本文主要是介绍Hadoop学习第四天之hadoop命令操作(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hadoop学习第四天之hadoop命令操作(下)
1. Hadoop dfsadmin #启动dfs admin客户端
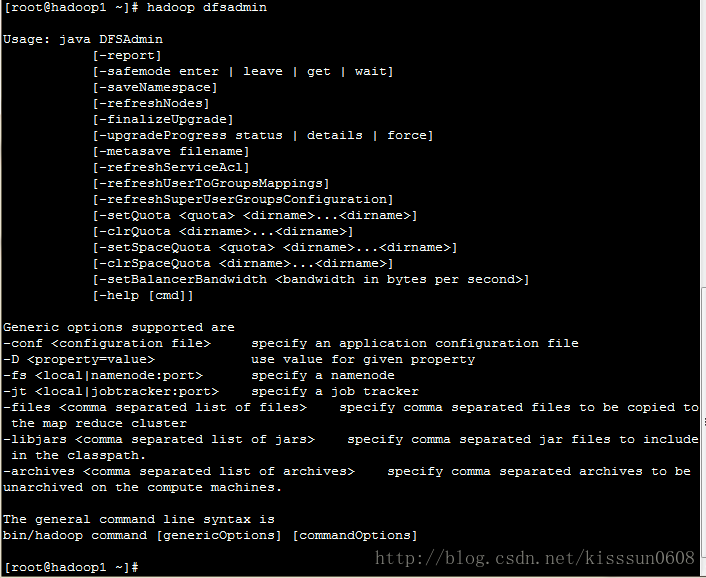
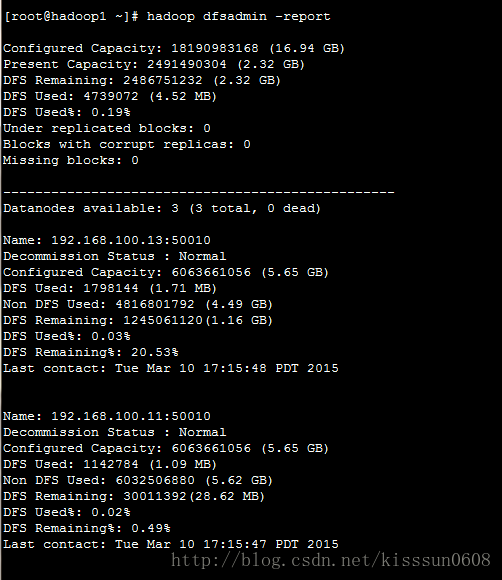
-report #报告当前集群的节点信息
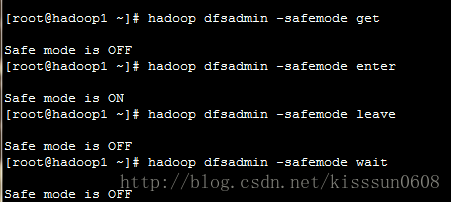
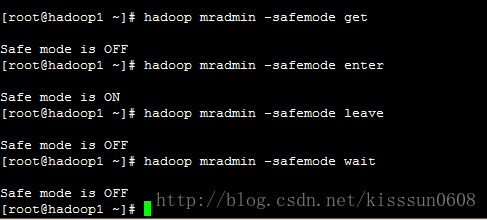
-safemode enter #进入安全模式
-safemode leave #离开安全模式
-safemode get #获取安全模式状态
-safemode wait #等待,直到安全模式结束
-saveNamespace #开启保存命名空间,必须开启安全模式

-refreshNodes 刷新集群的datanode节点

-finalizeUpgrade #升级时先删除现有备份

-upgradeProgress status #查询集群升级的状态
-upgradeProgress details #查询集群升级的详细状态信息
-upgradeProgress force #强制升级



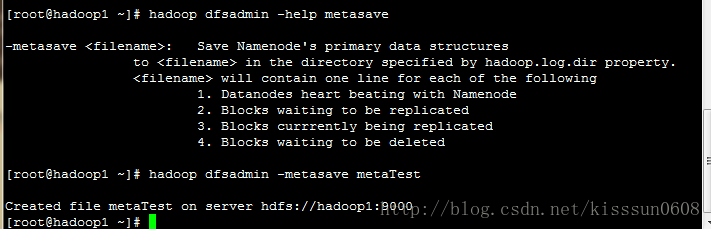
-metesave <fileName> #将元信息保存在hdfs上的指定文件中
-refreshServiceAcl 刷新服务的访问控制列表,Namenode将会重新加载访问控制列表

-refreshUserToGroupsMappings #刷新用户到组的映射关系
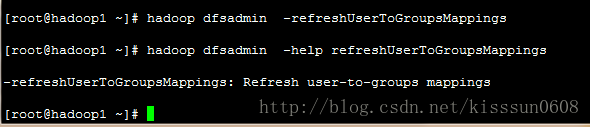
-refreshSuperUserGroupsConfiguration #刷新超级用户代理组的映射

-setQuota <quota> <dirname>…<dirname> #为每个目录dirname设置配额,不能在安全模式下

-clrQuota <dirname>…<dirname> #清除每个dirname的配额
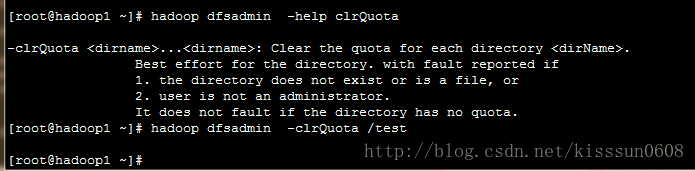
-setSpaceQuota <quota> <dirname> …. <dirname> #设置磁盘空间配额
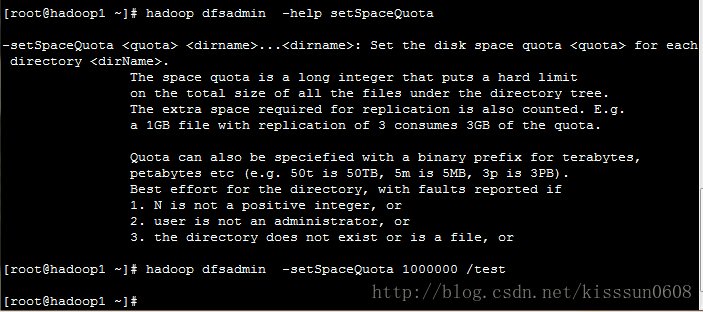
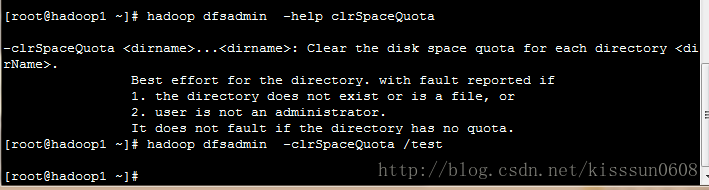
-clrSpaceQuota <dirname> ….<dirname> #清除磁盘空间配额
- setBalancerBandwidth <bandwidth in bytes per second> #平衡各节点数据的带宽大小。此例设置带宽为500M/s

-help [cmd] 显示命令的帮助信息

2. Hadoop mradmin #启动MapReduce admin客户端
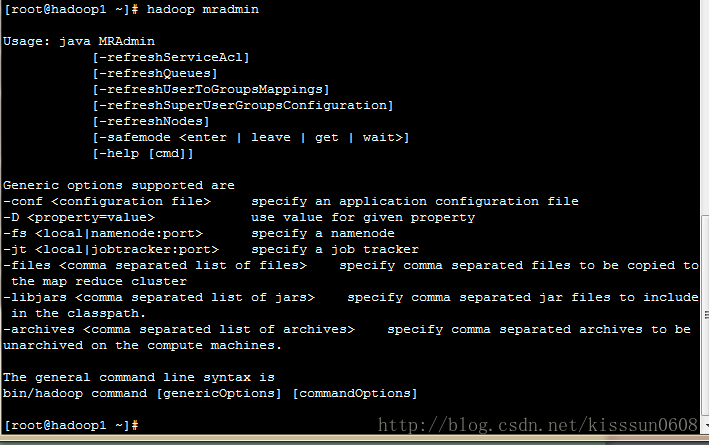
-refreshServiceAcl #刷新服务的访问控制列表,MapReduce重新载入访问控制列表

-refreshQueues #刷新MapReduce的队列

-refreshUserToGroupsMappings #刷新用户到组的映射关系

-refreshSuperUserGroupsConfiguration #刷新超级用户代理组的映射

-refreshNodes #刷新tasktrackers节点集群

-safemode enter #开启MapReduce的安全模式
-safemode leave #离开MapReduce的安全模式
-safemode get #获取MapReduce的安全模式状态
-safemode wait #等待MapReduce的安全模式结束
-help [cmd] #查看命名的描述
3. hadoop namenode –format #Hadoop的namenode节点格式化
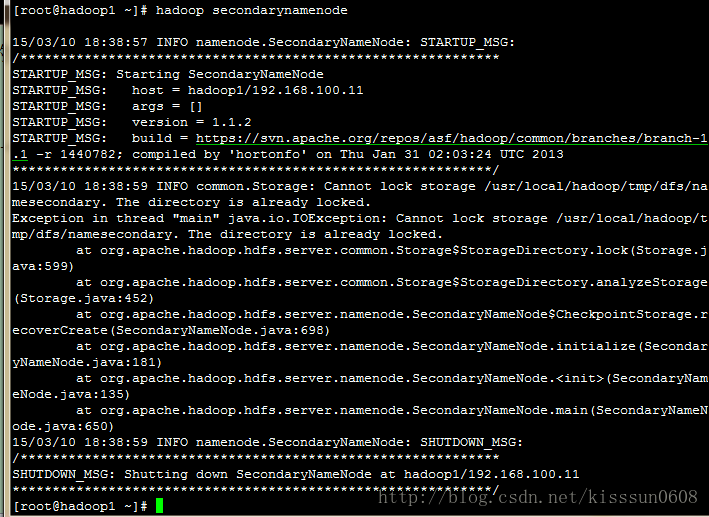
4. hadoop secondary namenode #启动secondarynamenode ,因为secondarynamenode已经启动,需要先关闭后重新启动
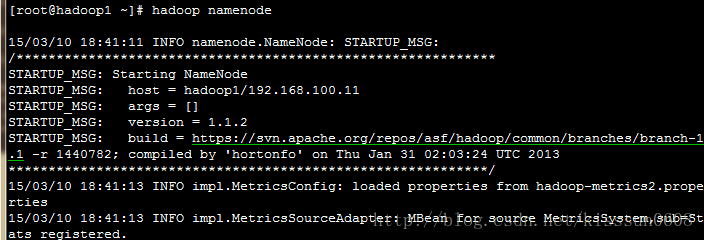
5. hadoop namenode #单独运行dfs的namenode节点,如果节点已经启动,需要先关闭,然后重新启动
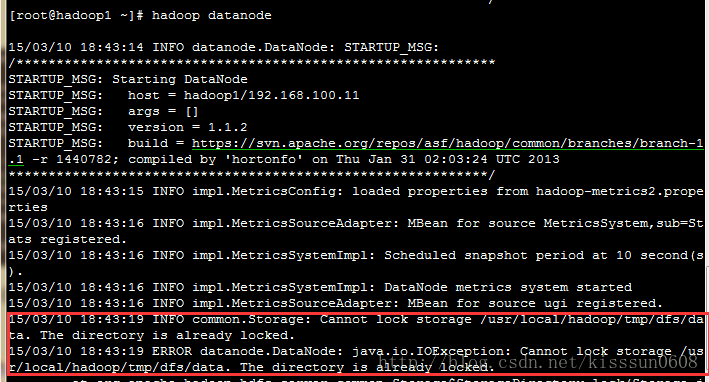
6. hadoop datanode #单独运行dfs的datanode节点,如果节点已经启动,需要先关闭,然后重新启动
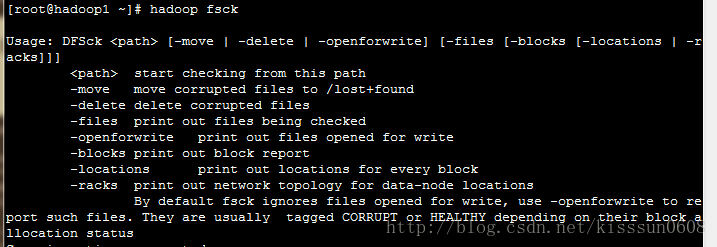
7. hadoop fsck #运行dfs文件系统的检查命令
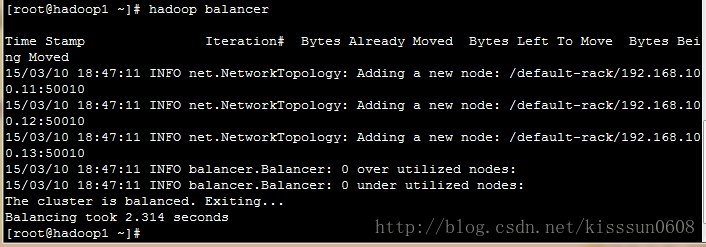
8. hadoop balancer #运行集群的平衡策略
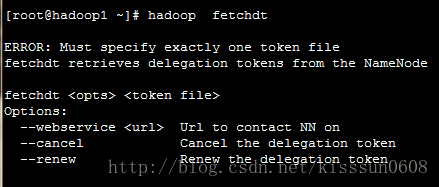
9. hadoop fetchdt # 获取namenode的授权
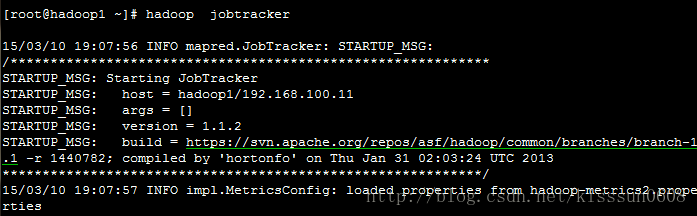
10. hadoop jobtracker #运行MapReduce的jobTracker,如果jobtracker已经启动,会提示地址已经被占用。
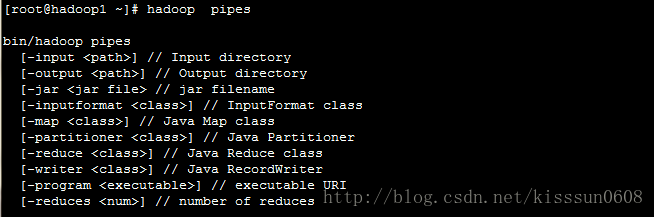
11. hadoop pipes #运行管道job
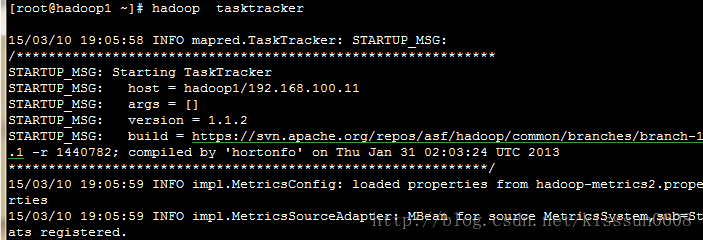
12. hadoop tasktracker #运行MapReduce的tasktracker 节点,如果当前节点已经启动tasktracker,会提示地址已经被占用
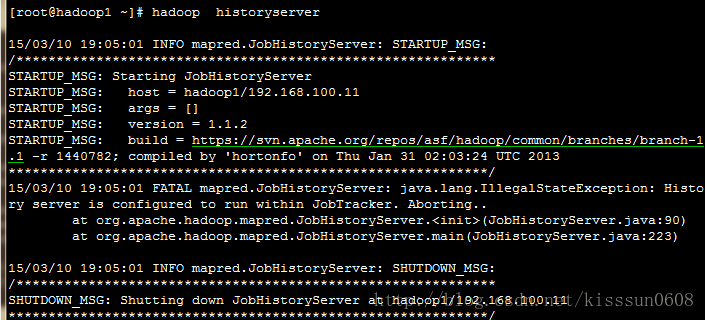
13. hadoop historyserver #运行job的历史服务作为一个独立的守护进程
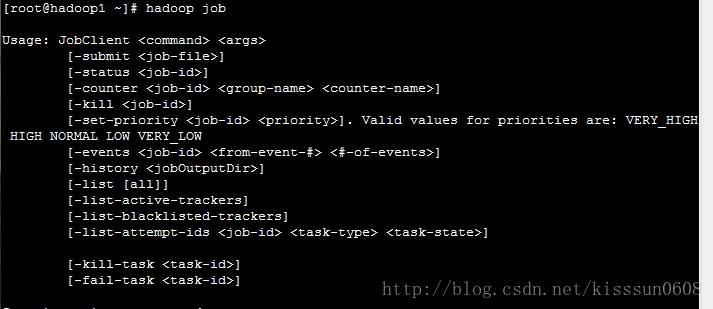
14. hadoop job #调整MapReduce的job
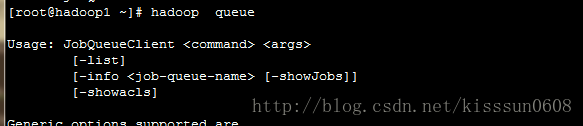
15. hadoop queue #获取job队列的相关信息
16. hadoop version #打印版本

17. hadoop jar <jar> #运行编写好的jar文件
18. hadoop distcp <srcurl> <desturl> #复制文件和目录
19. hadoop archive -archiveName NAME -p <parent path> <src>*<dest> #创建一个Hadoop的存档
这篇关于Hadoop学习第四天之hadoop命令操作(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




