本文主要是介绍关于GreenDao数据库的使用,所需要注意的坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这段时间公司在做一个项目,里面用到了数据库,我看了一下近段时间比较流行的数据库框架,当然优先选择GreenDao,不过在使用这个数据库的时候真的有许多需要注意的地方,我在下面先列举一下,以后遇到问题都回来更新自己的博客:
集成
首先估计大家都是要先集成数据库,我要告诉大家的是在GreenDao3.0之前需要新建一个model来进行辅助创建,但是在GreenDao3.0以后集成数据库更简单了,不用再新建model了,当然,你要是一定要新建,也是可以的;
首先我们需要在主程的build.gradle里面添加依赖
代码块语法遵循标准markdown代码,例如:
dependencies {compile fileTree(include: ['*.jar'], dir: 'libs')compile'org.greenrobot:greendao:3.0.1'compile'org.greenrobot:greendao-generator:3.0.0';然后就是在Project的build.gradle中添加主项目依赖
代码如下:
buildscript {repositories {jcenter()}dependencies {classpath 'com.android.tools.build:gradle:2.3.2'classpath 'org.greenrobot:greendao-gradle-plugin:3.0.0' //GreenDao数据库// NOTE: Do not place your application dependencies here; they belong// in the individual module build.gradle files}
}这第二步我们就算是完成了,当然我们还可以对GreenDao进行自定义代码生成位置,如果我们不自定义,就会生成在build文件夹里,当然这样虽然简单,但是看起来不是很直观,所以我们要自己自定义一个生成数据库代码的位置,怎么做呢?当然是在主程的build.gradle里面加上对greendao的自定义代码:
android {compileSdkVersion 25buildToolsVersion "25.0.0"defaultConfig {applicationId "com.hlzx.dydp"minSdkVersion 15targetSdkVersion 25versionCode 1versionName "1.0"multiDexEnabled = truetestInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"}sourceSets {main {java.srcDirs = ['src/main/java', 'src/main/java-gen']}}greendao {schemaVersion 1daoPackage 'com.hlzx.dydp'targetGenDir 'src/main/java-gen'}
}这就生成在我们自定义的包里面了,但是前提是我们需要在主程里面新建一个java-gen 文件夹,然后就可以build项目了

最后我们就可以创建自己的实体了
创建实体,来生成我们的数据库
@Entity
public class HomeChannelItem extends BaseEntity {/****/@Id(autoincrement = true)private Long id;/*** 栏目对应ID*/@Uniquepublic Integer cat_id;/*** 栏目对应NAME*/public String cat_name;/*** 栏目在整体中的排序顺序 rank*/public Integer orderId;/*** 栏目是否选中*/public Integer selected;@Generated(hash = 1767919126)public HomeChannelItem(Long id, Integer cat_id, String cat_name,Integer orderId, Integer selected) {this.id = id;this.cat_id = cat_id;this.cat_name = cat_name;this.orderId = orderId;this.selected = selected;}@Generated(hash = 1364292117)public HomeChannelItem() {}@Overridepublic boolean equals(Object obj) {if (obj instanceof HomeChannelItem){if (((HomeChannelItem)obj).getCat_id() == this.cat_id)return true;}return false;}@Overridepublic int hashCode() {return cat_id;}public Long getId() {return this.id;}public void setId(Long id) {this.id = id;}... prompt'''
}写完实体类,点击菜单栏中的build一下项目,会生成DaoMaster等类文件

这样我们就可以去使用GreenDao数据库的增删改查了,至于怎么去操作,网上有很多教程,我就不写了,下面我写一些比较重要的,也是广大帅哥美女们要注意的地方
是什么呢?
就是版本兼容问题,我不知道大家有没有遇到过,就是我们在使用GreenDao数据库的时候会发现,在android5.0以上的系统版本,没什么问题,我们可以正常运行,这也没问题,但是在android5.0一下版本就会报错,报什么错呢?很奇葩,大家直接看代码:
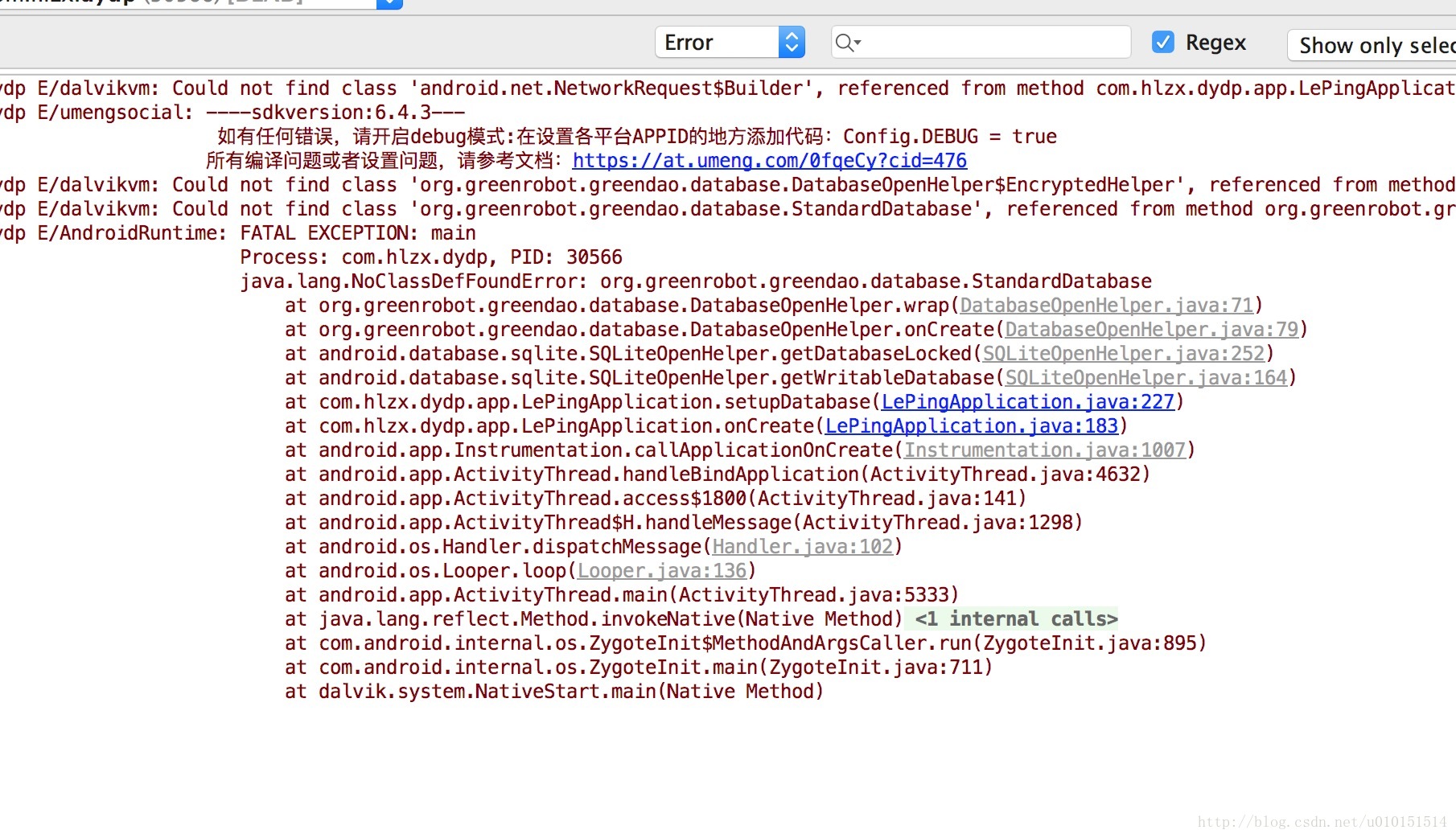
说真的,这个问题纠结了我一天,甚至我联系了GreenDao的开发人员,不过暂时没收到回复,不过有一个哥们给了我一个提示,可能是因为分包的问题,大家别理解错了,不是打包,也不是封包,是分包,对,分包出了问题,在GitHub上面,也同样有同学出现了这个问题,但是GreenDao团队给出的回答是这样的

有没有很模糊,其实他也说是分包的问题,这里我声明一下,的确是分包问题,首先在android5.0以上不牵扯MultiDex分包问题,但是在android4.4甚至以下版本就有这个,但是怎么解决呢?我们需要引入一个包:
compile 'com.android.support:multidex:1.0.0'引入这个来解决分包问题
- 一. 从
sdk\extras\android\support\multidex\library\libs 目录将android-support-multidex.jar导入工程中 - 二. 如果你的工程中已经含有Application类,那么让它继承
android.support.multidex.MultiDexApplication类,
如果你的Application已经继承了其他类并且不想做改动,那么还有另外一种使用方式,覆写attachBaseContext()方法:
public class MyApplication extends FooApplication { @Override protected void attachBaseContext(Context base) { super.attachBaseContext(base); MultiDex.install(this); }
}
然后这样的话就可以解决我们的项目在android4.4以下版本中报错找不到java.lang.NoClassDefFoundError: org.greenrobot.greendao.database.StandardDatabase
结束
至于问什么android4.4需要有分包这个机制,大家可以看下面这篇文章,讲得很好:
Android 使用android-support-multidex解决Dex超出方法数的限制问题,让你的应用不再爆棚
非常感谢 时之沙 同学的这篇博客,如果大家还有什么问题,可以再底部留言,我会及时给大家解答
最后给大家附上几篇GreenDao的博客,大家可以去看看
这篇关于关于GreenDao数据库的使用,所需要注意的坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



