本文主要是介绍快学Scala第4章--映射和元组,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
快学Scala第4章–映射和元组
映射是键/值(key-value)对偶的集合。Scala有一个通用的叫法–元组—–n个对象的聚集,并且不一定要相同类型的。而对偶不过是n=2的元组
本章要点
- Scala有十分容易的语法来创建、查询和遍历映射
- 你需要从可变的和不可变的映射中做出选择
- 默认情况下,你得到的是一个哈希映射,不过你也可以指明要树形映射
- 你可以很容易的在Scala映射和Java映射之间来回切换
- 元组可以用来聚集值
构造映射
Scala映射的构建方式:
val scores = Map("Alice" -> 10, "Bob" -> 3, "Cindy" -> 8)
// 你也可以以圆括号来定义:
val scores = Map(("Alice", 10), ("Bob",3), ("Cindy", 8))// 如果想从空的映射开始,你需要选定一个映射实现并给出类型参数
val scores = new scala.collection.mutable.HashMap[String, Int]在Scala中,映射是对偶的集合。对偶简单的说是两个值构成的组,这两个值并不一定是同一个类型,比如(“Alice”, 10),这和C++的pair相同,是key-value的关系;在构建Map时,如果有多个对偶的key相同,则会只保留最后一个对偶,其实执行的是更新操作。
映射这种数据结构是一种将键映射到值的函数,区别在于通常的函数计算值,映射只是用来做查询。
获取映射中的值
val bobsScore = scores("Bob") // 以key索引value如果映射并不包含请求中使用的key,则会抛出异常。要检查映射中是否有某个指定的key,可以使用contains方法:
val bobsScore = if (scores.contains("Bob")) scores("Bob") else 0
// 更快捷的方式
val bobsScore = scores.getOrElse("Bob", 0)更新映射中的值
在可变(mutable)映射中,你可以更新某个映射的值,或者添加一个新的映射关系:
scores("Bob") = 10 // 更新key "Bob" 对应的value
scores("Fred") = 7 // 增加新的key-value对偶到scores// 使用 += 来添加多个关系
scores += ("Bob" -> 10, "Fred" -> 7)
// 使用 -= 来移除某个key-value对偶
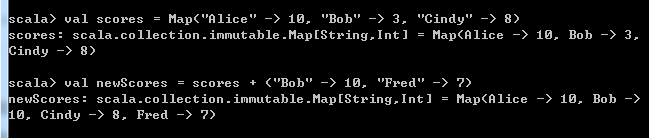
scores -= "Alice"对于一个不可变的映射,不能改变它本身,但是可以产生一个新的映射:
val newScore = scores + ("Bob" -> 10, "Fred" -> 7)此时newScore映射包含了与scores相同的映射关系,此外,”Bob”被更新, “Fred”被添加进来。
想要去除不可变映射的某个关系,也是通过产生新的映射:
val newScores = scores - "Alice"这样不断的创建新的映射其实对效率没有太大的影响,因为老的映射和新的映射共享大部分结构,其原因就是因为它们不可变的。
迭代映射
for ((k, v) <- 映射) 处理k和v如果只需要访问key或value,则可以使用keySet和values方法。values方法返回一个Iterable,可以在for循环中使用这个Iterable :
scores.keySet // 一个类似于Set("Alice", "Bob", "Cindy")这样的集合
for (value <- scores.values) println(value)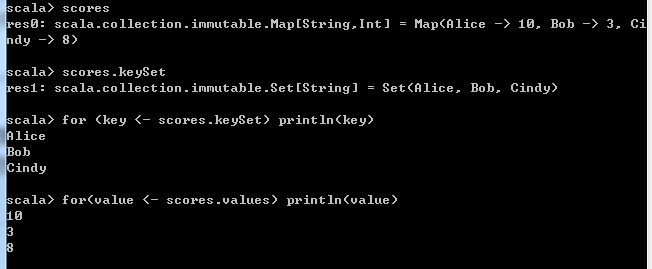
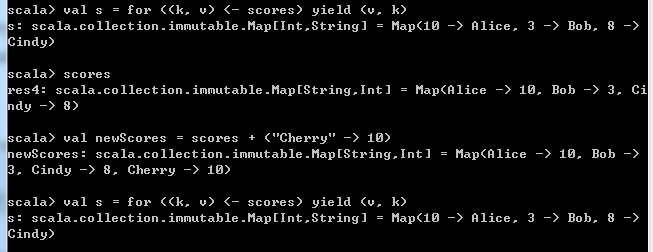
要反转一个映射即交换key和value的位置:
for ((k, v) <- 映射) yield (v, k)但是交换后,v变成了新映射的key,但是key不允许重复,因此将重复的key的丢掉
已排序映射
Scala的映射提供了两种数据结构:一个是哈希表,另一个是平衡树。在C++中,(没记错的话) STL中的Map使用的是红黑树。 默认情况下,Scala给的是哈希表。当然哈希表构成的map中的key是没有排序的,而平衡树构成的map的kay是排序的。 要得到一个树形映射:
val scores = scala.collection.immutable.SortedMap("Bob" -> 3, "Alice" -> 10, "Fred" -> 7, "Cindy" -> 8)
**注:**Scala并没有提供可变的树形映射,如果你想要,最接近的选择是使用Java的TreeMap
提示:如果要按插入顺序访问所有key,使用LinkedHashMap:
val months = scala.collection.mutable.LinkedHashMap("Jaunary" -> 1, "Februray" -> 2, "March" -> 3, "April" -> 4, "May" -> 5, ...)与Java的互操作
有Java到Scala转换:
import scala.collection.JavaConversions.mapAsScalaMap
val scores: scala.collection.mutable.Map[String, Int] = new java.util.TreeMap[String, Int]import scala.collection.JavaConversions.propertiesAsScalaMap
val props: scala.collection.Map[String, String] = system.getProperties()由Scala到Java的转换
import scala.collection.JavaConversions.mapAsJavaMap
import java.awt.font.TextAttribute._
val attrs = Map(FAMILY -> "Serif", Size -> 12) // Scala映射
val font = new java.awt.Font(attrs) // 该方法预期一个Java映射元组
映射是Key-Value对偶的集合。对偶是元组(Tuple)的最简单形态——–元组是不同类型的数据的聚集。例如:
val t = (1, 3.14, "Fred") // t是一个元组,类型为Tuple3[Int, Double, java.lang.String]// 访问元组的组元
t._1 // 1
t._2 // 3.14
t._3 // Fred元组的各组元是从1开始的,这个和数组不同。
通常使用模式匹配的方式来获取元组的组元,例如
val (first, second, third) = t // first为1, second为3.14, third为"Fred"
// 如果不需要某个组元,可以使用_代替
val (first, second, _) = t元组可以用于函数需要返回的值不止一个的情况
拉链操作
使用元组的原因之一是把多个值绑定在一起,以便它们能够一起被处理,这通常可以用zip方法来完成。
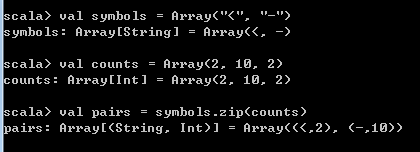
val symbols = Array("<", "-", ">")
val counts = Array(2, 10, 2)
val pairs = symbols.zip(counts)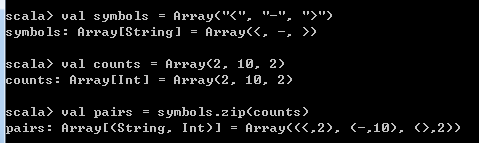
symbols 的元素个数 小于 counts的元素个数时
symbols的元素个数 大于 counts的元素个数时
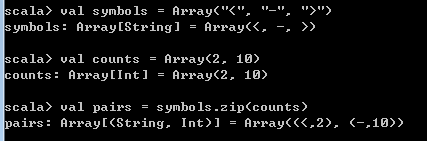
经过比较,zip操作时,得到的结果数量与数量少的集合相同。
可以使用tpMap方法将对偶的集合转换成映射,如: keys.zip(values).toMap
这篇关于快学Scala第4章--映射和元组的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





