本文主要是介绍Python科学计算库 — Pandas数学统计方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先导入pandas库
import numpy as np
import pandas as pd
Pandas 常用的数学统计方法如下表:
| 方法 | 说明 |
|---|---|
| count | 计算非NA值的数量 |
| describe | 针对Series 或DataFrame 列计算总的统计值 |
| min/max | 计算最大值/最小值 |
| idxmin/idxmax | 计算能够获取到最大值/最小值的索引(整数) |
| argmin/argmax | 计算能够获取到最小值和最大值的索引值 |
| quantile | 计算样本的分位数(0到1) |
| sum | 值的总和 |
| mean | 值的平均数 |
| median | 值的中位数 |
| mad | 根据平均值计算平均绝对距离差 |
| var | 样本方差 |
| std | 样本标准差 |
| cumsum | 样本值的累计和 |
| cummin/cummax | 样本的累计最小值/累计最大值 |
| cumprod | 样本值的累计积 |
| pct_change | 计算百分数变化 |
※ 以上统计方法默认对列进行统计;如果要对每一行数据进行统计,应设置axis=1。
Example:
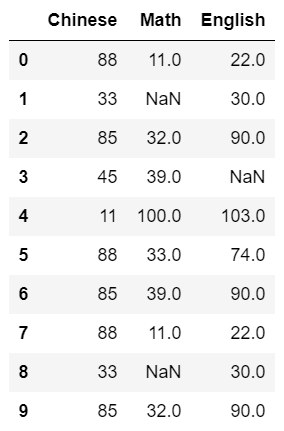
1、df.count(axis=0):默认统计每一列非NA值的个数;axis=1 表示统计每一行非NA值的个数。
2、df.describe():对每一列数据做完整的数据统计,统计值包括:count、mean、std、min、max等。注:只能对列,不能对行进行统计!
3、df.idxmin(),df.idxmax(): 获取最小值,最大值对应的索引值
4、df.sum(axis=0):求和,默认对每一列求和;axis=1表示对每一行求和。
5、df.mean(axis=0):求每一列的平均值;axis=1表示求每一行的平均值。
6、df.median(axis=0),df.quantile(axis=0):求每一列数据的中位数
info = pd.read_csv("./student_info.csv")
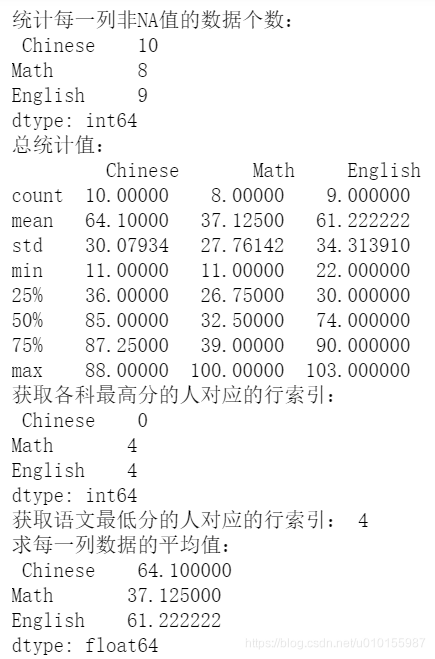
print("统计每一列非NA值的数据个数:\n", info.count())
# print("统计每一行非NA值的数据个数:\n", info.count(axis=1))
# axis=1 表示统计每一行
print("总统计值:\n", info.describe())
print("获取各科最高分的人对应的行索引:\n", info.idxmax())
print("获取语文最低分的人对应的行索引:", info.idxmin()['Chinese'])
print("求每一列数据的平均值:\n", info.mean())
print("求每一列数据的中位数:\n", info.median())
输出结果:
7、df.mad():平均绝对距离差:(绝对值(数值-平均值))的平均值,表征数据的离散程度。
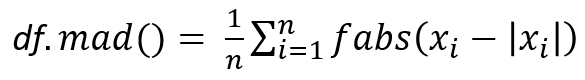
8、df.var():方差
9、df.std():标准差
方差和标准差都是表征数据的离散程度。
10、df.cumsum():累计和,cs1=a1, cs2=cs1+a2, cs3=cs2+a3, …
11、df.cummax(),df.cummin():累计最大值,累计最小值 从前向后比较,如果有更大(小)的就更新,没有就保持。
12、df.cumprod(): 累计积
13、df.pct_change():计算百分比变化,和前一个数据对比
14、相关系数和协方差:ser1.cov(ser2),反映两组数据之间的相关性和相关程度。
这篇关于Python科学计算库 — Pandas数学统计方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




