本文主要是介绍04-19 周四 GitHub CI 方案设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年4月19日14:44:23 | V0.1 | 宋全恒 | 新建文档 |
| 2024年4月19日17:22:57 | V1.0 | 宋全恒 | 完成部署拓扑结构的绘制和文档撰写 |
简介
需求
由于团队最近把代码托管在GitHub上,为解决推理、应用的自动化CI的需要,调研了GitHub自带的CI基础设施,基本上需要满足如下的需求:
- 由于大模型需要GPU,因此CI时需要使用GPU来运行,由于一台服务器有多个GPU卡,因此,保证灵活性的同时,需要为每个仓库的CI程序自定义需要的GPU。
- 部署简单,能够实现一台服务器,如8C A100的,同时对4个仓库进行CI作业的运行,而不互相影响。
关联的文档如下所示:
- 04-15 周一 GitHub仓库CI服务器配置过程与workflow配置文件解析文档.md
- 04-18 周四 为LLM_inference项目配置GitHub CI过程记录.md
仓库
当前的仓库主要是为了如下的项目而设置。
GitHub仓库主要是包括四个私有仓库
| 仓库 | 项目简介 | 标签分配 | GPU分配 |
|---|---|---|---|
| LLMChat | 主要是大模型RAG,解决大模型知识时效问题 | A100, gpu, application | 3,4 |
| LLMs_Inference | 主要是依托于vLLM,解决高效推理问题 | gpu, a100, inference | 7号A100 |
注,由于大模型精调和训练组当前还不需要CI,因此未对其进行配置CI。
方案设计
GitHub actions Runner
GitHub Actions Runner 是 GitHub Actions 的一部分,它允许你在自己的硬件、虚拟机或云实例上托管和运行自定义的工作流程。Runner 可以与 GitHub 上的仓库关联,以便在触发事件(如 push、pull request 等)发生时执行工作流程中的任务。
以下是 GitHub Actions Runner 的一些重要特点和功能:
- 灵活性: 可以在自己的环境中托管 Runner,这意味着你可以在自己的硬件、虚拟机或云实例上运行工作流程。这为你提供了更大的灵活性和控制权,以满足特定的需求和安全要求。
- 跨平台支持: Runner 支持多种操作系统和平台,包括 Windows、Linux 和 macOS。这意味着你可以在不同的操作系统上运行工作流程,并且可以根据需要选择合适的平台。
- 自动化: Runner 可以自动更新到最新版本,并且可以自动重新连接到 GitHub 服务器以接收新的工作。这简化了 Runner 的管理和维护,并确保了其与 GitHub 平台的兼容性。
- 安全性: Runner 可以配置为在受限的环境中运行,以确保工作流程中的敏感数据和操作受到保护。此外,Runner 还支持身份验证和令牌以与 GitHub 服务器进行安全通信。
- 自定义性: 你可以自定义 Runner 的配置和行为,以满足特定的需求。例如,你可以配置 Runner 的标签以限制工作流程在特定 Runner 上运行,也可以配置 Runner 的执行器以添加额外的功能和工具。
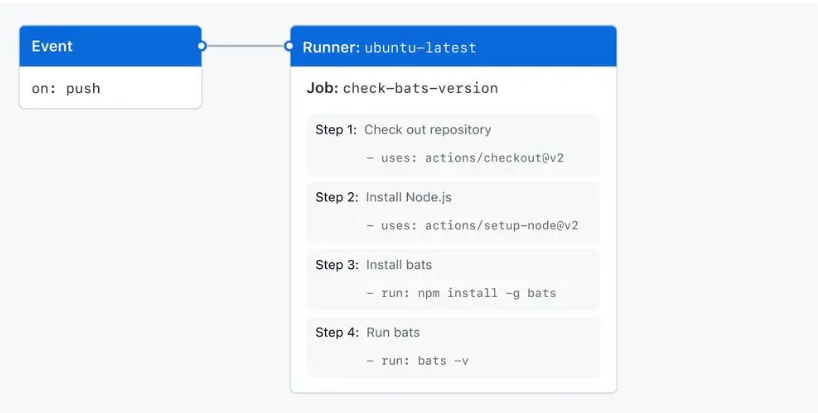
总的来说,GitHub Actions Runner 提供了一个灵活、强大和可扩展的平台,用于在你自己的环境中托管和运行 GitHub Actions 工作流程,从而实现自动化和持续集成/持续部署 (CI/CD)。
注,由于需要使用GPU完成大模型相关的作业,测试,因此无法使用GitHub提供的GitHub-hosted runner,主要是部署self-hosted runner。
GitHub actions-runner 也为托管在GitHub上的仓库,仓库地址,在使用时,采用Client-Server的方式进行作业的分发和处理。
CI服务器
当前用于CI的是包含8张A100卡的42服务器,其操作系统细节如下:
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.6 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.6 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
注,由于当前的宿主机为Ubuntu 20.04,因此在CI时在使用自定义的镜像启动容器进行单元测试等工作时,强烈建议采用Ubuntu 20.04的Pytorch镜像,以防止出现类似GLIBC的问题。
注,建议在镜像中,不要再次使用conda进行环境管理。
部署拓扑
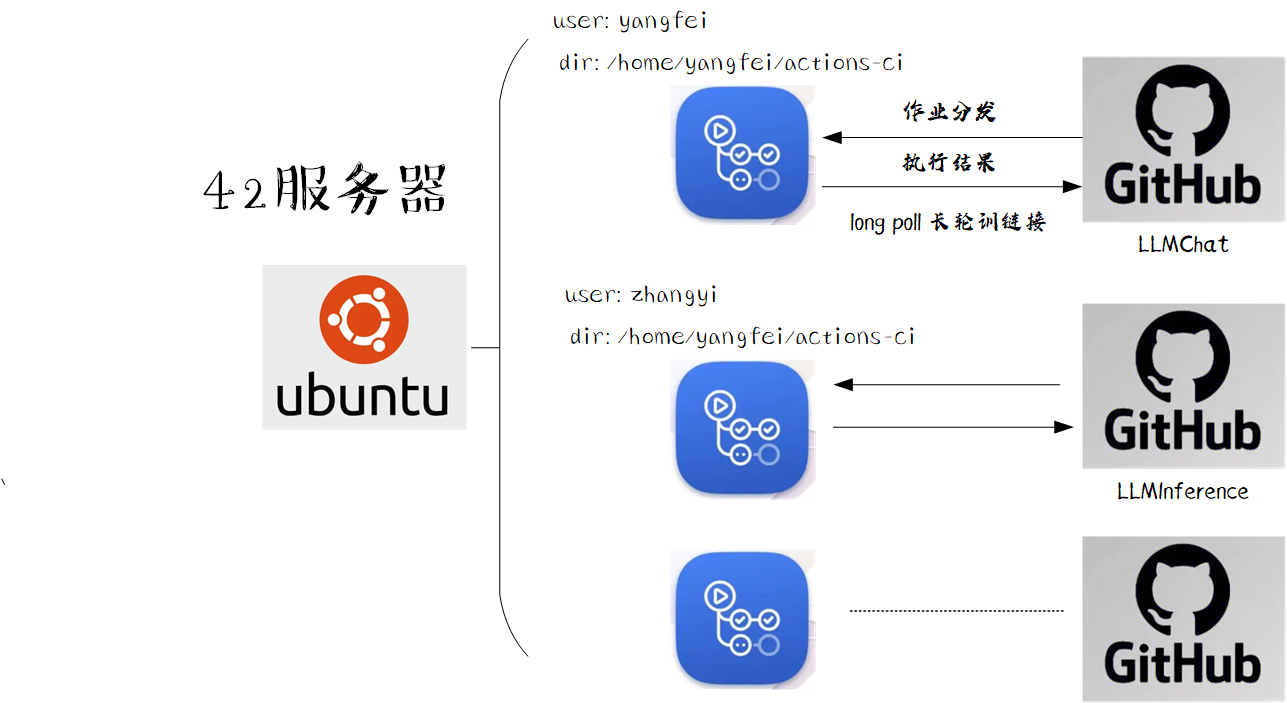
为满足多个仓库在同一台服务器使用GPU进行CI作业的需求,因此,我们需要部署多个actions-runner实例与github server进行交互,具体的部署结果如下图所示:
经过调研,采用的是多用户多个actions-runner实例的部署,具体如下图所示:
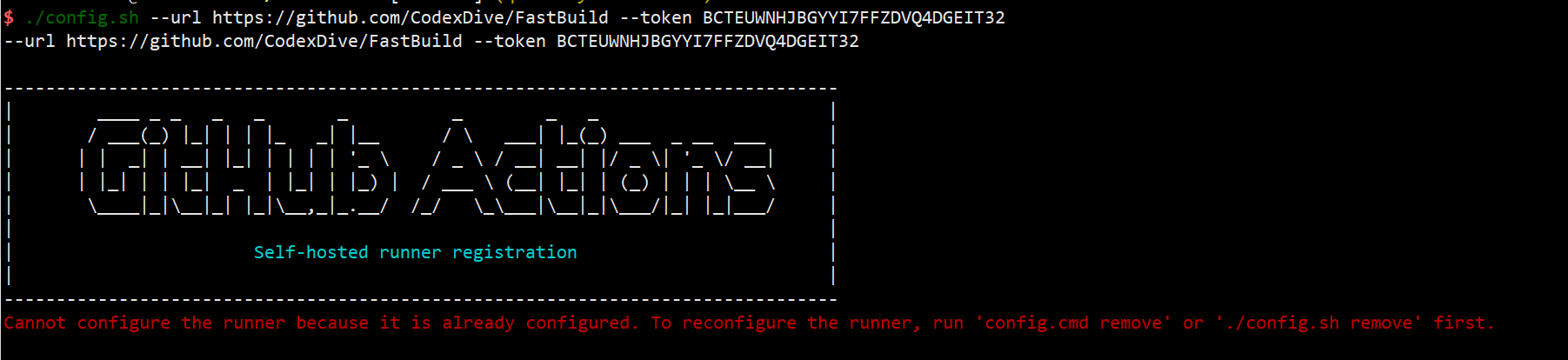
注,在使用多actions-runner实例时,尝试过了如下的方案:
- 在42服务器上采用虚拟化,即Docker容器中包含actions-runner服务,可以注册但执行CI会报错。
- 在42服务器上,采用单用户部署多个实例(部署更加简单),但直接报错,无法配置。
Docker中包含actions-runner,报错,Docker in Docker这个特征当前还不支持。

单用户部署多个actions-runner实例,报错:
所以,最终选择了为每个仓库新建一个用户,在该用户的目录下运行该实例。
GPU资源限额
CI解释
由于在运行actions-runner实例,并没有划分GPU,即确定在作业分发时使用的GPU,这部分工作,是由self-hosted Runner的在容器中运行作业来指定的。也就是在不同的仓库执行CI作业时,有各自的CI工作流要执行:
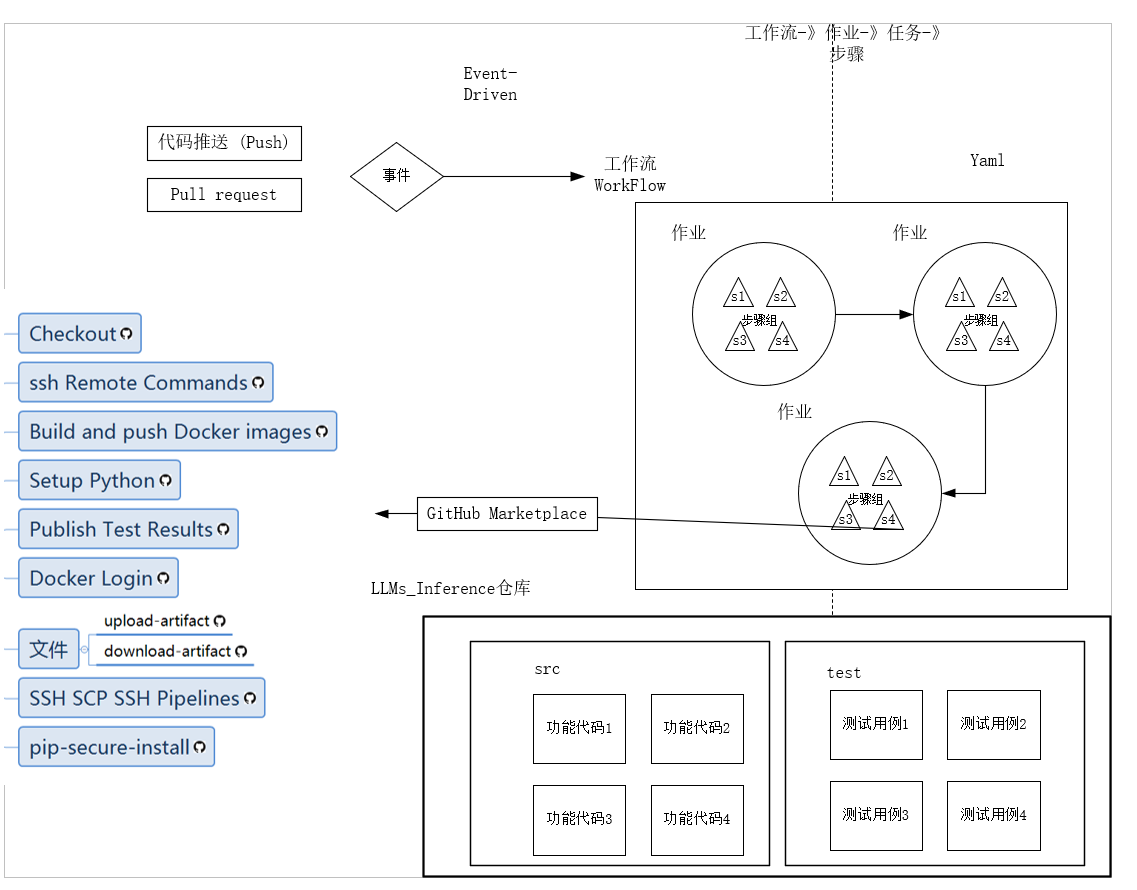
这些工作流是由workflow的配置文件定义的,即.github/workflows/*.yaml定义的。
换句话说,即使用那个镜像启动容器,以什么方式启动容器,在容器中执行那些过程,都是由这个配置文件决定的。
使用7号gpu卡进行CI作业的工作流配置文件
# This workflow will install Python dependencies, run tests and lint with a single version of Python
# For more information see: https://docs.github.com/en/actions/automating-builds-and-tests/building-and-testing-pythonname: LLM_Inference CIon:push:branches: [ "features-ci-songquanheng" ]pull_request:branches: [ "main" ]permissions:contents: readjobs:llm-inference-ci:runs-on: [self-hosted, linux, x64, a100, inference]defaults:run:shell: bash -l {0}container:image: nvcr.io/nvidia/pytorch:22.12-py3options: --runtime nvidia --shm-size=32gbcredentials:username: adminpassword: admin@ZJ2023env: NVIDIA_VISIBLE_DEVICES: 7volumes:- /home/yangfei/:/home/yangfeiports:- 22steps: - name: show pyhon versionrun: |python --version- name: show the gpus availablerun: |nvidia-smi- name: install necessary pip dependencies run: |pip install vllm --index-url https://pypi.tuna.tsinghua.edu.cn/simple- name: Test with pytest and generate coverage report run: |pytest --cov=tests --cov-report=xml- name: Upload coverage reports to Codecovuses: codecov/codecov-action@v4with:token: ${{ secrets.CODECOV_TOKEN }}file: coverage.xmlverbose: true上述配置文件限定了为ci容器使用的gpu资源。具体关于该配置文件的解析,可以参见
-
[04-15 周一 GitHub仓库CI服务器配置过程与workflow配置文件解析文档.md](D:\400-工作\440-中心\443-高效能计算中心\04-15 周一 GitHub仓库CI服务器配置过程与workflow配置文件解析文档.md)
不再赘述
总结
本文主要描述了在42服务器上为多个仓库部署actions-runner实例的CI 部署方案,具体包含如下内容:
- 42CI服务器的详情
- 团队代码仓库的标签划分
- 部署拓扑结构
- GPU限定使用的实现。
通过这样的部署方式,就可以灵活的为多个代码仓库的自动化CI实现各种自定义的功能,以满足特定的要求和实现。
这篇关于04-19 周四 GitHub CI 方案设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




