本文主要是介绍JDK14特性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
JDK14
- 1 概述
- 2 语法层面的变化
- 1_instanceof的模式匹配(预览)
- 2_switch表达式(标准)
- 3_文本块改进(第二次预览)
- 4_Records 记录类型(预览 JEP359)
- 3 API层面的变化
- 4 关于GC
- 1_G1的NUMA内存分配优化
- 2_弃用Serial+CMS,ParNew+Serial Old
- 3_删除CMS
- 4_ZGC on macOS and Windows
- 4 其他变化
- 1_友好的空指针异常提示
- 2_JAVA打包工具 JEP343(孵化阶段)
- 3_JFR事件流
- 4_外部存储器API (孵化阶段)
- 5_非易失性映射字节缓冲区
1 概述
Oracle在2020年3月17日宣布JAVA14 全面上市,JAVA14通过每六个个月发布一次新功能,为企业和开发人员社区提供增强功能,继续了Oracle加快创新的承诺.
最新的JAVA开发工具包提供了新功能,其中包括两项备受期待的新预览功能,实例匹配的匹配模式(JEP 305) 和记录(JEP 359),以及文本块的第二个预览(JEP 368),此外,最新的JAVA版本增加了对switch表达式的语言支持,公开了,用于持续监控JDK Flight Recorder数据的新API。
将低延迟的Z垃圾收集器的可用性扩招到了macOS和Windows,并在孵化器模块中添加了包装完备的java应用程序和新的外部内存访问API,以安全高效的访问JAVA对外部的内存。
我们可以在openjdk灌完中观察到JDK14发布的详细官方计划和具体新特性详情,地址如下
https://openjdk.java.net/projects/jdk/14/
JAVA14 一共发行了16个JEP(JDK Enhancement Proposals,JDK 增强提案)

语言特性7项目
- switch表达式(标准)
- 友好的空指针异常
- 非易失性字节缓冲区
- record
- instanceof模式匹配
- 文本块改进 二次预览
- 外部存储API
垃圾回收修改
- G1的NUMA内存分配优化
新增工具
- JAVA打包工具 孵化
- JFR事件流
增加废弃和移除
- MacOS系统上的ZGC试验
- windows系统上的ZGC实验
- 弃用Parallel Scavenge 和Serial Old垃圾收集算法
- 弃用Solaris和SPCRC端口
- 移除CMS垃圾收集器
- 删除Pack200工具和API
2 语法层面的变化
1_instanceof的模式匹配(预览)
Pattern Matching for instanceof (Preview)
以往我们使用instanceof运算符都是先判断,然后在进行强转,例如我们查看String的equals方法源码
public boolean equals(Object anObject) {if (this == anObject) {return true;}// 先进行类型的判断 if (anObject instanceof String) {// 然后进行强转String aString = (String)anObject;if (!COMPACT_STRINGS || this.coder == aString.coder) {return StringLatin1.equals(value, aString.value);}}return false;}
需要先判断类型,然后强转,还要声明一个本地变量,语法比较麻烦.比较理想的状态是,在执行类型检测的时候同时执行类型转换
JEP305 新增了使 instanceof 运算符具有匹配的能力. 模式匹配能够是程序的通用逻辑更加简洁,代码更加简单,同时在做类型判断和类型转换的时候也更加安全.详情如下
JAVA14 提供了新的解决方案: 新的instanceof模式匹配,新的模式匹配语法是: 在instanceof的类型之后添加了变量. 如果对obj的类型检查通过,obj会被转换成后面的变量表示的数据类型. 数据类型的声明仅仅书写一次即可
Object obj ="hello java";if(obj instanceof String str){System.out.println(str);}else{System.out.println("not a String");}
上述语法的判断逻辑时,如果obj是String类型,则会转换为后面的str,如果不是,则执行else,注意,此时的str仅仅是if语句块里的局部变量,在else语句块中不可用
Object obj ="hello java";// 这里做的是取反运算if(!(obj instanceof String str) ){System.out.println("not a String");//System.out.println(str);// 这里不能使用str}else{System.out.println(str);// 这里可以使用str}
但是如果if语句中使用了! 这种取反运算,那么逻辑上就是相反的,这个时候else才是相当于成功转换了,所以在else中可以使用str,if中不可以使用str
Object obj =new Date();// "hello java";if(obj instanceof String str && str.length()>2){System.out.println(str);}else{System.out.println("not a String or length <=2");}
上述语句块中,如果if中的判断逻辑比较复杂,是可以在后续的其他条件中使用str变量进行判断的,但是注意这里的运算符是短路与运算,就是要保证后面在使用str时,已经完成了转换,如果使用短路或运算,无法保证str是可以成功转换的,是不允许的,如下面的代码,就是错的
Object obj =new Date();// "hello java";if(obj instanceof String str || str.length()>2){System.out.println(str);}else{System.out.println("not a String or length <=2");}
总之: if语句块中的小括号内,要保证成功的进行了转换才可以在if语句库中使用转换的对象,否则不可以
通过这个模式匹配,我们可以简化在类中重写的equals方法
import java.util.Objects;
class Person{private String pname;private Integer page;public Person(String pname,Integer page){this.pname =pname;this.page=page;}@Overridepublic boolean equals(Object obj){return obj instanceof Person p && Objects.equals(this.pname,p.pname)&& Objects.equels(this.page,p.page);}
}
2_switch表达式(标准)
java的Switch语句是一个一直在变化的语法,可能是因为之前的不够强大,在JAVA14中,我们依然可以看到对于switch的语法优化.
我们简单整理一下switch语句在各个版本中的特点:
-
JAVA5 switch变量类型可以使用枚举了
-
JAVA7 switch变量类型中可以使用String
-
JAVA11 switch语句可以自动省略break导致的贯穿提示警告 case L ->
-
JAVA12 switch语句可以作为表达式,用变量接收结果,可以省略break
-
JAVA13 switch中可以使用yield关键字停止switch语句块
JAVA14 JEP361switch表达式(标准)是独立的,不依赖于JEP 325 和 JEP 354,也就是说这里开始,之前学习的switch语句的语法成为一个正式的标准.未来是否有更多的改进,我们可以拭目以待。
JDK12对缺省break的贯穿弱点进行了改进,case: 改成 case L -> ,这样即使不写也不会贯穿了,而且可以作为表达式返回结果。
var grade ="a";
var res =switch(grade){case "a" -> "优秀";case "b" -> "良好";case "c" -> "一般";case "d" -> "及格";default -> "no such grade";
}
JAVA12 开始也可以进行多值匹配的支持。
var grade ="a";
var res =switch(grade){case "a","b" -> "优秀";case "c" -> "一般";case "d" -> "及格";default -> "no such grade";
}
JAVA13开始可以使用 yield返回结果,这里的case后面仍然是:
String x = "3";
int i = switch (x) {case "1":yield 1;case "2":{System.out.println("");yield 2;}default:yield 3;
};
System.out.println(i);
3_文本块改进(第二次预览)
Text Blocks(Second Preview)
问题
文本块是在JAVA13中开始了第一次的预览,目标是在字符串中可以更好的表达 HTML XML SQL或者JSON格式的字符串,减少各种的不相关一些空格换行符号,字符串转义和字符串加号的拼接,在JAVA14中,增加了两个escape sequence ,分别是 \ (取消换行操作) 与\s escape sequence(增加空格),文本块进行了第二次预览,进一步调了JAVA程序书写大段字符串文本的可读性和方便性
目标
- 简化跨越多行的字符串,避免对换行等特殊字符进行转义,简化java程序
- 增强java程序中用字符串表示其他语言代码的可读性
- 解析新的转义序列
String textBlock= """<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Title</title></head>\s\<body></body>\s</html>""";System.out.println(textBlock);
4_Records 记录类型(预览 JEP359)
通过Record增强java编程语言,Record提供了一种紧凑的语法来声明类,这些类是浅层不可变数据的透明持有者.
问题分析
我们经常听到这样的抱怨:“JAVA太冗长”,“JAVA规矩多”. 最明显的就是最为简单数据载体的类,为了写一个数据类,开发人员必须编写许多低价值,重复,且容易出错的代码,构造函数,getter setter访问器,equals,hashcode,toString这些东西,尽管IDE可以提供一些插件和手段优化,但是仍然没有改变这些代码依然存在,需要操作的事实
传统的类如下
class Person{private Integer pid;private String pname;private Integer page;@Overridepublic String toString() {return "Person{" +"pid=" + pid +", pname='" + pname + '\'' +", page=" + page +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(pid, person.pid) && Objects.equals(pname, person.pname) && Objects.equals(page, person.page);}@Overridepublic int hashCode() {return Objects.hash(pid, pname, page);}public Integer getPid() {return pid;}public void setPid(Integer pid) {this.pid = pid;}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public Integer getPage() {return page;}public void setPage(Integer page) {this.page = page;}public Person() {}public Person(Integer pid, String pname, Integer page) {this.pid = pid;this.pname = pname;this.page = page;}
}就算是使用IDE的快捷键,这些代码也是臃肿的
Records记录类型语法
Record是java的一种新的类型,同枚举一样,Record也是对类的一种限制,Record放弃了类通常享有的特性:将API和表示解耦。
但是作为回报,record使数据类型变得非常简洁,一般可以帮助我们定义一些简单的用于传递数据的实体类
一个record具有名称和状态描述,状态描述声明了record的组成部分
record Person(String name ,int age){}
因为record在与以上是数据的简单透明持有者,所以record会自动获取很多的标准成员
- 状态声明中的每个成员,都是一个private final的字段,属性设置值则不可修改
- 状态声明中的每个组件的公共读取访问方法,该方法和组件具有相同的名字,get方法和属性名一致
- 一个公共的构造函数,其签名与状态声明相同,构造方法和签名合二为一
- equals和hashcode的实现
- toString的实现
- record提供的默认是一个全参的构造器
测试代码如下
package com.shenyang.test;import java.util.Objects;/*** @Author: shenyang* @Description: JDK14K*/
public class Test2 {public static void main(String[] args) {Person p =new Person(1,"张三",10);Person p2 =new Person(1,"张三",10);System.out.println(p.pname());System.out.println(p);System.out.println(p.hashCode());System.out.println(p2.hashCode());System.out.println(p.equals(p2));}
}
record Person(Integer pid,String pname ,Integer page){};
测试结果如下
张三
Person[pid=1, pname=张三, page=10]
24022530
24022530
trueRecords的一些限制
records类是隐含的final类,并且不是抽象类,records不能拓展任何类,不能被继承,声明的任何其他字段都必须是静态的。
records的API仅仅能由其状态描述定义(通过属性定义)
在record中声明额外的变量类型
也可以显示声明从状态描述自动派生的任何成员,可以在没有正式参数列表的情况下声明构造函数,并且在正常的构造函数主体正常完成是调用隐式初始化,这样就可以在显示构造函数中仅执行其参数的验证逻辑,并且省略字段的初始化。
测试代码如下
package com.shenyang.test;import java.util.Objects;/*** @Author: shenyang* @Description: JDK14K*/
public class Test2 {public static void main(String[] args) {Person p =new Person(1,"张三",10);Person p2 =new Person(1,"张三",10);System.out.println(p.pname());System.out.println(p);System.out.println(p.hashCode());System.out.println(p2.hashCode());System.out.println(p.equals(p2));}
}
record Person(Integer pid,String pname ,Integer page){// 定义额外的变量必须是静态的,不能定义成员变量private static String name;public static void setName(String name){Person.name=name;}// 可以定义其他实例方法public void eat(){System.out.println("eat");}// 可以定义其他静态方法public static void methodA(){System.out.println("methoA");}// 这里是构造函数,默认就是全参的构造函数,和record声明的参数列表是一致的,// 这里可以使用全参构造函数中的所有参数// 在这里会默认执行参数给属性赋值操作,就是在这里默认会有this.pid=pid,this.pname=pname,this.page=pagepublic Person{System.out.println(pid);System.out.println(pname);System.out.println(page);}
};
3 API层面的变化
无
4 关于GC
1_G1的NUMA内存分配优化
NUMA-Aware Memory Allocation for G1
NUMA
NUMA就是非统一内存访问架构(英语:non-uniform memory access,简称NUMA),是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。
在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
如下图所示,Node0中的CPU如果访问Node0中的内存,那就是访问本地内存,如果它访问了Node1中的内存,那就是远程访问,性能较差:
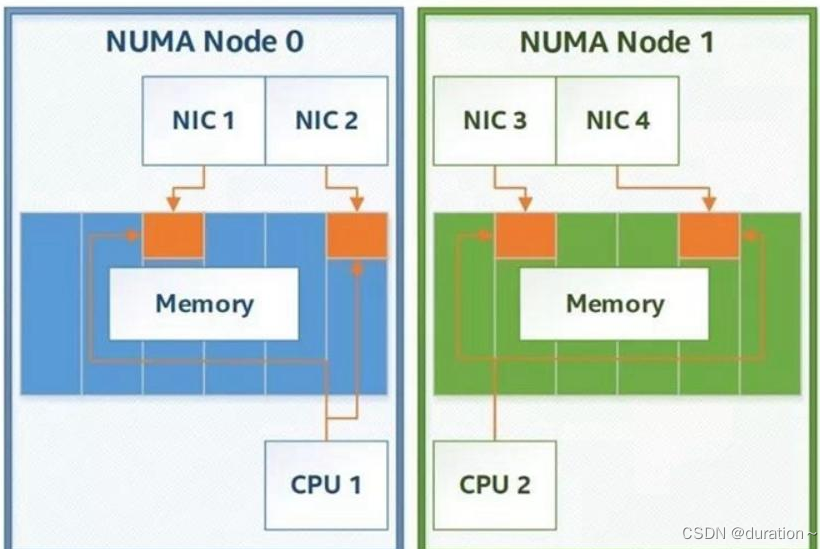
非统一内存访问架构的特点是:
-
被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。
-
所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。
-
另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
目标
JEP345希望通过实现NUMA-aware的内存分配,改进G1在大型机上的性能。
现代的multi-socket服务器越来越多都有NUMA,意思是,内存到每个socket的距离是不相等的,内存到不同的socket之间的访问是有性能差异的,这个距离越长,延迟就会越大,性能就会越差!(https://openjdk.java.net/jeps/345)
G1的堆组织为固定大小区域的集合。一个区域通常是一组物理页面,尽管使用大页面(通过 -XX:+UseLargePages)时,多个区域可能组成一个物理页面。
如果指定了+XX:+UseNUMA选项,则在初始化JVM时,区域将平均分布在可用NUMA节点的总数上。
在开始时固定每个区域的NUMA节点有些不灵活,但是可以通过以下增强来缓解。为了为mutator线程分配新的对象,G1可能需要分配一个新的区域。它将通过从NUMA节点中优先选择一个与当前线程绑定的空闲区域来执行此操作,以便将对象保留在新生代的同一NUMA节点上。如果在为变量分配区域的过程中,同一NUMA节点上没有空闲区域,则G1将触发垃圾回收。要评估的另一种想法是,从距离最近的NUMA节点开始,按距离顺序在其他NUMA节点中搜索自由区域。
该特性不会尝试将对象保留在老年代的同一NUMA节点上。
JEP 345专门用于实现G1垃圾收集器的NUMA支持,仅用于内存管理(内存分配),并且仅在Linux下。对于NUMA体系结构的这种支持是否也适用于其他垃圾回收器或其他部分(例如任务队列窃取),尚不清楚。
2_弃用Serial+CMS,ParNew+Serial Old
由于维护和兼容性测试的成本,在JDK8时将Serial+CMS,ParNew+Serial Old这两个组合声明为废弃(JEP173),并在JDK9中完全取消了这些组合的支持(JEP214)
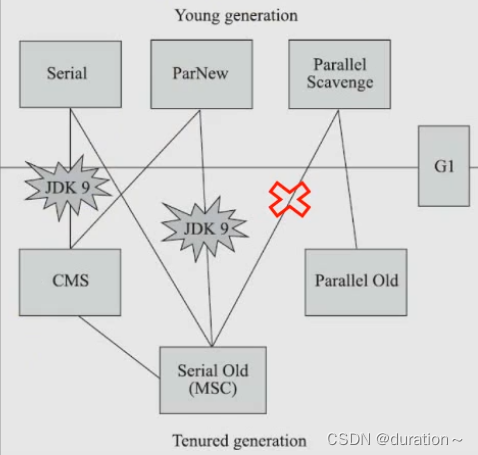
ParallelScavenge+SerialOld GC 的GC组合要被标记为Deprecate了
官方给出的理由
这个GC组合需要大量的代码维护工作,并且,这个GC组合很少被使用.因为它的使用场景应该是一个很大的Young区和一个很小的Old区,这样的话,Old区用SerialOld GC去收集停顿时间才可以勉强被接受
废弃了Parallelyoung generationGC 与SerialOldGC组合 (-XX:+UseParallelGC 与 -XX:-UseParallelOldGC 配合开启),现在使用-XX:+UseParallelGC -XX:-UseParallelOldGC或者使用 -XX:-UseParallelOldGC会出现如下警告

3_删除CMS
删除CMS垃圾回收器
自从G1出现后,CMS在JDK9中就被标记为Deprecate了
CMS弊端
- 会产生内存碎片,导致并发清除后,用户线程可用空间不足(标记清除算法产生,需要整理算法解决)
- 既然强调了并发(Concurrent) CMS收集器对于CPU资源非常敏感,导致吞吐量降低
- CMS收集器无法处理浮动垃圾(用户线程和垃圾回收线程并发执行,回收时用户线程产生新的垃圾)
当CMS停止工作时,会把 Serial Old GC作为备选方案,而它是JVM中性能最差的垃圾收集方式,停顿几秒甚至十秒都有可能
移除了CMS垃圾收集器,如果继续在JDK14中使用-XX:+UseConcMarkSweepGC 不会报错,仅仅给出一个warning警告
warning: Ignoring option UseConcMarkSweepGC; support was removed in 14.0
其他垃圾收集器
G1回收器hotSpot已经默认使用有几年了,我们还看到两个新的GC JAVA11中的ZGC和openJDK12中的Shenandoah,后两者主要特点是:低停顿时间
Shenandoah非Oracle官方发布的,是OpenJDK于JAVA12发布的
| 收集器名称 | 运行时间 | 总停顿时间 | 最大停顿时间 | 平均停顿时间 |
|---|---|---|---|---|
| Shenandoah | 387.602s | 320ms | 89.79ms | 53.01ms |
| G1 | 312.052s | 11.7s | 1.24s | 450.12ms |
| CMS | 286.264s | 12.78s | 4.39s | 852.26ms |
| ParallelScavenge | 260.092s | 6.59s | 3.04s | 823.75ms |
4_ZGC on macOS and Windows
JAVA14之前,ZGC仅仅支持Linux
基于一些开发部署和测试的需要,ZGC在JDK14中支持在macOS 和windows,因此许多桌面级应用可以从ZGC中受益,目前还是一个实验性版本,要想在macOS 和windows上使用
ZGC与Shenandoah目标非常相似,都是在尽量减少吞吐量的情况下,实现对任意堆大小(TB级)都可以把垃圾收集器停顿时间限制在10毫秒以内的低延迟时间
ZGC 收集器是一款基于Region内存布局的,暂时不设分代的,使用了读屏障,染色指针和内存多重映射等技术来实现并发的标记压缩算法,以低延迟为首要目标的一款垃圾收集器.现在想在macOS 和windows上使用ZGC, 方式如下
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
关于ZGC的一些测试数据
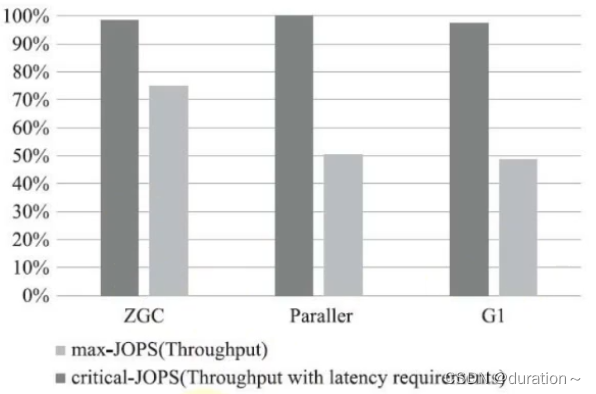
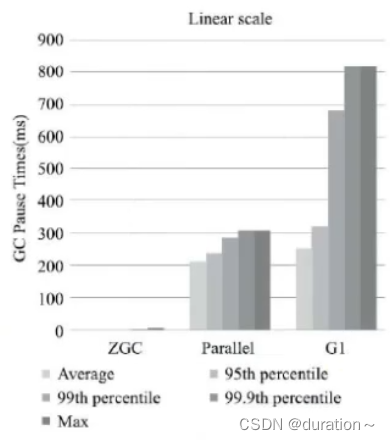
ZGC目前还处于一个实验状态,但是性能非常亮眼,未来将在服务端,大内存,低延迟应用上作为首选的垃圾收集器
4 其他变化
1_友好的空指针异常提示
NullpointerException是java开发中经常遇见的问题,在JDK14之前的版本中,空指针异常的提示信息就是简答的null,并不会告诉我们更加有用的信息,知识根据异常产生的日志来进行查找和处理,对于很长的引用来说,很难定位到具体是哪个对象为null.
演示适用情况
public class Test2 {public static void main(String[] args) {Person p =new Person();p.cat.eat();}
}class Person{public Cat cat;
}
class Cat {public void eat(){}
}
上面的代码在调用eat方法时就会出现空指针异常

这种提示其实并不是很详细,我们可以在运行代码的时候,加上一段配置,用以展示比较友好的控制成提示信息
-XX:+ShowCodeDetailsInExceptionMessages
输出的信息如下所示

其他适用情况
但是对于更复杂的代码,不适用调用器就无法确定是哪个变量为空
a.b.c.d=100;
仅仅使用文件名和行数,并不能精确的提示到底是哪个变量为null
访问多维数组也会发生类似的情况
a[j][j][k]=99;
这里如果发生npe文件名和行号也是无法精确指出到底是哪一层的数组出现了空指针
再例如
a.i=b.j;
这里出现了npe 如果仅凭文件名和行号,无法确定到底是a的问题还是b的问题
NPE也可能在方法调用中传递
x().y().i=99;
这里如果出现了NPE,那么仅凭行号和文件名也是无法确定到底是x方法还是y方法的问题
接下来简单演示一个代码
/*** @Author: shenyang* @Description: JDK14K*/
public class Test2 {public static void main(String[] args) {A a =new A();B b=null;a.i=b.j;}
}class A{int i;
}
class B{int j;
}
如果没有友好提示

如果有友好提示

这时就可以发现,是j的问题,那么其实就是b对象的问题
2_JAVA打包工具 JEP343(孵化阶段)
该特征旨在创建一个用于打包独立java应用程序的工具.JAVA应用的打包和分发一直都是个老大的难题. 用户希望JAVA引用的安装和运行方式和其他应用有相似的体验. 比如,在windows上只需要双击文件就可以运行. JAVA平台本身没有提供实用的工具解决这个问题. 通常都依赖第三方的工具完成,这个JEP的目标就是创建一个简单的JAVa打包工具jpackage. 相对于第三方工具,jpackage只适用于比较简单的场景,不过对很多应用来说已经足够好了.
该jpackage工具将java的应用程序打包到特定的平台的程序包中,该程序包包含所必须的依赖. 该应用程序可以作为普通的jar文件或者模块的集合提供,受支持的特定平台的软件包格式为:
1 Linux deb或者 rpm
2 maxOS: pkg和dmg
3 windows L msi和exe
默认情况下,jpackage以最适合其运行系统的格式生成软件包
项目打包-非模块化项目
如果有一个包含jar文件的应用程序,所有的应用程序都位于一个名为lib 的目录总,并且lib/main.jar包含主类,可以通过如下命令打包
$ jpackage --name myapp -- input lib --main-jar main.jar
将以本地系统的默认格式打包应用程序,将生成的打包文件保留到当前目录中. 如果MANIFEST.MF文件中没有main.jar.没有Main-Class属性,则必须显式指定主类
$ jpackage --name myapp --input lib --main-jar main.jar \ --main-class myapp.Main
软件包的名称将为没有app ,尽管软件包文件本身的名称将更长,并以软件包类型皆为,该软件包将包括该应用程序的启动器,也称为myapp .要启动应用程序,启动程序将会从输入目录复制的每个jar文件放在jvm的类路径上
如果您希望默认格式以外的其他格式制作软件包,请使用 --type选项. 例如,要在macOS 上生成pkg文件而不是dmg文件
$ jpackage --name myapp --input lib --main-jar main.jar --type pkg
项目打包-模块化项目
如果您有一个模块化应用程序,该程序有目录中的模块化jar文件或JMOD文件组成,并且模块中lib包含主类myAPP,则命令为
$ jpackage -name myapp --moudule-path lib -m myapp
如果myAPP模块未标识主类,则必须再次明确
$ jpackage -name myapp --moudule-path lib -m myapp/myapp.Main
3_JFR事件流
简介
Java Flight Recorder(JFR)是JVM的诊断和性能分析工具。
JAVA14之前只能做离线的分析,现在可以做实时的持续监视
它可以收集有关JVM以及在其上运行的Java应用程序的数据。JFR是集成到JVM中的,所以JFR对JVM的性能影响非常小,我们可以放心的使用它。
一般来说,在使用默认配置的时候,性能影响要小于1%。
JFR的历史很久远了。早在Oracle2008年收购BEA的时候就有了。JFR一般和JMC(Java Mission Control)协同工作。
JFR是一个基于事件的低开销的分析引擎,具有高性能的后端,可以以二进制格式编写事件,而JMC是一个GUI工具,用于检查JFR创建的数据文件。
这些工具最早是在BEA的JRockit JVM中出现的,最后被移植到了Oracle JDK。最开始JFR是商用版本,但是在JDK11的时候,JFR和JMC完全开源了,这意味着我们在非商用的情况下也可以使用了。
而在今天的JDK 14中,引入了一个新的JFR特性叫做JFR Event Streaming,我们将在本文中简要介绍。
先介绍一下JFR和JMC。
JFR
上面我们简单的介绍了一下JFR。JFR是JVM的调优工具,通过不停的收集JVM和java应用程序中的各种事件,从而为后续的JMC分析提供数据。
Event是由三部分组成的:时间戳,事件名和数据。同时JFR也会处理三种类型的Event:持续一段时间的Event,立刻触发的Event和抽样的Event。
为了保证性能的最新影响,在使用JFR的时候,请选择你需要的事件类型。
JFR从JVM中搜集到Event之后,会将其写入一个小的thread-local缓存中,然后刷新到一个全局的内存缓存中,最后将缓存中的数据写到磁盘中去。
或者你可以配置JFR不写到磁盘中去,但是这样缓存中只会保存部分events的信息。这也是为什么会有JDK14 JEP 349的原因。
开启JFR有很多种方式,这里我们关注下面两种:
- 添加命令行参数
-XX:StartFlightRecording:<options>
启动命令行参数的格式如上所述。
JFR可以获取超过一百种不同类型的元数据。如果要我们一个个来指定这些元数据,将会是一个非常大的功能。所以JDK已经为我们提供了两个默认的profile:default.jfc and profile.jfc。
其中 default.jfc 是默认的记录等级,对JVM性能影响不大,适合普通的,大部分应用程序。而profile.jfc包含了更多的细节,对性能影响会更多一些。
如果你不想使用默认的两个jfc文件,也可以按照你自己的需要来创建。
下面看一个更加完整的命令行参数:
-XX:StartFlightRecording:disk=true,filename=/tmp/customer.jfr,maxage=5h,settings=profile
上面的命令会创建一个最大age是5h的profile信息文件。
- 使用jcmd
命令行添加参数还是太麻烦了,如果我们想动态添加JFR,则可以使用jcmd命令。
jcmd <pid> JFR.start name=custProfile settings=default
jcmd <pid> JFR.dump filename=custProfile.jfr
jcmd <pid> JFR.stop
上面的命令在一个运行中的JVM中启动了JFR,并将统计结果dump到了文件中。
上面的custProfile.jfr是一个二进制文件,为了对其进行分析,我们需要和JFR配套的工具JMC。
JMC
JDK Mission Control 是一个用于对 Java 应用程序进行管理、监视、概要分析和故障排除的工具套件。
在JDK14中,JMC是独立于JDK单独发行的。我们可以下载之后进行安装。
我们先启动一个程序,用于做JFR的测试。
@Slf4j
public class ThreadTest {public static void main(String[] args) {ExecutorService executorService= Executors.newFixedThreadPool(10);Runnable runnable= ()->{while(true){log.info(Thread.currentThread().getName());try {Thread.sleep(500);} catch (InterruptedException e) {log.error(e.getMessage(),e);}}};for(int i=0; i<10; i++){executorService.submit(runnable);}}
}
很简单的一个程序,启动了10个线程,我们启动这个程序。
然后再去看看JMC的界面:
JMC非常强大,也有很多功能,具体的细节大家可以自己运行去体会。
JFR事件
JMC好用是好用,但是要一个一个的去监听JFR文件会很繁琐。接下来我们来介绍一下怎么采用写代码的方式来监听JFR事件。
如果我们想通过程序来获取“Class Loading Statistics"的信息,可以这样做。
上图的右侧是具体的信息,我们可以看到主要包含三个字段:开始时间,Loaded Class Count和 Unloaded Class Count。
我们的思路就是使用jdk.jfr.consumer.RecordingFile去读取生成的JFR文件,然后对文件中的数据进行解析。
相应代码如下:
@Slf4j
public class JFREvent {private static Predicate<RecordedEvent> testMaker(String s) {return e -> e.getEventType().getName().startsWith(s);}private static final Map<Predicate<RecordedEvent>,Function<RecordedEvent, Map<String, String>>> mappers =Map.of(testMaker("jdk.ClassLoadingStatistics"),ev -> Map.of("start", ""+ ev.getStartTime(),"Loaded Class Count",""+ ev.getLong("loadedClassCount"),"Unloaded Class Count", ""+ ev.getLong("unloadedClassCount")));@Testpublic void readJFRFile() throws IOException {RecordingFile recordingFile = new RecordingFile(Paths.get("/Users/flydean/flight_recording_1401comflydeaneventstreamThreadTest.jfr"));while (recordingFile.hasMoreEvents()) {var event = recordingFile.readEvent();if (event != null) {var details = convertEvent(event);if (details == null) {// details为空} else {// 打印目标log.info("{}",details);}}}}public Map<String, String> convertEvent(final RecordedEvent e) {for (var ent : mappers.entrySet()) {if (ent.getKey().test(e)) {return ent.getValue().apply(e);}}return null;}
}
注意,在convertEvent方法中,我们将从文件中读取的Event转换成了map对象。
在构建map时,我们先判断Event的名字是不是我们所需要的jdk.ClassLoadingStatistics,然后将Event中其他的字段进行转换。最后输出。
运行结果:
{start=2021-04-29T02:18:41.770618136Z, Loaded Class Count=2861, Unloaded Class Count=0}
...
可以看到输出结果和界面上面是一样的。
JFR事件流
讲了这么多,终于到我们今天要讲的内容了:JFR事件流。
上面的JFR事件中,我们需要去读取JFR文件,进行分析。但是文件是死的,人是活的,每次分析都需要先生成JFR文件简直是太复杂了。是个程序员都不能容忍。
在JFR事件流中,我们可以监听Event的变化,从而在程序中进行相应的处理。这样不需要生成JFR文件也可以监听事件变化。
public static void main(String[] args) throws IOException, ParseException {//default or profile 两个默认的profiling configuration filesConfiguration config = Configuration.getConfiguration("default");try (var es = new RecordingStream(config)) {es.onEvent("jdk.GarbageCollection", System.out::println);es.onEvent("jdk.CPULoad", System.out::println);es.onEvent("jdk.JVMInformation", System.out::println);es.setMaxAge(Duration.ofSeconds(10));es.start();}}
看看上面的例子。我们通过Configuration.getConfiguration(“default”)获取到了默认的default配置。
然后通过构建了default的RecordingStream。通过onEvent方法,我们对相应的Event进行处理。
4_外部存储器API (孵化阶段)
通过一个API,以允许java程序安全有效的访问JAVA堆之外的外部存储(堆以外的外部存储空间)
目的:JEP 370旨在实现一种提供“通用性”,“安全性”和“确定性”的“外部存储器API”JEP还指出,此外部内存API旨在替代当前使用的方法( java.nio.ByteBuffer和sun.misc.Unsafe )。
许多java的库都能访问外部存储,例如 ignite ,mapDB , memcached以及netty的ByteBuffer API ,这样可以:
- 避免垃圾回收相关成本和不可预测性
- 跨多个进程共享内存
- 通过将文件映射到内存中来序列化和反序列化内容
但是JAVAAPI本身没有提供一个令人满意的访问外部内存的解决方案
当java程序需要访问堆内存之外的外部存储是,通常有两种方式
-
java.nio.ByteBuffer ,:ByteBuffer 允许使用allcateDirect() 方法在堆内存之外分配内存空间
-
sum.misc.Unsafe : Unsafe 中的方法可以直接对内存地址进行操作
ByteBuffer有自己的限制. 首先是ByteBuffer的大小不能超过2G,其次是内存的释放依靠垃圾回收器,Unsafe的API在使用是不安全的,风险很高,可能会造成JVM崩溃.另外Unsafe本身是不被支持的API,并不推荐
JEP 370的“描述”部分引入了安全高效的API来访问外部外部内存地址,目前该API还是属于孵化阶段,相关API在jdk.incubator.foreign模块的jdk.incubator.foreign包中, 三个API分别是: MemorySegment , MemoryAddress和MemoryLayout 。 MemorySegment用于对具有给定空间和时间范围的连续内存区域进行建模。 可以将MemoryAddress视为段内的偏移量。 最后, MemoryLayout是内存段内容的程序化描述。
5_非易失性映射字节缓冲区
JAVA14增加了一种文件映射模式,用于访问非易失性内存,非易失性内存能够持久保持数据,因此可以利用该特性来改进性能
JEP352 可以使用FileChannelAPI创建引用非易失性内存,(non-volatile memory) 的MappedByteBuffer实例,该JEP建议升级MappedByteBuffer以支持对非易失性存储器的访问,唯一需要的API更改是FileChannel客户端,以请求映射位于NVM的支持的文件系统,而不是常规的文件存储系统上的文件,对MappedByteBuffer API最新的更改意味着他支持允许直接内存更新所需要的所有行为,并提供更高级别的JAVA客户端库所需要的持久性保证,以实现持久性的数据类型
目标
NVM为引用程序程序员提供了在程序运行过程中创建和更新程序转台的机会,而减少了输出到持久性介质或者从持久性介质输入是的成本. 对于事务程序特别重要,在事务程序中,需要定期保持不确定状态以启用崩溃恢复.
现有的C库(例如Intel的libpmen),为c程序员提供了对集成NVM的高效访问,它们还一次基础来支持对各种持久性数据类型的简单管理.当前,由于频繁需要进行系统调用或者JNI来调用原始操作,从而确保内存更改是持久的,因此即使禁用JAVA的基础类库也很昂贵.同样的问题限制了高级库的使用.并且,由于C中提供的持久数据类型分配在无法从JAVA直接访问的内存中这一事实而加剧了这一问题.
该特性试图通过允许映射到ByteBuffer的NVM的有效写回来解决第一个问题. 由于java可以直接访问ByteBuffer映射内存,因此可以通过实现与C语言中提供的客户端库等效的客户端库来解决第二个问题,以管理不同持久数据类型存储.
初步变更
该JEP使用了JAVASE API的两个增强功能
- 支持 Implementation-defined的映射模式
- MappedByteBuffer::force方法指定范围
特定于JDK的API更改
- 通过新模块中的公共API公开新的MApMode枚举值
一个公共扩展枚举ExtendedMapMode将添加到jdk.nio.mapmode程序包
package jdk.nio.mapmode;
public class ExtendedMapMode{private ExtendedMapMode(){}public static final MapMode READ_ONLY_SYNC= ... ...}
在调用FileChannel::map方法创建映射到NVM设备文件上的只读或者写MappedByteBuffer时,可以使用上述的枚举值,如果这些标志在不支持NVM设备文件平台上传递,程序会抛出UnsupportedOperationException异常,在受支持的平台上,及当目标FileChannel实例是通过NVM设备打开的派生文件是,才能传递这些参数,在任何情况下,都会抛出IOException;
这篇关于JDK14特性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






