,广播给peer节点。排序服务提供的是原子广播,保证同一个链上的节点接收到相同的信息,并且有相同的逻辑顺序。
5.4 CA节点
fabric1.0的证书颁发机构,由服务器和客户端组成。CA节点接收客户端的注册申请,返回注册密码用于用户登录,以便获取身份证书。区块链上的所有操作都需要验证用户身份。
6. 交易流程
至此,文章尚未介绍Fabric项目是如何运行起来的,不管是公链还是联盟链,一个基本的交易流程,其实就代表了整体的流程的大部分。所以从一个交易入手来分析区块链是最好的一种办法。从这个角度看整个链,会有一个相当清晰的脉络把握。
Fabric的正常交易流程是基于整个 Fabric 网络已 经搭建完 ,并正常运行的前提下用户已经注册并且使用组织认证授权(CA)登记 ,同时获得 的加密材料来进行网络验链码被安装在节点上并在通道上进行实例化,链码包含定义交易指令集合的逻辑并设置一项针对链码的背书策略,表明哪些节点需要为交易进行背书。

如上图所示,一个交易基本可以分为以下八步
6.1 提交交易提案
应用程序(客户端节点)构造好交易提案(交易提案中包含本次交易要调用的合约标识、合约方法和参数信息以及客户端签名等)请求后,根据背书策略选择背书节点执行交易提案并进行背书签名。背书节点是链代码中背书策略指定的节点。正常情况下背书节点执行后的结果是一致的,只有背书节点对结果的签名不一样。
6.2 模拟执行提案并进行背书
背书节点在收到交易提案后会进行一些验证,验证通过后,背书节点会根据当前账本数据模拟执行链码中的业务逻辑并生成读写集(RwSet)。模拟执行时不会更新账本数据。然后背书节点对这些读写集进行签名生成提案响应(proposal response),然后返回给应用程序。
6.3 收集交易的背书(返回模拟执行结果)
应用程序收到proposal response后会对背书节点的签名进行验证(所有节点接收到任何消息时都需要先验证消息的合法性)。如果链码只进行账本查询操作,应用程序只需要检查查询响应,并不会将交易提交给排序服务节点。如果链码对账本进行了invoke操作,则需要提交交易给排序服务进行账本更新(提交前会判断背书策略是否满足)。
6.4 构造交易请求并发送给排序服务节点
应用程序接收到所有背书节点的签名后,根据背书签名调用SDK生成交易,并广播给排序服务节点。其中生成交易的过程很简单,只需要确认所有背书节点的执行结果完全一致,再将交易提案、提案响应和背书签名打包生成交易即可。
6.5 排序服务节点对交易进行排序并生成区块
排序服务节点接收到网络中所有通道发出的交易信息,读取交易信封获取通道名称,按各个通道上交易的接收时间顺序对交易信息进行排序(多通道隔离),生成区块。(在这个过程中,排序服务节点不会关心交易是否正确,只是负责排序和打包。交易的有效性在第7步进行验证)
6.6 排序服务节点广播区块给主节点
排序服务节点生成区块后会广播给通道上不同组织的主节点。
6.7 记账节点验证区块内容并写入到账本
所有的peer节点都是记账节点,记录的是节点已加入通道的账本数据。记账节点接收到的排序服务节点生成的区块后,会验证区块交易的有效性,然后提交到本地账本并产生一个生成区块的事件,监听区块事件的应用程序会进行后续的处理。(如果接收的是配置区块,则会更新缓存的配置信息)
6.8 主节点在组织内部同步最新的区块
如果交易是无效的,也会更新区块,但不会更新世界状态。(区块存储的是操作语句,而世界状态存储的是被处理的数据)
7. 源码细节解析
请见下文
Hyperledger Fabric(2) - 源码分析之Config 配置模块的设计
这篇关于Hyperledger Fabric(1) - 整体架构和源码结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






