本文主要是介绍Obsidian dataview 使用入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Dataview有四种展示格式:list、table、task、calendar。 本文只介绍前面两种。
语法总结
通过#标签
```dataview
LIST FROM #标签
```
通过"文件夹"
```dataview
LIST FROM "文件夹名"
```
通过[ [ 文件链接 ] ]
选择链接到一个文件,或者从一个文件获取所有链接,即,获取反向链接或者出链
```dataview
LIST FROM[[文件链接]]
```
或着
```dataview
list from outgoing([[文件链接]])
```
表格 table
```dataview
table FROM "文件夹名"
```
任务 task
```dataview
task FROM "文件夹名"
```
示例说明
元数据
所有笔记中都有隐含元数据,下面属性值都可以在Dataview查询中直接引用。
| 属性 | 值 | 类型 |
|---|---|---|
file.name | 文件 标题 | 字符串 |
file.path | 完整文件 路径 | 字符串 |
file.link | 文件的 链接 | 链接 |
file.size | 文件的 大小(以字节为单位) | 数字 |
file.ctime | 文件 创建 日期 | 日期 |
file.mtime | 文件上次 修改 日期 | 日期 |
file.day | 笔记标题中包含的 日期 | 日期 |
file.tags | 笔记中所有 标签 的 数组 | 数组 |
1. 创建示例笔记
除了上面笔记自带的元数据属性,我们还可以手动添加元数据,有两种方式:1)添加文档属性;2)行内添加。
示例:
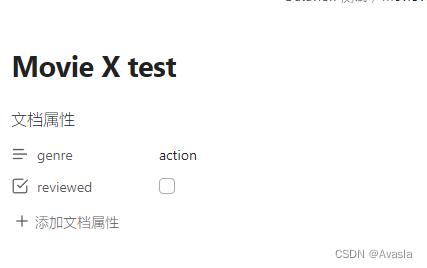
- 新建两页笔记Movie X test 和 Movie X test2,
- 在笔记里复制粘贴下面内容,可以自己编辑修改:
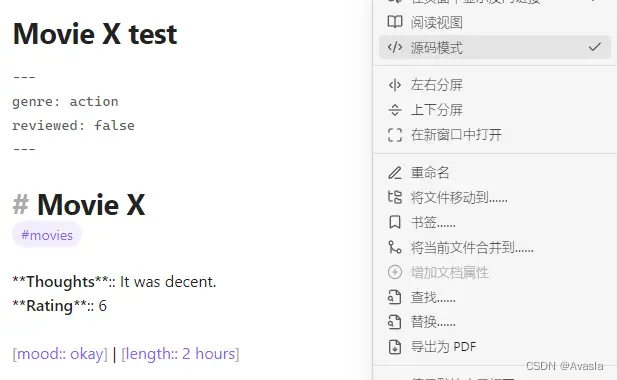
---
genre: "action"
reviewed: false
---
# Movie X
#movies **Thoughts**:: It was decent.
**Rating**:: 6 [mood:: okay] | [length:: 2 hours]
1. 增加文档属性
| 手动增加文档属性 |
|---|
 |
| 属性添加后如下: |
 |
| 勾选源码模式查看:文档内会显示源码 |
 |
2. 行内元数据
-
使用
::添加 -
直接使用时,一行只能添加一个元数据。
![![[Dataview test-20240506112528452.webp|240]]](https://img-blog.csdnimg.cn/direct/fc60922ff549491e838e57b8773724fb.png)
-
在[ ]内使用,这种方法可以在同一行或者一段文字内添加多种属性数据。
![![[Dataview test-20240506112559491.webp]]](https://img-blog.csdnimg.cn/direct/a37a69ee742e497ca459801da0657d68.png)
Dataview 查询示例:
通过标签查询,以table格式
```dataview
TABLE file.ctime, length, rating, reviewed,genre FROM #movies
```

通过标签查询,以list格式
```dataview
LIST FROM #movies
```

其他文件字段
| Field Name | Data Type | Description |
|---|---|---|
file.name | Text | The file name as seen in Obsidians sidebar. |
file.folder | Text | The path of the folder this file belongs to. |
file.path | Text | The full file path, including the files name. |
file.ext | Text | The extension of the file type; generally md. |
file.link | Link | A link to the file. |
file.size | Number | The size (in bytes) of the file. |
file.ctime | Date with Time | The date that the file was created. |
file.cday | Date | The date that the file was created. |
file.mtime | Date with Time | The date that the file was last modified. |
file.mday | Date | The date that the file was last modified. |
file.tags | List | A list of all unique tags in the note. Subtags are broken down by each level, so #Tag/1/A will be stored in the list as [#Tag, #Tag/1, #Tag/1/A]. |
file.etags | List | A list of all explicit tags in the note; unlike file.tags, does not break subtags down, i.e. [#Tag/1/A] |
file.inlinks | List | A list of all incoming links to this file, meaning all files that contain a link to this file. |
file.outlinks | List | A list of all outgoing links from this file, meaning all links the file contains. |
file.aliases | List | A list of all aliases for the note as defined via the YAML frontmatter. |
file.tasks | List | A list of all tasks (I.e., | [ ] some task) in this file. |
file.lists | List | A list of all list elements in the file (including tasks); these elements are effectively tasks and can be rendered in task views. |
file.frontmatter | List | Contains the raw values of all frontmatter in form of key | value text values; mainly useful for checking raw frontmatter values or for dynamically listing frontmatter keys. |
file.day | Date | Only available if the file has a date inside its file name (of form yyyy-mm-dd or yyyymmdd), or has a Date field/inline field. |
file.starred | Boolean | If this file has been bookmarked via the Obsidian Core Plugin “Bookmarks”. |
官方说明文档:
Dataview
这篇关于Obsidian dataview 使用入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




