本文主要是介绍图数据库JanusGraph介绍及使用(三):安装与初步使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图数据库JanusGraph介绍及使用(三):安装与初步使用
说明:这是图数据库JanusGraph系列的第三篇,后面会陆续介绍。
图数据库JanusGraph介绍及使用(一):简介 https://blog.csdn.net/gobitan/article/details/80939224
图数据库JanusGraph介绍及使用(二):架构 https://blog.csdn.net/gobitan/article/details/80939276
3. JanusGraph安装与初步使用
环境:CentOS7 64位
3.1 JanusGraph下载
下载JanusGraph,https://github.com/JanusGraph/janusgraph/releases,当前(2018-07-05)版本为0.2.0,下载janusgraph-0.2.0-hadoop2.zip,263M。
3.2 Oracle JDK8安装
JanusGraph需要Java8,推荐使用Oracle Java8,并设置JAVA_HOME环境变量。因为较为简单,安装过程略。
3.3 JanusGraph安装
将拷贝到/opt目录下,然后执行如下操作:
[root@app opt]# unzip ~/janusgraph-0.2.0-hadoop2.zip
[root@app opt]# cd janusgraph-0.2.0-hadoop2/
[root@app janusgraph-0.2.0-hadoop2]# bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: janusgraph.imports
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/janusgraph-0.2.0-hadoop2/lib/slf4j-log4j12-1.7.12.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/janusgraph-0.2.0-hadoop2/lib/logback-classic-1.1.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
21:32:58 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
plugin activated: tinkerpop.hadoop
plugin activated: tinkerpop.spark
plugin activated: tinkerpop.tinkergraph
gremlin>
3.4 Gremlin控制台
Gremlin控制台解释器使用的是Apache Groovy,如下所示:
gremlin> 1+3
==>4
3.5 加载图数据
JanusGraph有个很有名的图数据案例,叫做"The Graph of the Gods",也称罗马诸神。JanusGraphFactory提供了静态的方法来加载图数据。默认情况下,JanusGraph使用Berkeley DB作为后端存储引擎,使用Elasticsearch作为索引引擎。
Gods图如下:
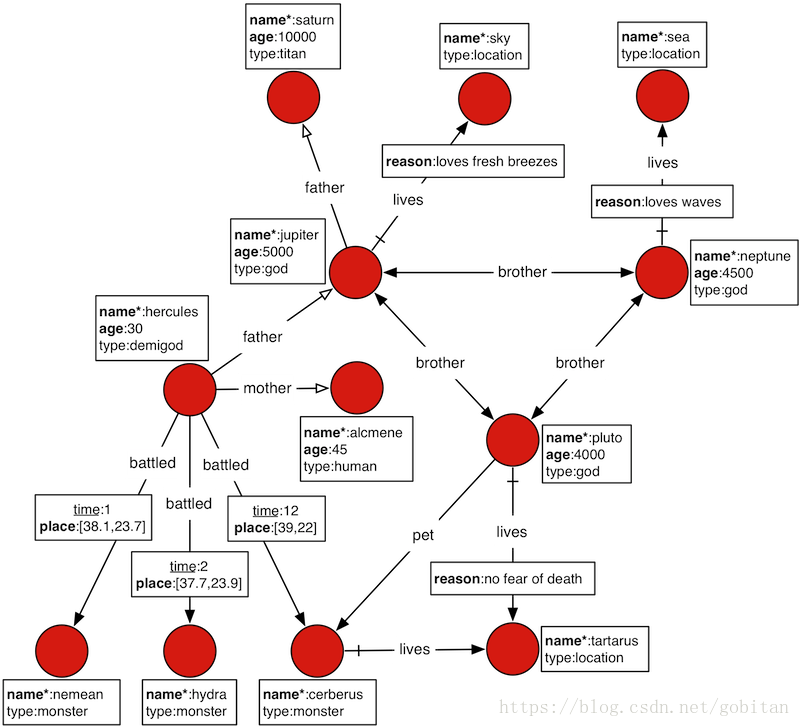
注意:在0.2.0版本中janusgraph-berkeleyje-es.properties不再支持ES的本地模式,但官方的文档未更新。因此,如果直接执行如下语句:
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
就会报类似这样的错误:Could not instantiate implementation: org.janusgraph.diskstorage.es.ElasticSearchIndex。
详细参见:https://groups.google.com/forum/#!topic/janusgraph-users/oWeMitqWCRk
这里,我采用的解决办法是自己安装一个Elasticsearch,安装方法很简单。
3.5.1 安装Elasticsearch
[root@centos7 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.rpm
[root@centos7 ~]# rpm -i elasticsearch-6.2.4.rpm
[root@centos7 ~]# systemctl daemon-reload
[root@centos7 ~]# systemctl enable elasticsearch
[root@centos7 ~]# systemctl start elasticsearch
检查Elasticsearch是否启动完成
[root@centos7 ~]# curl http://localhost:9200
注意:Elasticsearch启动需要一些时间,刚开始的时候curl可能返回连接被拒绝。
3.5.2 加载Gods图数据
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
==>standardjanusgraph[berkeleyje:/opt/janusgraph-0.2.0-hadoop2/conf/../db/berkeley]
gremlin> GraphOfTheGodsFactory.load(graph)
==>null
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[berkeleyje:/opt/janusgraph-0.2.0-hadoop2/conf/../db/berkeley], standard]
gremlin>
这一步将Gods图数据已经加载到了JanusGraph。
3.5.3 查询Gods图数据
假定在name属性上有唯一性约束。那么就可以找到Saturn顶点。如下所示:
查询顶点
gremlin> saturn = g.V().has('name', 'saturn').next()
==>v[4128]
查看Saturn顶点的值
gremlin> g.V(saturn).valueMap()
==>[name:[saturn],age:[10000]]
通过关系找到Saturn的孙子的名字
gremlin> g.V(saturn).in('father').in('father').values('name')
==>hercules
place属性也是一个索引,它是边的属性。因此,可以通过它查询发生在雅典(纬度:37.97和经度:23.72)50公里以内的素有事件,然后查出所有涉及到的顶点。如下所有:
gremlin> g.E().has('place', geoWithin(Geoshape.circle(37.97, 23.72, 50)))
==>e[4ck-6cg-9hx-39c][8224-battled->4224]
==>e[4qs-6cg-9hx-6dk][8224-battled->8264]
gremlin>
gremlin> g.E().has('place', geoWithin(Geoshape.circle(37.97, 23.72, 50))).as('source').inV().as('god2').select('source').outV().as('god1').select('god1', 'god2').by('name')
==>[god1:hercules,god2:nemean]
==>[god1:hercules,god2:hydra]
gremlin>
对图数据库和图计算感兴趣的朋友,欢迎加入"图数据库与图计算"QQ群:463749267,这里有很多志同道合的朋友跟你一起讨论Neo4j,JanusGraph,GraphX,Tinkerpop等等。
参考资料:
[1] http://janusgraph.org/ JanusGraph官方网址
[2] https://github.com/JanusGraph/janusgraph JanusGraph的github源码网址
[3] https://docs.janusgraph.org/latest/index.html JanusGraph的官方文档
这篇关于图数据库JanusGraph介绍及使用(三):安装与初步使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




