本文主要是介绍Kafka分级存储概念(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kafka分级存储及实现原理
概述
Kafka社区在3.6版本引入了一个十分重要的特性: 分级存储,本系列文章主要旨在介绍Kafka分级存储的设计理念、设计细节以及具体的代码实现
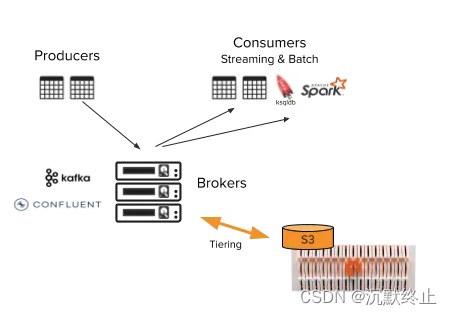
背景:为什么要有分级存储?
场景
作为一款具有高吞吐及高性能的消息中间件,Kafka被广泛应用在大数据、日志采集及业务消息领域. 在日常Kafka的运维过程中,往往会遇到以下一些场景:
1、某些消息需要保留特定时间,以便业务需要以及意外恢复场景,这会带来额外的磁盘占用
2、大部分场景下,消息都可以进行及时消费;业务高峰时,会存在一定的消息积压
3、随着业务的拓展,磁盘的容量需要进行扩容;但在业务有变动时,可能又不需要这么大的磁盘空间,需要进行缩容
问题
以上业务场景暴露了当前Kafka设计上的一些缺陷:缺乏弹性能力.
1、对于业务消息来说,大部分消息其实属于“热”消息,也就是所谓的可以被及时消费的消息,而部分“冷”消息则需要等待一定老化时间之后才能够从磁盘上清除;
2、对于磁盘扩容场景,对于增加磁盘容量,运维人员可以通过操作系统LVM实现,对磁盘缩容而言则往往没有这么容易,可能需要额外的业务方案实现
3、对于Kafka的横向扩容来说,新增加的节点上并不会有原有节点上的分区,运维人员往往需要1)增加分区个数 2) 进行分区平衡(reassign)进行分区均衡;而分区平衡则会产生Broker之间的副本同步,抢占节点之间的带宽,往往建议在业务低峰时期进行
思考
所以有没有一种办法,可以将冷热数据分离开来,同时尽量减少在集群扩缩容过程中的数据迁移呢?答案就是分级存储
分级存储是什么
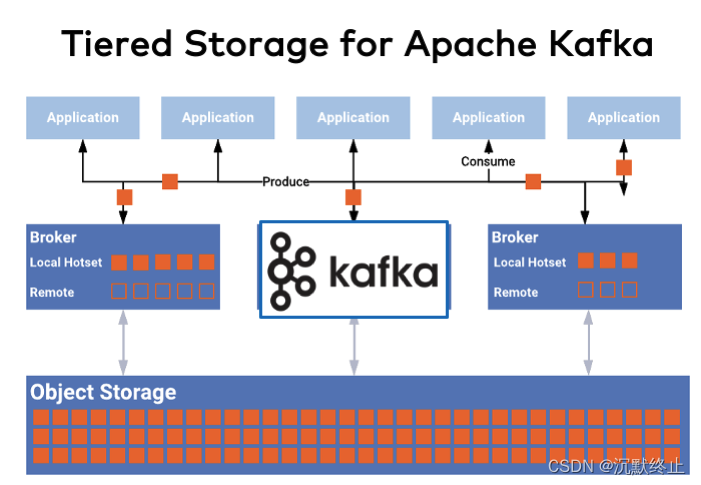
一句话来说,Kafka分级存储就是将“热”数据存储在访问速度快的本地磁盘(ESSD/SSD),将“冷”数据放在远端(如aws s3), 这样做带来的好处是:
1、对于大部分场景下,正常的生产、消费速率不受影响
2、数据存储在相对成本较低的远端存储上,节约了成本
3、不用关心磁盘大小,冷数据会被自动卸载到远端,本地磁盘使用量有固定上限
4、集群横向拓展时,只需要迁移少量热数据
5、磁盘使用可以弹性伸缩,因为往往远端存储是按量付费的,可以实现存储Serverless化
冷数据真的“冷”吗?
前面提到,我们希望将“冷”数据上传到远端,那么我们如何定义“冷”数据呢,又有什么必要存储这些数据呢,以下是几个场景:
- 新消费应用加入
- 应用重启
- 应用处理时出现异常,可能需要从头开始消费
- 全量数据处理
- 查询/分析
- 故障恢复
- …
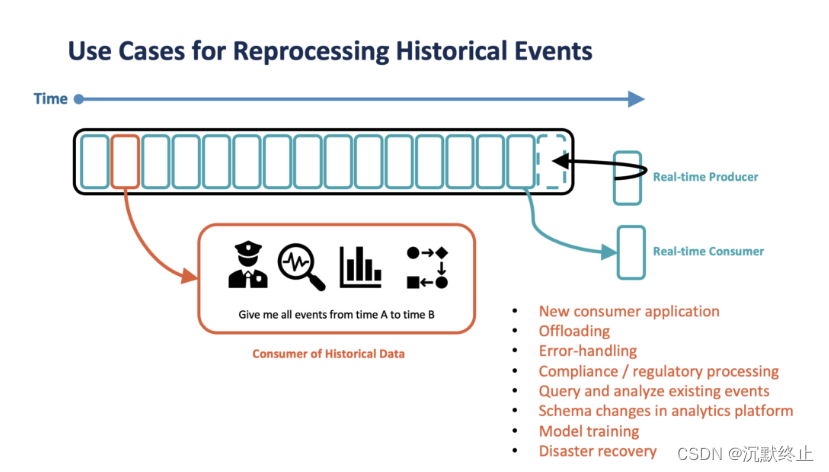
TIPS:其实对于Kafka来说,大部分使用场景下都是实时的生产与消费,而且可以充分利用到操作系统页缓存来提高性能,在有大量消息积压场景下,存在的页缓存不命中而冷读磁盘的场景会导致Kafka的性能下降,同时容易产生磁盘IOPS等现象,不利于集群的性能,因此日常的使用中,在非业务高峰时,需要尽量避免产生大量消息积压
小结
本篇文章主要讲述了Kafka分级存储的背景及其解决的业务问题,后续将会继续围绕分级存储具体设计与实现分析其具体实现逻辑和细节供大家参考讨论
这篇关于Kafka分级存储概念(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




