本文主要是介绍Tensorflow - Tutorial (6) : TensorBoard 可视化工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. TensorBoard
为了更方便 TensorFlow 程序的理解、调试与优化,TensorFlow发布了一套叫做 TensorBoard 的可视化工具。可以用 TensorBoard 来展现 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。TensorBoard可生成以下4类信息:
- Event: 展示训练过程中的统计数据(最值,均值等,误差)变化情况
- Image: 展示训练过程中记录的图像
- Graph: 展示模型的结构
- Histogram: 展示训练过程中记录的数据的分布图
本文以 Tensorflow - Tutorial (4) 中的CNN手写数字识别代码为例,对TensorBoard的相关操作进行演示
用 with tf.name_scope() 为变量名划定范围,同一范围的变量在图中属于同一层级,并且通过”name”属性对变量指定名称
with tf.name_scope('inputs'):X = tf.placeholder("float", [None, 28, 28, 1], name = 'X')Y = tf.placeholder("float", [None, 10], name = 'Y')通过下面代码可查看权重w在训练过程中的变化情况,其中”w_1”是生成的图表的名字
tf.histogram_summary("w_1", w)通过如下语句查看测试集中预测准确率和loss随迭代次数的变化情况
tf.scalar_summary("accuracy", acc_op)
tf.scalar_summary('loss', cost)通过如下语句将所有的summary进行合并,一起进行SummaryWriter
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("logs/", sess.graph)每一轮迭代结束后,通过如下语句记录所有的summary
writer.add_summary(summary, i) # Write summary代码运行完毕后,logs文件夹下会生成一个包含time stamp的tfevents文件,进入logs文件夹所在目录,在命令行中输入如下命令来启动TensorBoard
tensorboard --inspect --logdir=logs/用浏览器打开命令行中显示的url地址,若在结果显示上出现问题,可参考:Frequently Asked Questions

2. 代码
#!/usr/bin/env python
#coding:utf-8
import tensorflow as tf
import numpy as np
import input_databatch_size = 128
test_size = 256def init_weights(shape, s):return tf.Variable(tf.random_normal(shape, stddev=0.01), name = s)def model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden):with tf.name_scope('layer_1'): l1a = tf.nn.relu(tf.nn.conv2d(X, w, # l1a shape=(?, 28, 28, 32)strides=[1, 1, 1, 1], padding='SAME'))l1 = tf.nn.max_pool(l1a, ksize=[1, 2, 2, 1], # l1 shape=(?, 14, 14, 32)strides=[1, 2, 2, 1], padding='SAME')l1 = tf.nn.dropout(l1, p_keep_conv)with tf.name_scope('layer_2'): l2a = tf.nn.relu(tf.nn.conv2d(l1, w2, # l2a shape=(?, 14, 14, 64)strides=[1, 1, 1, 1], padding='SAME'))l2 = tf.nn.max_pool(l2a, ksize=[1, 2, 2, 1], # l2 shape=(?, 7, 7, 64)strides=[1, 2, 2, 1], padding='SAME')l2 = tf.nn.dropout(l2, p_keep_conv)with tf.name_scope('layer_3'): l3a = tf.nn.relu(tf.nn.conv2d(l2, w3, # l3a shape=(?, 7, 7, 128)strides=[1, 1, 1, 1], padding='SAME'))l3 = tf.nn.max_pool(l3a, ksize=[1, 2, 2, 1], # l3 shape=(?, 4, 4, 128)strides=[1, 2, 2, 1], padding='SAME')l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]]) # reshape to (?, 2048)l3 = tf.nn.dropout(l3, p_keep_conv)with tf.name_scope('layer_4'):l4 = tf.nn.relu(tf.matmul(l3, w4))l4 = tf.nn.dropout(l4, p_keep_hidden)with tf.name_scope('layer_5'):pyx = tf.matmul(l4, w_o)return pyxmnist = input_data.read_data_sets("MNIST_data/", one_hot=True)trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
trX = trX.reshape(-1, 28, 28, 1)
teX = teX.reshape(-1, 28, 28, 1)
with tf.name_scope('inputs'):X = tf.placeholder("float", [None, 28, 28, 1], name = 'X')Y = tf.placeholder("float", [None, 10], name = 'Y')p_keep_conv = tf.placeholder("float", name = 'pro_dropout_conv') p_keep_hidden = tf.placeholder("float", name = 'pro_dropout_hidden')with tf.name_scope('weights'):w = init_weights([3, 3, 1, 32],"w_1") w2 = init_weights([3, 3, 32, 64],"w_2")w3 = init_weights([3, 3, 64, 128], "w_3")w4 = init_weights([128 * 4 * 4, 625], "w_4")w_o = init_weights([625, 10], "w_o")# Add histogram summaries for weightstf.histogram_summary("w_1", w)tf.histogram_summary("w_2", w2)tf.histogram_summary("w_3", w3)tf.histogram_summary("w_4", w4)tf.histogram_summary("w_o", w_o)py_x = model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden)
with tf.name_scope('loss'):cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(py_x, Y))tf.scalar_summary('loss', cost) # Add scalar summary for cost
with tf.name_scope('train'):train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
with tf.name_scope('prediction'):correct_pred = tf.equal(tf.argmax(Y, 1), tf.argmax(py_x, 1)) # Count correct predictionsacc_op = tf.reduce_mean(tf.cast(correct_pred, "float")) # Cast boolean to float to average# Add scalar summary for accuracytf.scalar_summary("accuracy", acc_op)
# Launch the graph in a session
with tf.Session() as sess:merged = tf.merge_all_summaries()writer = tf.train.SummaryWriter("logs/", sess.graph)# create a log writertf.initialize_all_variables().run()for i in range(30):loss_sum = 0.0training_batch = zip(range(0, len(trX), batch_size),range(batch_size, len(trX)+1, batch_size))for start, end in training_batch:_, loss_value, summary = sess.run([train_op, cost, merged], feed_dict={X: trX[start:end], Y: trY[start:end],p_keep_conv: 0.8, p_keep_hidden: 0.5})loss_sum +=loss_valueprint i, loss_sumsummary = sess.run(merged, feed_dict={X: teX, Y: teY, p_keep_conv: 1.0, p_keep_hidden: 1.0})writer.add_summary(summary, i) # Write summary3. 结果
- 在EVENTS中查看预测准确率和loss随迭代次数的变化情况
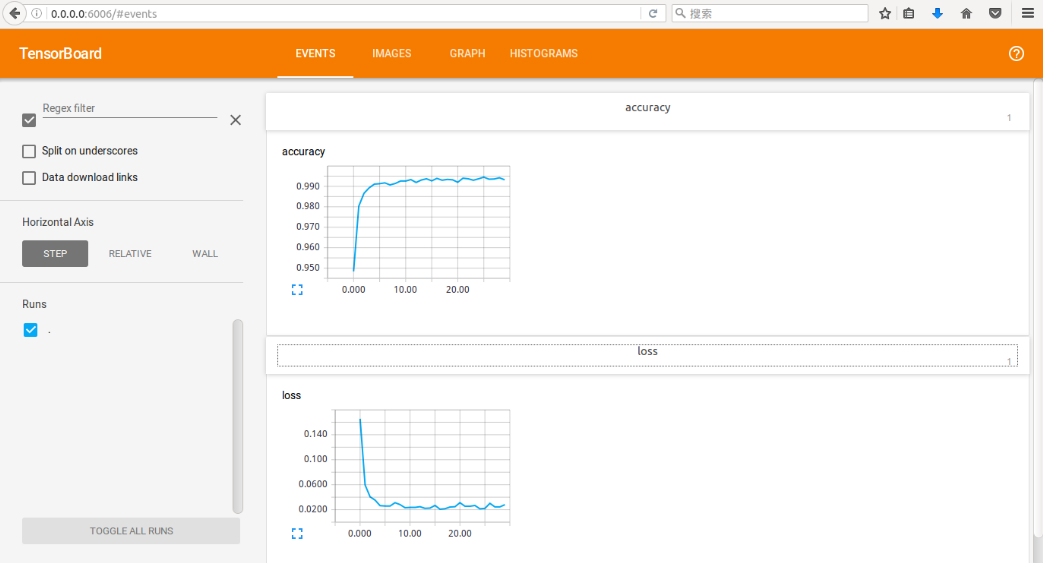
- 在GRAPH中查看CNN模型的结构
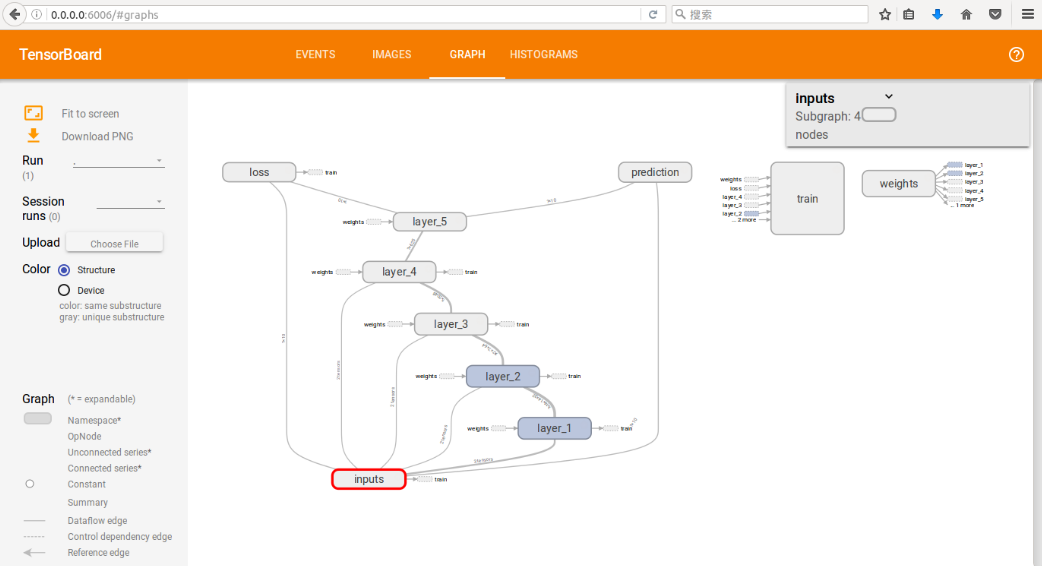
- 在HISTOGRAMS中查看权重的变化情况
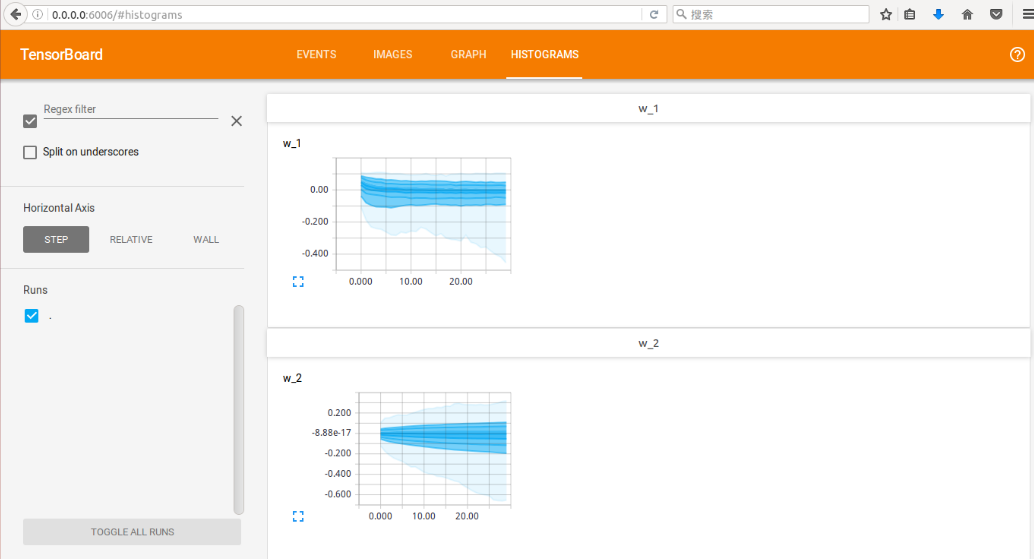
这篇关于Tensorflow - Tutorial (6) : TensorBoard 可视化工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







