本文主要是介绍【计算机科学速成课】笔记二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
笔记一
文章目录
- 7.CPU
- 阶段一:取指令阶段
- 阶段二:解码阶段
- 阶段三:执行阶段
- 8.指令和程序
- 9.高级CPU设计——流水线与缓存
7.CPU
CPU也叫中央处理器,下面我们要用ALU(输入二进制,会执行计算)、两种内存(寄存器(很小一块内存,能存一个值)、RAM(大量内存,能在不同地址存大量数字))来做一个CPU——电脑的心脏。

计算机中上的任何东西都是程序,程序有指令和数据组成。指示计算机要做什么。
我们采用微体系架构的方式(注重功能,适当抽象)来讲解之——
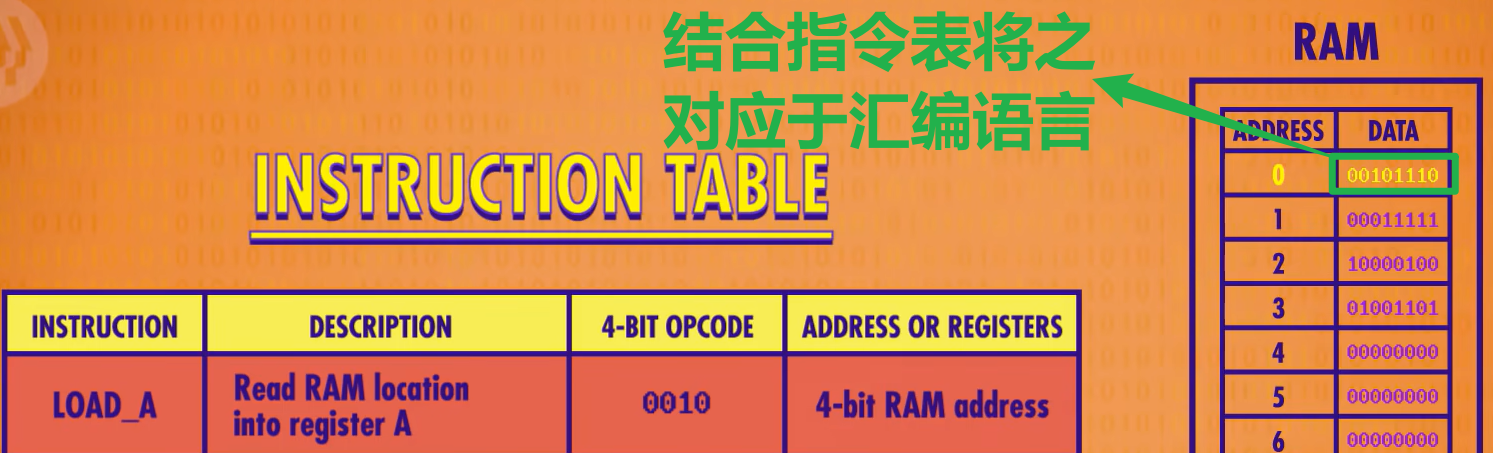
CPU既然是执行指令的,下面是CPU的指令表
我们给所有的指令分配一个ID,我们用前四位存操作码,后四位存地址或寄存器,指示数据来自哪里

我们还需要两个寄存器来完成CPU,指令地址寄存器(用来追踪程序运行到了哪里,即里面存当前指令的内存地址)、指令寄存器(用来存当前指令)。
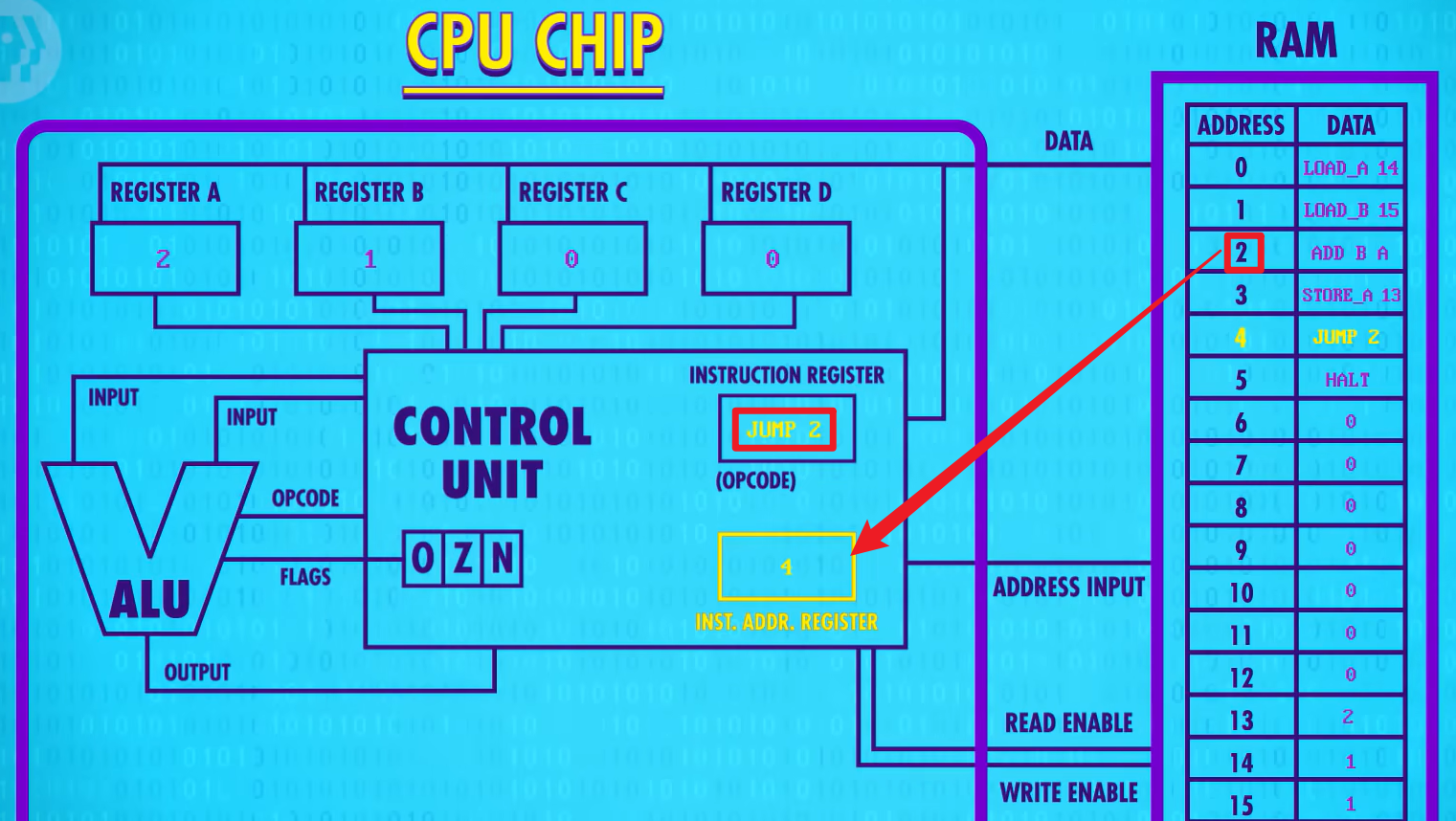
下面是目前的大概图示:
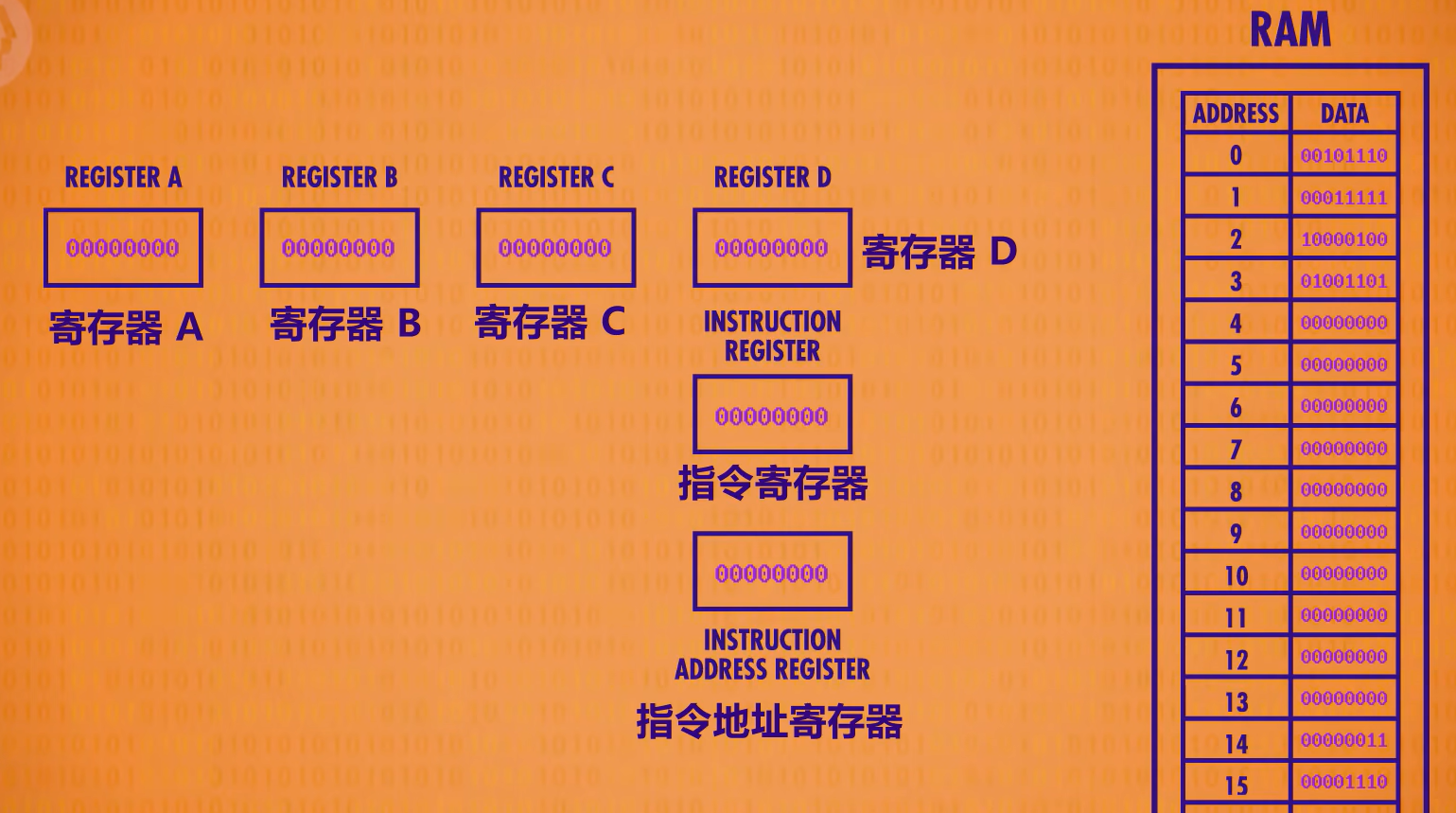
为了举例,我们在RAM里面存了一个程序,我们会将其运行并一步一步讲解:
CPU运行有三个阶段——
阶段一:取指令阶段
初始所有寄存器里面的值均为0。指令地址寄存器连接到RAM,因为里面地址为0,所以会返回RAM中地址为0处的数据,将00101110复制到指令寄存器中。现在指令拿到了,必须分析是什么指令才能进行执行。
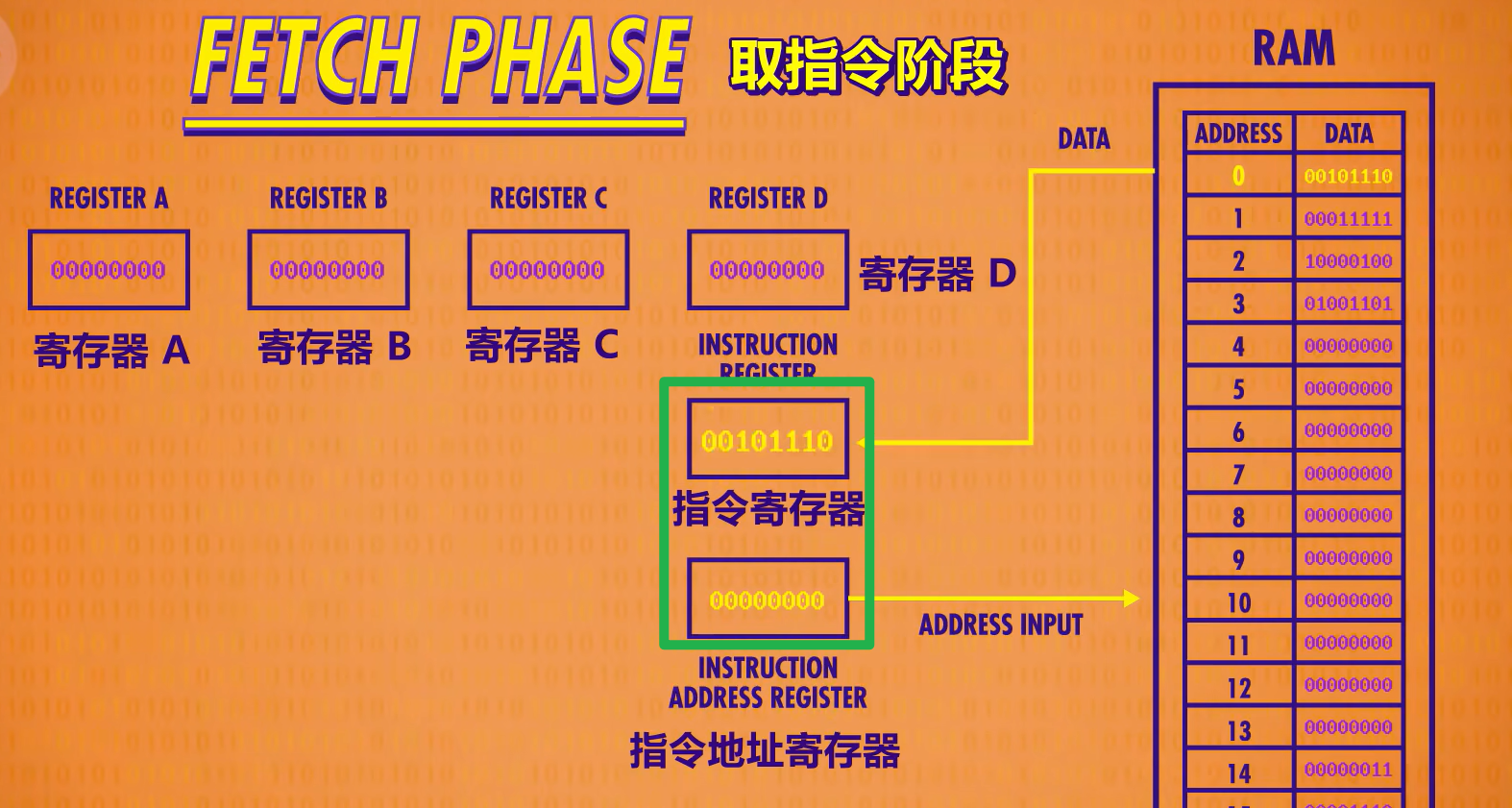
阶段二:解码阶段
首先检查指令前四位值,是0010,对应于指令表中的LOAD_A,即将值加载到寄存器A中,后四位是RAM的地址,1110,即十进制中的14,查看RAM地址为14处的数据为00000011,则该数据会加载进寄存器A中


上面这是解码器,用来判断指令是否是LOAD_A的。
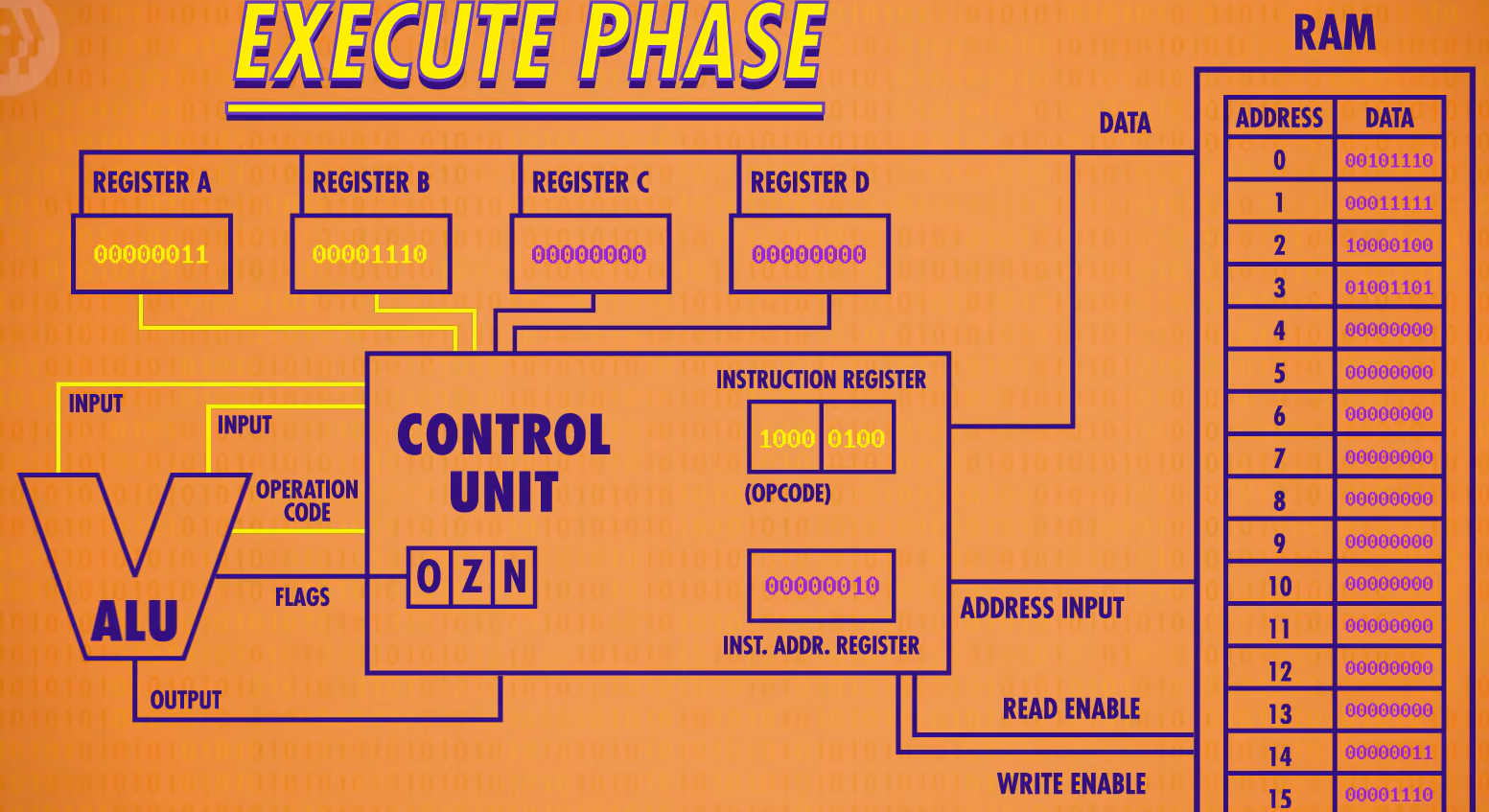
阶段三:执行阶段
现在既然知道是什么指令了,就可以开始执行了。上面的检查是否是指令LOAD_A的电路可以打开RAM的“允许读取线”,把地址14传过去进行读取。地址14里面的值是00000011,因为只是加载进寄存器A中,所以会将所有寄存器用线连接起来,只打开寄存器A,将00000011存入即可。如下图。
之后将指令地址寄存器加1,执行阶段到此结束,进行下一次读取指令并执行。
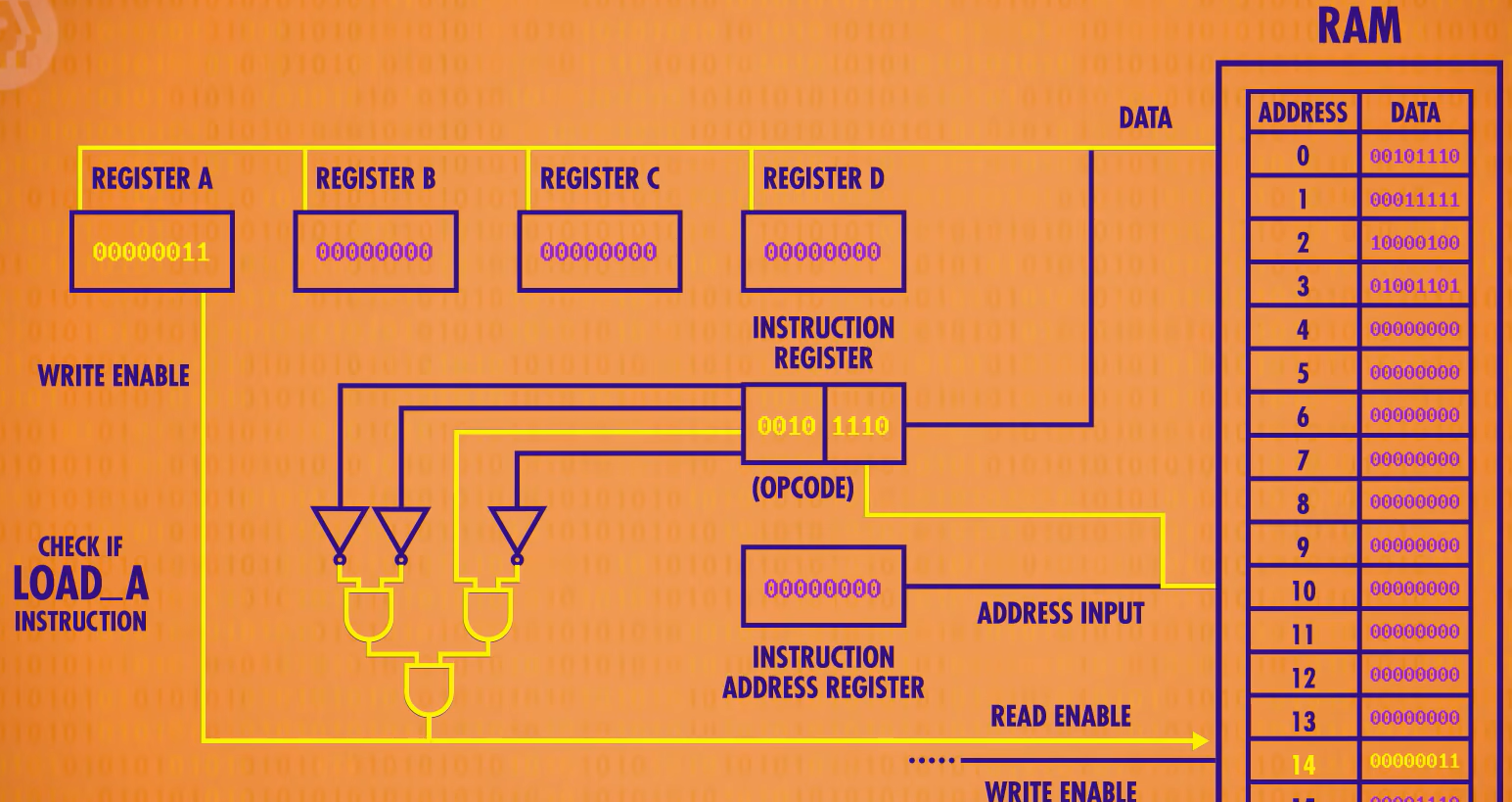
上面只是LOAD_A指令的执行过程,不同指令有不同逻辑解码电路,这些逻辑解码电路会配置CPU内的组件来执行相应操作。我们不妨将解码电路封装成一个单元(又一层抽象),称为控制单元(control unit)——
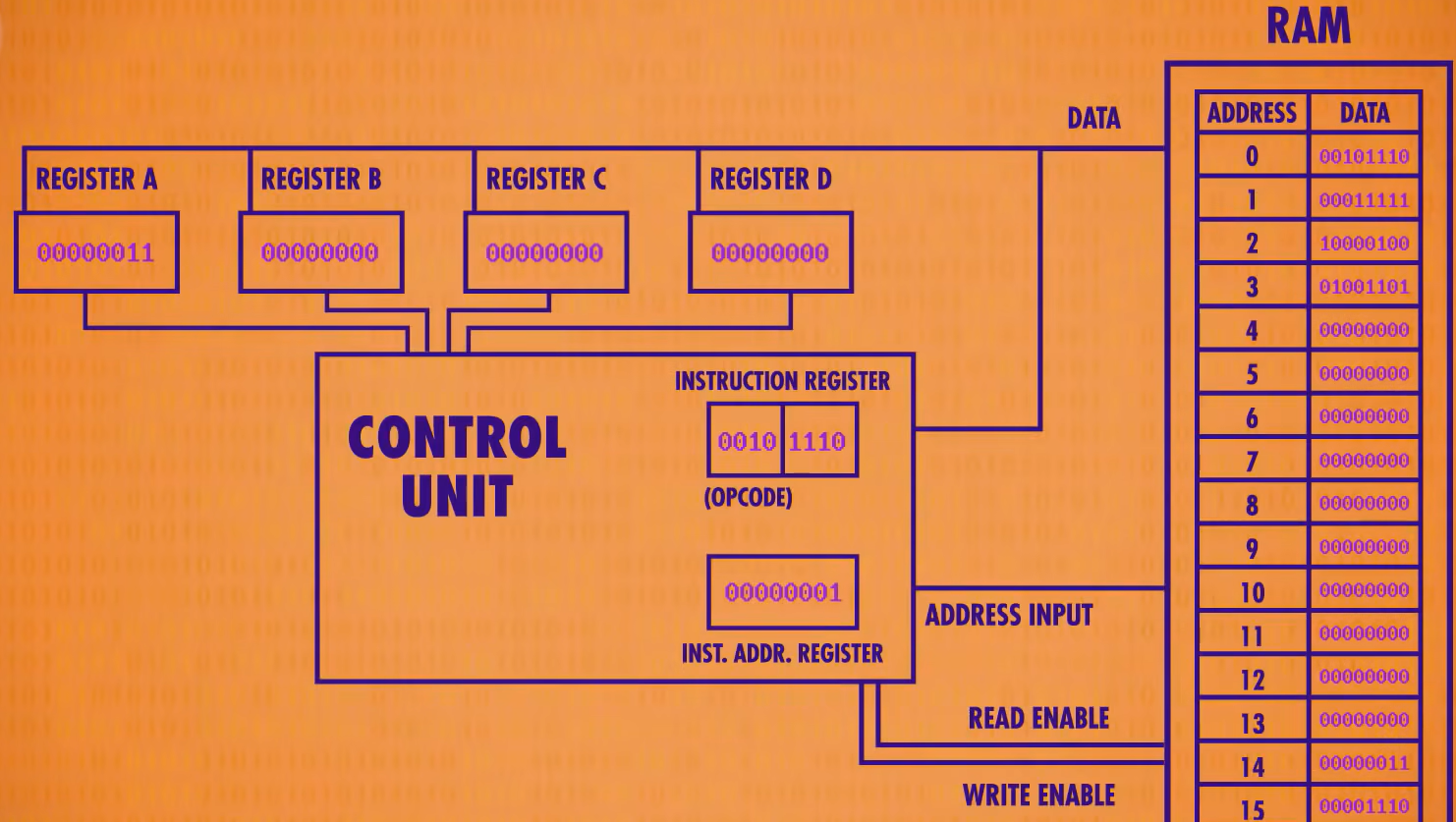
控制单元就像管弦乐队的指挥一样,“指挥”CPU的所有组件。“取指令”——>“解码”——>"执行"完成之后,又再次开始该过程。直至程序结束。
当程序执行指令到地址2处时,指令为1000 0100,对应指令为将两个寄存器的值相加。后面的地址01代表寄存器B,地址00代表寄存器A,因此该指令代表将寄存器B与A相加后存到寄存器A中。

为了执行这个指令,我们的控制单元要整合ALU,进行运算。这里控制单元先用自己的寄存器保存结果,然后将ALU关闭后,再将结果存进寄存器A中。
最后一个指令将寄存器A中的值放入RAM中。这就是我们的第一个电脑程序!从RAM中加载两数后相加后存入RAM中。仅仅用了4条指令,地址从0~3.
现实中,处理器中会有一个“时钟”来控制上面的**“取指令”——>“解码”——>"执行"的节奏**与速率。
时钟以精确的间隔触发电信号,控制单元会用这个信号,推进CPU的内部操作。确保一切顺利进行。
CPU执行**“取指令”——>“解码”——>"执行"的速度叫做“时钟速度”**,单位是HZ。通常也会有超频、降频来增加、降低时钟速度的。
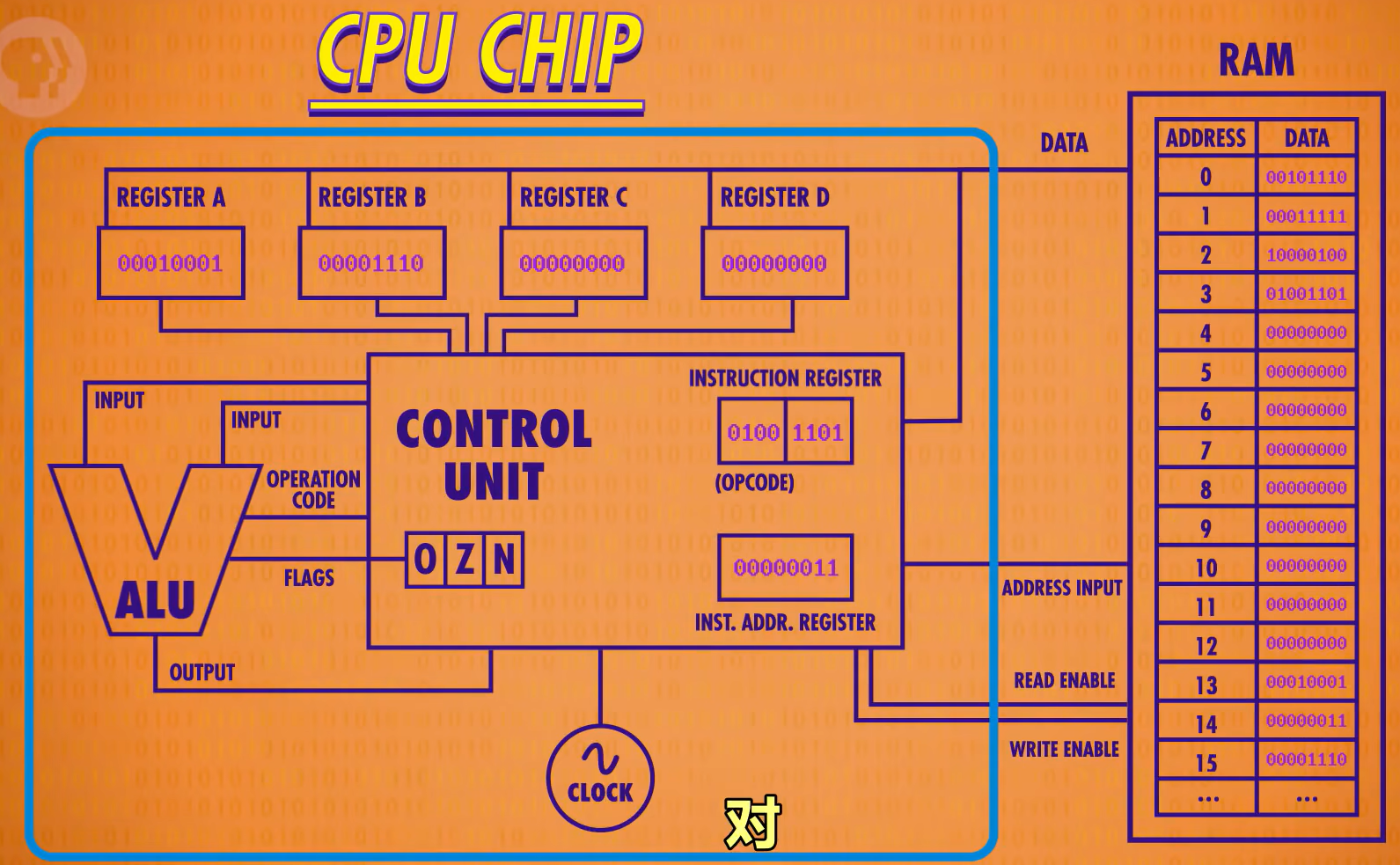
我们将上面的CPU Chip抽象后封装成独立元件,叫做CPU芯片。而RAM是独立的组件,通过DATA,ADDRESS INPUT、READ ENABLE、WRITE ENABLE线与CPU相互通信。
我们目前做的只是简化版CPU,下一节,我们将给CPU拓展更多指令!
8.指令和程序
上一章我们用ALU、寄存器、RAM做了个简单的中央处理单元——CPU,这节课我们来给上节课做的CPU一些指令运行,即——编程!
CPU之所以强大,就是因为它是可编程的。如果写入不同指令,就会执行不同任务。CPU是硬件,它可以被软件控制!
我们知道RAM里面的指令前4位是指令表,后4为是地址,不如直接将二进制码换成汇编语言,更加方便易理解,这样就提升了一个抽象了。
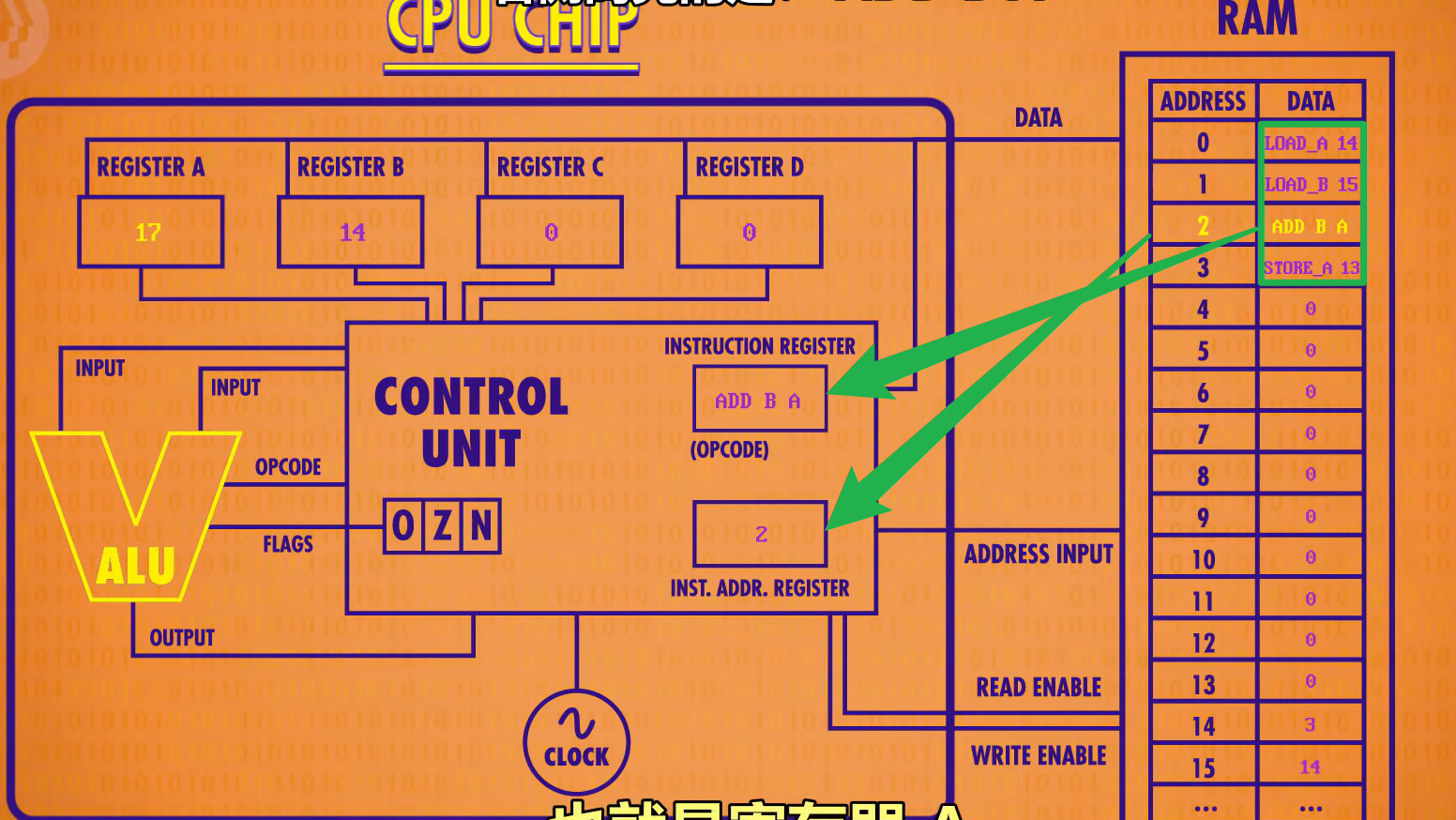
CPU还有很多指令,如下,数据和指令是存在一个内存条里面的。HLT是程序结束指令,通常在数据与指令内存之间。

JUMP指令无非就是覆盖掉指令地址寄存器里面存的值。使得CPU读取指定地址处的指令。
如下原本是会继续读取地址为5的指令的,但是JUMP 2代表重新读取地址为2的值了。注意这里是一个永久循环,永远不会到达HALT,程序永远不会结束。这就是永久循环的原理。
So, our hypothetical CPU is very basic – all of its instructions are 8 bits long,
我们这里假设的 CPU 很基础,所有指令都是 8 位,
with the opcode occupying only the first four bits.
操作码只占了前面 4 位
So even if we used every combination of 4 bits, our CPU would only be able to support,a maximum of 16 different instructions.
即便用尽 4 位,也只能代表 16 个指令
On top of that, several of our instructions used the last 4 bits to specify a memory location.
而且我们有几条指令,是用后 4 位来指定内存地址
But again, 4 bits can only encode 16 different values,
因为 4 位最多只能表示 16 个值,
meaning we can address a maximum of 16 memory locations - that’s not a lot to work with.
所以我们只能操作 16 个地址,这可不多.
For example, we couldn’t even JUMP to location 17,
我们甚至不能 JUMP 17
because we literally can’t fit the number 17 into 4 bits.
因为 4 位二进制无法表示数字 17
For this reason, real, modern CPUs use two strategies.
因此,真正的现代 CPU 用两种策略
The most straightforward approach is just to have bigger instructions, with more bits,like 32 or 64 bits.
最直接的方法是用更多位来代表指令,比如 32 位或 64 位
This is called the instruction length.
这叫 指令长度法
Unsurprisingly.
毫不意外
The second approach is to use variable length instructions.
第二个策略是 “可变指令长度法”
For example, imagine a CPU that uses 8 bit opcodes.
举个例子,比如某个 CPU 用 8 位长度的操作码
When the CPU sees an instruction that needs no extra values, like the HALT instruction,
如果看到 HALT 指令,HALT 不需要额外数据
it can just execute it immediately.
那么会马上执行.
However, if it sees something like a JUMP instruction, it knows it must also fetch
如果看到 JUMP,它得知道位置值
the address to jump to, which is saved immediately behind the JUMP instruction in memory.
这个值在 JUMP 的后面
This is called, logically enough, an Immediate Value.
这叫 “立即值”
In such processor designs, instructions can be any number of bytes long,
这样设计,指令可以是任意长度
which makes the fetch cycle of the CPU a tad more complicated.
但会让读取阶段复杂一点点
Now, our example CPU and instruction set is hypothetical,
要说明的是,我们拿来举例的 CPU 和指令集都是假设的,
designed to illustrate key working principles.
是为了展示核心原理
So I want to leave you with a real CPU example.
所以我们来看个真的 CPU 例子.
In 1971, Intel released the 4004 processor.
1971年,英特尔发布了 4004 处理器.
It was the first CPU put all into a single chip
这是第一次把 CPU 做成一个芯片 , 给后来的英特尔处理器打下了基础

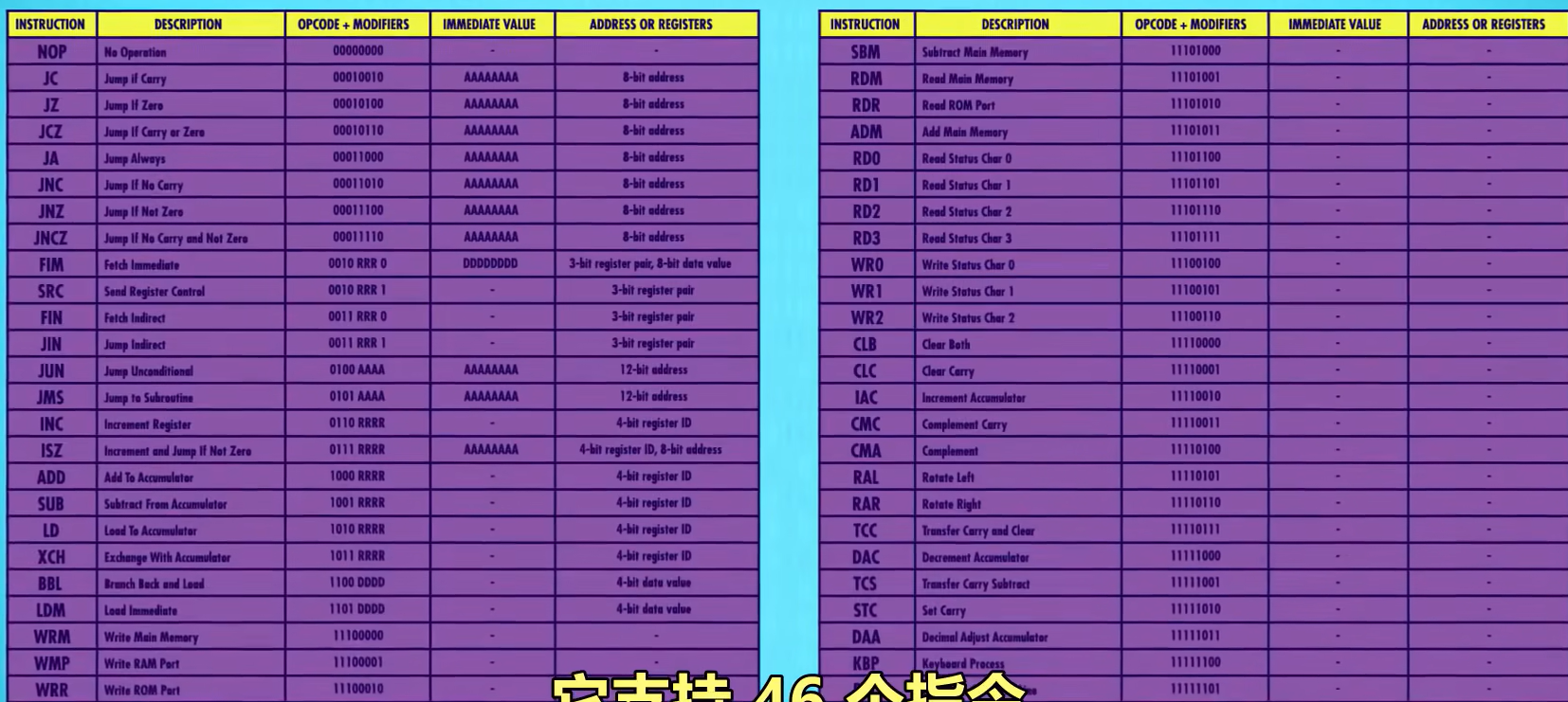
It supported 46 instructions, shown here.
它支持 46 个指令
Which was enough to build an entire working computer.
足够做一台能用的电脑
And it used many of the instructions we’ve talked about like JUMP ADD SUBTRACT and LOAD.
它用了很多我们说过的指令,比如 JUMP ADD SUB LOAD
It also uses 8-bit immediate values, like we just talked about, for things like JUMP,in order to address more memory.
它也用 8 位的"立即值"来执行 JUMP, 以表示更多内存地址.
And this huge growth in instruction set size is due in large part to extra bells and whistles
指令越来越多,是因为给 CPU 设计了越来越多功能
that have been added to processor designs overtime, which we’ll talk about next episode.
下集我们会讲
9.高级CPU设计——流水线与缓存
这篇关于【计算机科学速成课】笔记二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






