本文主要是介绍【redis】Redis数据类型(五)ZSet类型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 类型介绍
- 特点
- 补充
- 使用场景
- Zset类型数据结构
- ziplist:压缩列表(参考之前的文章)
- skiplist:跳表
- 解析
- 面试题:MySQL索引为什么用B+树而不用跳表
- 区别
- 总结
- 常用命令
- ZADD
- 示例
- ZREM
- 示例
- ZCARD
- 示例
- ZCOUNT
- 示例
- ZSCORE
- 示例
- ZINCRBY
- 示例
- ZRANGE
- 示例
- ZREVRANGE
- 示例
- ZRANGEBYSCORE
- 示例
- ZREVRANGEBYSCORE
- 示例
- ZRANK
- 示例
- ZREVRANK
- 示例
- ZREMRANGEBYRANK
- 示例
- ZREMRANGEBYSCORE
- 示例
- ZINTERSTORE
- 示例
- ZUNIONSTORE
- 示例
类型介绍
- Zset 是 set 的升级版,它在 set 的基础上增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列。
- 在 Zset 中,集合元素的添加、删除和查找的时间复杂度都是 O(1)。这得益于 Redis 使用的是一种叫做跳跃列表(skiplist)的数据结构来实现 Zset
- 访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
- 此外,有序集合中的元素是按顺序获取的(因此它们不是按请求排序的,顺序是用于表示有序集合的数据结构的特性)。它们根据以下规则排序:
- 如果 A 和 B 是具有不同分数的两个元素, 如果 A.score 是 > B.score,则 A > B。
- 如果 A 和 B 的分数完全相同,则 A > B 如果 A 字符串按字典顺序大于 B 字符串。A 和 B 字符串不能相等,因为排序集只有唯一元素。
特点
- Redis有序集合跟集合一样也是String类型元素的集合,且不允许重复的成员
- 不同的是每个元素都会关联一个double类型的分数,Redis正是通过这个分数来为集合中的元素进行从小到大的排序
- 有序集合的成员是唯一的,但是分数(score)是可以重复的
- 集合是通过哈希表实现的,集合中最大的成员数为2的32次方-1,可以存储40多亿个成员,Zset集合是有序不可重复的
- 自动更新排序:当你修改 Zset 中的元素的 score 值时,元素的位置会自动按新的 score 值进行调整。
补充
list、set、hash、zset这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
- create if not exists:容器不存在则创建
- drop if no elements:如果容器中没有元素,则立即删除容器,释放内存
使用场景
- 排行榜:Zset 非常适合用于实现各种排行榜(微博热搜、游戏天梯排行、成绩排行…)。例如,你可以将用户的 ID 作为元素,用户的分数作为分数,然后使用 Zset 来存储和排序所有用户的分数。你可以很容易地获取到分数最高的用户,或者获取到任何用户的排名。
- 时间线:你可以使用 Zset 来实现时间线功能。例如,你可以将发布的消息作为元素,消息的发布时间作为分数,然后使用 Zset 来存储和排序所有的消息。你可以很容易地获取到最新的消息,或者获取到任何时间段内的消息。
- 带权重的队列:Zset 可以用于实现带权重的队列。例如,你可以将任务作为元素,任务的优先级作为分数,然后使用 Zset 来存储和排序所有的任务。你可以很容易地获取到优先级最高的任务,或者按优先级顺序执行任务。
- 延时队列:你可以将需要延时处理的任务作为元素,任务的执行时间作为分数,然后使用 Zset 来存储和排序所有的任务。你可以定期扫描 Zset,处理已经到达执行时间的任务。
Zset类型数据结构
-
zset(有序集合)是Redis中最常问的数据结构。它类似于Java语言中的SortedSet和HashMap的结合体,它一方面通过set来保证内部value值的唯一性,另一方面通过value的score(权重)来进行排序。这个排序的功能是通过Skip List(跳跃列表)来实现的。
-
zset(有序集合)的最后一个元素value被移除后,数据结构被自动删除,内存被回收。
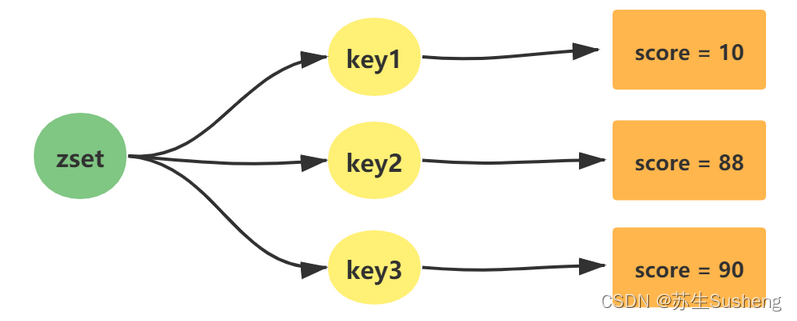
-
Redis 的 Zset(有序集合)类型的底层实现会根据实际情况选择使用压缩列表(ziplist)或者跳跃表(skiplist)。Redis 会根据实际情况动态地在这两种底层结构之间切换,以在内存使用和性能之间找到一个平衡。
ziplist:压缩列表(参考之前的文章)
- 当 Zset 存储的元素数量小于 zset-max-ziplist-entries 的值,且所有元素的最大长度小于 zset-max-ziplist-value 的值时,Redis 会选择使用压缩列表作为底层实现。压缩列表占用的内存较少,但是在需要修改数据时,可能需要对整个压缩列表进行重写,性能较低。
- 压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了
skiplist:跳表
- 当 Zset 存储的元素数量超过 zset-max-ziplist-entries 的值,或者任何元素的长度超过 zset-max-ziplist-value 的值时,Redis 会将底层结构从压缩列表转换为跳跃表。跳跃表的查找和修改数据的性能较高,但是占用的内存也较多。
- 类似于 leetcode 上的一个经典题目,“复制带随机指针的链表”,跳表也是链表,不同于普通的链表,每一个节点上有多个指针域,巧妙的搭配这些指针域的指向就可以做到,从跳表上查询元素的时间复杂度是 O(logN),相比于树形结构,更适合范围获取元素.
- 跳跃表是一种可以进行快速查找的有序数据结构,它通过维护多级索引来实现快速查找。这种方式的优点是查找和修改数据的性能较高,但是占用的内存也较多。当 Zset 存储的元素数量较多,或者元素的字符串长度较长时,Redis 会选择使用跳跃表作为底层实现。
- 跳跃表(skiplist)是一种可以进行快速查找的有序数据结构,它通过维护多级索引来实现快速查找。
typedef struct zskiplistNode {robj *obj;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned int span;} level[];} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;} zskiplist;- zskiplistNode 结构体表示跳跃表中的一个节点,包含元素对象(obj)、分数(score)、指向前一个节点的指针(backward)和一个包含多个层的数组(level)。每一层都包含一个指向下一个节点的指针(forward)和一个表示当前节点到下一个节点的跨度(span)。
- zskiplist 结构体表示一个跳跃表,包含头节点(header)、尾节点(tail)、跳跃表中的节点数量(length)和当前跳跃表的最大层数(level)。
解析
- 跳跃表的查找、插入和删除操作的时间复杂度都是 O(logN),其中 N 是跳跃表中的元素数量。这使得跳跃表在处理大量数据时具有很高的性能。
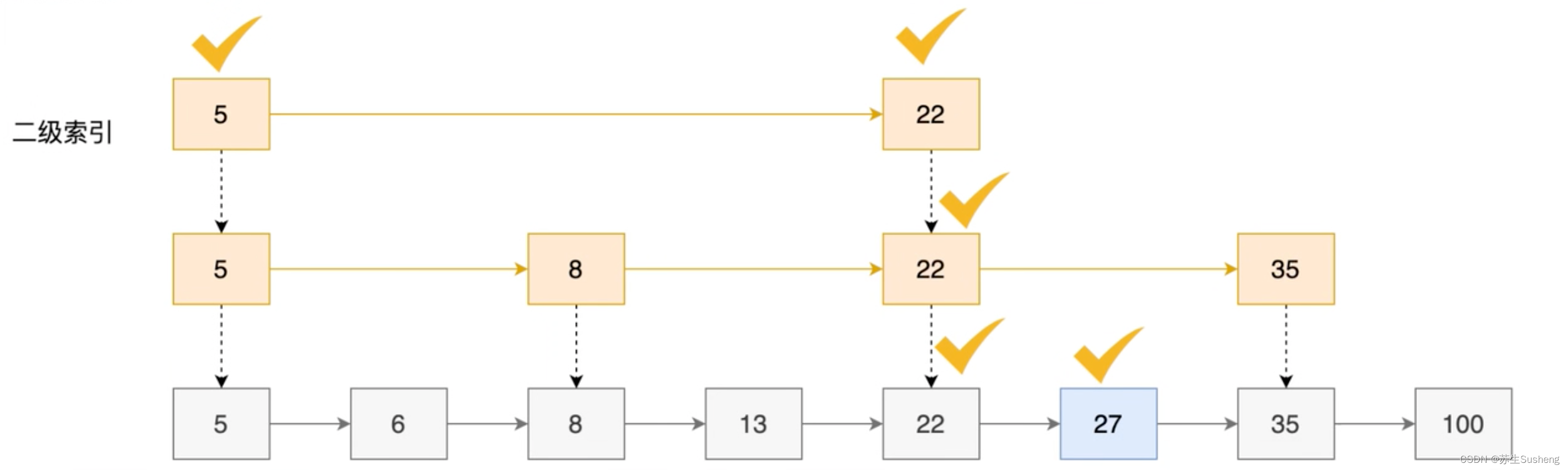
- 跳表在链表的基础上增加了多级索引,通过多级索引位置的专跳,实现了快速查找元素
- 例如:在下列数据中查询27

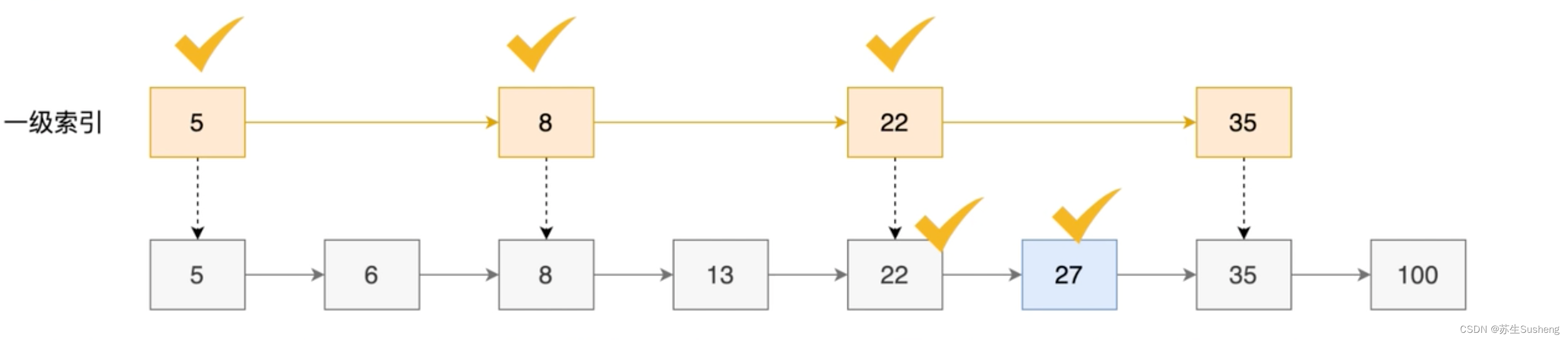
二级索引(一次索引基础上,每间隔一个元素):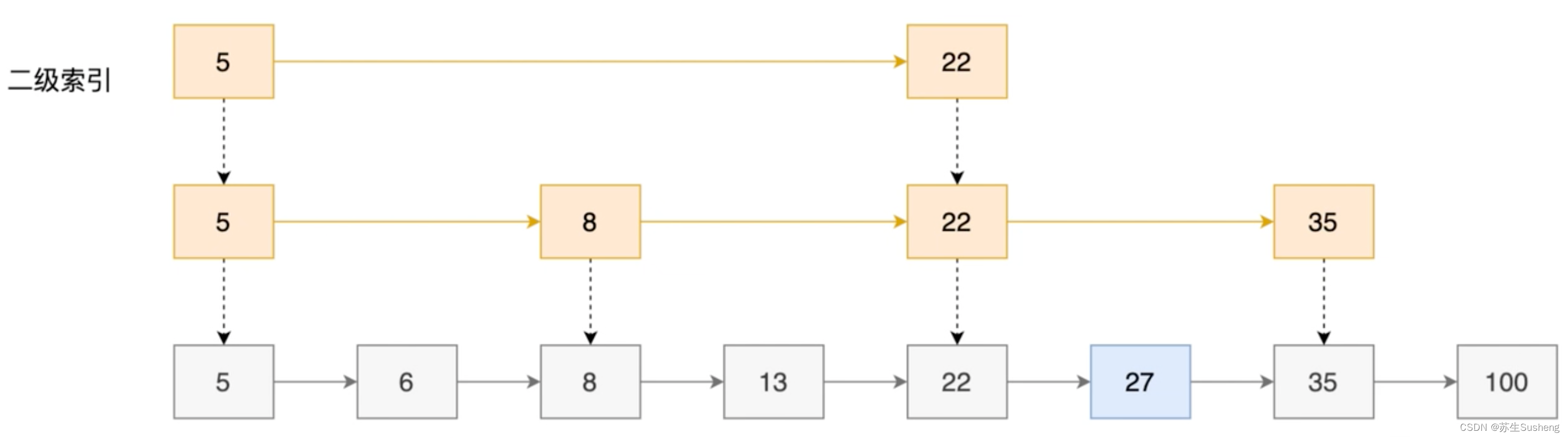
面试题:MySQL索引为什么用B+树而不用跳表
区别
- 结构差异:B+ 树是一种多路搜索树,每个节点可以有多个子节点,而跳表是一种基于链表的数据结构,每个节点只有一个下一个节点,但可以有多个快速通道指向后面的节点。
- 空间利用率:B+ 树的磁盘读写操作是以页(通常是 4KB)为单位的,每个节点存储多个键值对,可以更好地利用磁盘空间,减少 I/O 操作。而跳表的空间利用率相对较低。
- 插入和删除操作:跳表的插入和删除操作相对简单,时间复杂度为 O(logN),并且不需要像 B+ 树那样进行复杂的节点分裂和合并操作。
- 范围查询:B+ 树的所有叶子节点形成了一个有序链表,因此非常适合进行范围查询。而跳表虽然也可以进行范围查询,但效率相对较低。
总结
-
B+ 树和跳表不能简单地相互替换。在需要大量进行磁盘 I/O 操作和范围查询的场景(如数据库索引)中,B+ 树可能是更好的选择。而在主要进行内存操作,且需要频繁进行插入和删除操作的场景(如 Redis)中,跳表可能更有优势。
-
Mysql 数据库是持久化数据库,即是存储到磁盘上的,因此查询时要求更少磁盘 IO,且 Mysql 是读多写少的场景较多,显然 B+ 树更加适合M ysql。
Redis 的 ZSet 为什么使用跳表而不是B+树
- Redis 是内存存储,不存在 IO 的瓶颈,所以跳表的层数的耗时可以忽略不计,而且插入数据时不需要开销以平衡数据结构(写多)。
常用命令
ZADD
- 语法:zadd key score member [[score member] [score member] …]
- 解释:
- 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
- 如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
- score 值可以是整数值或双精度浮点数。
- 如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
- 当 key 存在但不是有序集类型时,返回一个错误。
- 对有序集的更多介绍请参见 sorted set 。
- 注:在 Redis 2.4 版本以前, ZADD 每次只能添加一个元素
- 时间复杂度:O(M*log(N)), N 是有序集的基数, M 为成功添加的新成员的数量。
- 返回值:被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员
示例
# 添加单个元素
127.0.0.1:6379[2]> ZADD page_rank 10 google.com
(integer) 1
# 添加多个元素
127.0.0.1:6379[2]> ZADD page_rank 9 baidu.com 8 bing.com
(integer) 2
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
# 添加已存在元素,且 score 值不变
127.0.0.1:6379[2]> ZADD page_rank 10 google.com
(integer) 0
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES # 没有改变
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
# 添加已存在元素,但是改变 score 值
127.0.0.1:6379[2]> ZADD page_rank 6 bing.com
(integer) 0
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES # bing.com 元素的 score 值被改变
1) "bing.com"
2) "6"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
ZREM
- 语法:zrem key member [member …]
- 解释:
- 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
- 当 key 存在但不是有序集类型时,返回一个错误。
- 注:在 Redis 2.4 版本以前, ZREM 每次只能删除一个元素
- 时间复杂度:O(M*log(N)), N 为有序集的基数, M 为被成功移除的成员的数量
- 返回值:被成功移除的成员的数量,不包括被忽略的成员。
示例
# 添加单个元素
# 测试数据
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
# 移除单个元素
127.0.0.1:6379[2]> ZREM page_rank google.com
(integer) 1
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
# 移除多个元素
127.0.0.1:6379[2]> ZREM page_rank baidu.com bing.com
(integer) 2
127.0.0.1:6379[2]> ZRANGE page_rank 0 -1 WITHSCORES
(empty list or set)
# 移除不存在元素
127.0.0.1:6379[2]> ZREM page_rank non-exists-element
(integer) 0
ZCARD
- 语法:zcard key
- 解释:返回有序集 key 的基数。
- 时间复杂度:O(1)
- 返回值:
- 当 key 存在且是有序集类型时,返回有序集的基数。
- 当 key 不存在时,返回 0 。
示例
127.0.0.1:6379[2]> ZADD salary 2000 tom # 添加一个成员
(integer) 1
127.0.0.1:6379[2]> ZCARD salary
(integer) 1
127.0.0.1:6379[2]> ZADD salary 5000 jack # 再添加一个成员
(integer) 1
127.0.0.1:6379[2]> ZCARD salary
(integer) 2
127.0.0.1:6379[2]> EXISTS non_exists_key # 对不存在的 key 进行 ZCARD 操作
(integer) 0
127.0.0.1:6379[2]> ZCARD non_exists_key
(integer) 0
ZCOUNT
- 语法:zcount key min max
- 解释:
- 返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或max )的成员的数量。
- 关于参数 min 和 max 的详细使用方法,请参考 ZRANGEBYSCORE 命令
- 时间复杂度:O(log(N)+M), N 为有序集的基数, M 为值在 min 和 max 之间的元素的数量。
- 返回值:score 值在 min 和 max 之间的成员的数量。
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 测试数据
1) "jack"
2) "2000"
3) "peter"
4) "3500"
5) "tom"
6) "5000"
127.0.0.1:6379[2]> ZCOUNT salary 2000 5000 # 计算薪水在 2000-5000 之间的人数
(integer) 3
127.0.0.1:6379[2]> ZCOUNT salary 3000 5000 # 计算薪水在 3000-5000 之间的人数
(integer) 2
ZSCORE
- 语法: zscore key member
- 解释:
- 返回有序集 key 中,成员 member 的 score 值。
- 如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil
- 时间复杂度:O(1)
- 返回值:member 成员的 score 值,以字符串形式表示。
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 测试数据
1) "tom"
2) "2000"
3) "peter"
4) "3500"
5) "jack"
6) "5000"
127.0.0.1:6379[2]> ZSCORE salary peter # 注意返回值是字符串
"3500"
ZINCRBY
- 语法:zincrby key increment member
- 解释:
- 为有序集 key 的成员 member 的 score 值加上增量 increment 。
- 可以通过传递一个负数值 increment ,让 score 减去相应的值,比如
ZINCRBY key -5 member,就是让 member 的 score 值减去 5 。 - 当 key 不存在,或 member 不是 key 的成员时,
ZINCRBY key increment member等同于ZADD key increment member。 - 当 key 不是有序集类型时,返回一个错误。
- score 值可以是整数值或双精度浮点数。
- 时间复杂度:O(log(N))
- 返回值:member 成员的新 score 值,以字符串形式表示。
示例
127.0.0.1:6379[2]> ZSCORE salary tom
"2000"
127.0.0.1:6379[2]> ZINCRBY salary 2000 tom # tom 加薪啦!
"4000"
ZRANGE
- 语法:zrange key start stop [WITHSCORES]
- 解释:
- 返回有序集 key 中,指定区间内的成员。
- 其中成员的位置按 score 值递增(从小到大)来排序。
- 具有相同 score 值的成员按字典序(lexicographical order )来排列。
- 如果你需要成员按 score 值递减(从大到小)来排列,请使用 ZREVRANGE 命令。
- 下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。
- 你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
- 超出范围的下标并不会引起错误。
- 比如说,当 start 的值比有序集的最大下标还要大,或是 start > stop 时, ZRANGE命令只是简单地返回一个空列表。
- 另一方面,假如 stop 参数的值比有序集的最大下标还要大,那么 Redis 将 stop 当作最大下标来处理。
- 可以通过使用 WITHSCORES 选项,来让成员和它的 score 值一并返回,返回列表以 value1,score1, …, valueN,scoreN 的格式表示。
- 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数
- 返回值:指定区间内,带有 score 值(可选)的有序集成员的列表
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 显示整个有序集成员
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"
127.0.0.1:6379[2]> ZRANGE salary 1 2 WITHSCORES #显示有序集下标区间 1 至 2 的成员
1) "tom"
2) "5000"
3) "boss"
4) "10086"
127.0.0.1:6379[2]> ZRANGE salary 0 200000 WITHSCORES #测试 end 下标超出最大下标时的情况
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"
127.0.0.1:6379[2]> ZRANGE salary 200000 3000000 WITHSCORES # 测试当给定区间不存在于有序集时的情况
(empty list or set)
ZREVRANGE
- 语法: zrevrange key start stop [WITHSCORES]
- 解释:
- 返回有序集 key 中,指定区间内的成员。
- 其中成员的位置按 score 值递减(从大到小)来排列。
- 具有相同 score 值的成员按字典序的逆序(reverse lexicographical order)排列。
- 除了成员按 score 值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和ZRANGE 命令一样
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数
- 返回值:指定区间内,带有 score 值(可选)的有序集成员的列表
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 递增排列
1) "peter"
2) "3500"
3) "tom"
4) "4000"
5) "jack"
6) "5000"
127.0.0.1:6379[2]> ZREVRANGE salary 0 -1 WITHSCORES # 递减排列
1) "jack"
2) "5000"
3) "tom"
4) "4000"
5) "peter"
6) "3500"
ZRANGEBYSCORE
- 语法: zrangebyscore
- 解释:
- 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
- 具有相同 score 值的成员按字典序(lexicographical order)来排列(该属性是有序集提供的,不需要额外的计算)。
- 可选的 LIMIT 参数指定返回结果的数量及区间(就像 SQL 中的 SELECT LIMIT offset,count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。
- 可选的 WITHSCORES 参数决定结果集是单单返回有序集的成员,还是将有序集成员及其score 值一起返回。
- 区间及无限
- min 和 max 可以是 -inf 和 +inf ,这样一来,你就可以在不知道有序集的最低和最高 score 值的情况下,使用 ZRANGEBYSCORE 这类命令。
- 默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
- 例如
ZRANGEBYSCORE zset (1 5返回所有符合条件 1 < score <= 5 的成员,而ZRANGEBYSCORE zset (5 (10则返回所有符合条件 5 < score < 10 的成员
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数
- 返回值:指定区间内,带有 score 值(可选)的有序集成员的列表
示例
127.0.0.1:6379[2]> ZADD salary 2500 jack # 测试数据
(integer) 0
127.0.0.1:6379[2]> ZADD salary 5000 tom
(integer) 0
127.0.0.1:6379[2]> ZADD salary 12000 peter
(integer) 0
127.0.0.1:6379[2]> ZRANGEBYSCORE salary -inf +inf # 显示整个有序集
1) "jack"
2) "tom"
3) "peter"
127.0.0.1:6379[2]> ZRANGEBYSCORE salary -inf +inf WITHSCORES # 显示整个有序集及成员的 score 值
1) "jack"
2) "2500"
3) "tom"
4) "5000"
5) "peter"
6) "12000"
127.0.0.1:6379[2]> ZRANGEBYSCORE salary -inf 5000 WITHSCORES # 显示工资 <=5000的所有成员
1) "jack"
2) "2500"
3) "tom"
4) "5000"
127.0.0.1:6379[2]> ZRANGEBYSCORE salary (5000 400000 # 显示工资大于 5000小于等于 400000 的成员
1) "peter"
ZREVRANGEBYSCORE
- 语法:zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]
- 解释:
- 返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成员。有序集成员按 score 值递减(从大到小)的次序排列。
- 具有相同 score 值的成员按字典序的逆序(reverse lexicographical order )排列。
- 除了成员按 score 值递减的次序排列这一点外, ZREVRANGEBYSCORE 命令的其他方面和 ZRANGEBYSCORE 命令一样。
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数
- 返回值:指定区间内,带有 score 值(可选)的有序集成员的列表
示例
127.0.0.1:6379[2]> ZADD salary 10086 jack
(integer) 1
127.0.0.1:6379[2]> ZADD salary 5000 tom
(integer) 1
127.0.0.1:6379[2]> ZADD salary 7500 peter
(integer) 1
127.0.0.1:6379[2]> ZADD salary 3500 joe
(integer) 1
127.0.0.1:6379[2]> ZREVRANGEBYSCORE salary +inf -inf # 逆序排列所有成员
1) "jack"
2) "peter"
3) "tom"
4) "joe"
127.0.0.1:6379[2]> ZREVRANGEBYSCORE salary 10000 2000 # 逆序排列薪水介于 10000 和2000 之间的成员
1) "peter"
2) "tom"
3) "joe"
ZRANK
- 语法:zrevrangebyscore key max min [WITHSCORES] [LIMIT offset count]
- 解释:
- 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。
- 排名以 0 为底,也就是说, score 值最小的成员排名为 0 。
- 使用 ZREVRANK 命令可以获得成员按 score 值递减(从大到小)排列的排名
- 时间复杂度:O(log(N))
- 返回值:
- 如果 member 是有序集 key 的成员,返回 member 的排名。
- 如果 member 不是有序集 key 的成员,返回 nil
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值
1) "peter"
2) "3500"
3) "tom"
4) "4000"
5) "jack"
6) "5000"
127.0.0.1:6379[2]> ZRANK salary tom # 显示 tom 的薪水排名,第二
(integer) 1
ZREVRANK
- 语法: zrevrank key member
- 解释:
- 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递减(从大到小)排序。
- 排名以 0 为底,也就是说, score 值最大的成员排名为 0 。
- 使用 ZRANK 命令可以获得成员按 score 值递增(从小到大)排列的排名
- 时间复杂度:O(log(N))
- 返回值:
- 如果 member 是有序集 key 的成员,返回 member 的排名。
- 如果 member 不是有序集 key 的成员,返回 nil
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 测试数据
1) "jack"
2) "2000"
3) "peter"
4) "3500"
5) "tom"
6) "5000"
127.0.0.1:6379[2]> ZREVRANK salary peter # peter 的工资排第二
(integer) 1
127.0.0.1:6379[2]> ZREVRANK salary tom # tom 的工资最高
(integer) 0
ZREMRANGEBYRANK
- 语法: ZREMRANGEBYRANK key start stop
- 解释:
- 移除有序集 key 中,指定排名(rank)区间内的所有成员。
- 区间分别以下标参数 start 和 stop 指出,包含 start 和 stop 在内。
- 下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1表示有序集第二个成员,以此类推。
- 你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类
推。
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量
- 返回值:被移除成员的数量
示例
127.0.0.1:6379[2]> ZADD salary 2000 jack
(integer) 1
127.0.0.1:6379[2]> ZADD salary 5000 tom
(integer) 1
127.0.0.1:6379[2]> ZADD salary 3500 peter
(integer) 1
127.0.0.1:6379[2]> ZREMRANGEBYRANK salary 0 1 # 移除下标 0 至 1 区间内的成员
(integer) 2
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 有序集只剩下一个成员
1) "tom"
2) "5000"
ZREMRANGEBYSCORE
- 语法:zremrangebyscore key min max
- 解释:
- 移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。
- 自版本 2.1.6 开始, score 值等于 min 或 max 的成员也可以不包括在内,详情请参见 ZRANGEBYSCORE 命令。
- 时间复杂度:O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量
- 返回值:被移除成员的数量
示例
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 显示有序集内所有成员及其
score 值
1) "tom"
2) "2000"
3) "peter"
4) "3500"
5) "jack"
6) "5000"
127.0.0.1:6379[2]> ZREMRANGEBYSCORE salary 1500 3500 # 移除所有薪水在 1500 到
3500 内的员工
(integer) 2
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES # 剩下的有序集成员
1) "jack"
2) "5000"
ZINTERSTORE
- 语法:ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
- 解释:
- 计算给定的一个或多个有序集的交集,其中给定 key 的数量必须以 numkeys 参数指定,并将该交集(结果集)储存到 destination 。
- 默认情况下,结果集中某个成员的 score 值是所有给定集下该成员 score 值之和.
- 关于 WEIGHTS 和 AGGREGATE 选项的描述,参见 ZUNIONSTORE 命令。
- 时间复杂度:O(NK)+O(Mlog(M)), N 为给定 key 中基数最小的有序集, K 为给定有序集的数量,M 为结果集的基数
- 返回值:保存到 destination 的结果集的基数
示例
127.0.0.1:6379[2]> ZADD mid_test 70 "Li Lei"
(integer) 1
127.0.0.1:6379[2]> ZADD mid_test 70 "Han Meimei"
(integer) 1
127.0.0.1:6379[2]> ZADD mid_test 99.5 "Tom"
(integer) 1
127.0.0.1:6379[2]> ZADD fin_test 88 "Li Lei"
(integer) 1
127.0.0.1:6379[2]> ZADD fin_test 75 "Han Meimei"
(integer) 1
127.0.0.1:6379[2]> ZADD fin_test 99.5 "Tom"
(integer) 1
127.0.0.1:6379[2]> ZINTERSTORE sum_point 2 mid_test fin_test
(integer) 3
127.0.0.1:6379[2]> ZRANGE sum_point 0 -1 WITHSCORES # 显式有序集内所有成员及其score 值
1) "Han Meimei"
2) "145"
3) "Li Lei"
4) "158"
5) "Tom"
6) "199"
ZUNIONSTORE
- 语法:: ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
- 解释:
- 计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并将该并集(结果集)储存到 destination 。
- 默认情况下,结果集中某个成员的 score 值是所有给定集下该成员 score 值之 和 。
- WEIGHTS
- 使用 WEIGHTS 选项,你可以为 每个 给定有序集 分别 指定一个乘法因子(multiplication factor),每个给定有序集的所有成员的 score 值在传递给聚合函数(aggregation function)之前都要先乘以该有序集的因子。
- 如果没有指定 WEIGHTS 选项,乘法因子默认设置为 1
- AGGREGATE
- 使用 AGGREGATE 选项,你可以指定并集的结果集的聚合方式。
- 默认使用的参数 SUM ,可以将所有集合中某个成员的 score 值之 和 作为结果集中该成员的 score 值;使用参数 MIN ,可以将所有集合中某个成员的 最小 score 值作为结果集中该成员的 score 值;而参数 MAX 则是将所有集合中某个成员的 最大 score 值作为结果集中该成员的 score 值。
- 时间复杂度:O(N)+O(M log(M)), N 为给定有序集基数的总和, M 为结果集的基数
- 返回值:保存到 destination 的结果集的基数
示例
127.0.0.1:6379[2]> ZRANGE programmer 0 -1 WITHSCORES
1) "peter"
2) "2000"
3) "jack"
4) "3500"
5) "tom"
6) "5000"
127.0.0.1:6379[2]> ZRANGE manager 0 -1 WITHSCORES
1) "herry"
2) "2000"
3) "mary"
4) "3500"
5) "bob"
6) "4000"
127.0.0.1:6379[2]> ZUNIONSTORE salary 2 programmer manager WEIGHTS 1 3 # 公司决定加薪。。。除了程序员。。。
(integer) 6
127.0.0.1:6379[2]> ZRANGE salary 0 -1 WITHSCORES
1) "peter"
2) "2000"
3) "jack"
4) "3500"
5) "tom"
6) "5000"
7) "herry"
8) "6000"
9) "mary"
10) "10500"
11) "bob"
12) "12000"
这篇关于【redis】Redis数据类型(五)ZSet类型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






