本文主要是介绍使用SpringDataJPA简化DAO层的开发(只要实现了JPA规范的ORM框架都能支持,方便替换ORM框架),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
JPA接口规范:
JPA,JAVA Persistance API——JAVA持久化规范
实体Bean(Entity bean)使用了这个规范后,各JavaEE应用服务器就可以根据这套规范选择具体的ORM框架对数据库进行操作,JPA规范是hibernate框架的作者提出来的,因此Hibernate作为Jboss服务器中JPA的默认实现,Oracle的Weblogic使用EclipseLink(以前叫TopLink)作为默认的JPA实现,IBM的Websphere和Sun的Glassfish默认使用OpenJPA(Apache的一个开源项目)作为其默认的JPA实现。
JPA的底层实现是一些流行的开源ORM(对象关系映射)框架,因此JPA其实也就是java实体对象和关系型数据库建立起映射关系,通过面向对象编程的思想操作关系型数据库的规范。
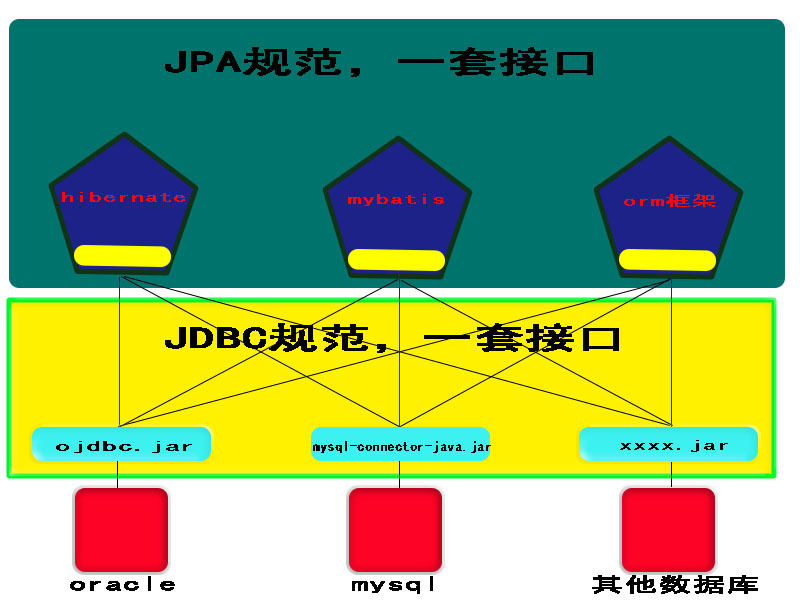
就如JDBC一样,数据库厂商只要依据JDBC这套接口开发出自己的数据库驱动就能让其他优秀的ORM框架去操作数据库了,而不需要区分使用哪种ORM框架和哪种数据库,因为这些ORM框架也同样遵循JDBC这套规范操作驱动。JPA也是一套接口规范,只要是实现了JPA接口规范的ORM框架都能被同样遵循JPA接口规范的Service层去调用,而不用关心用什么ORM框架去做具体的实现。
Spring Data JPA: Spring提供的一个用于简化JPA开发的框架
-Spring Data JPA不需要过多的关心Dao层的实现,只需关注我们继承的接口,按照一定的规则去编写我们的接口即可,spring会按照API规范动态生成我们接口的实现类进行注入,并且实现类里包含了一些常规操作的方法实现。
-优点:如果使用JPA提供的接口来操作ORM框架,可以不写任何实现就能对数据库进行CRUD操作,还可以进行简单的分页,排序操作。
-缺点:不能实现过于复杂的查询
我们来看一下Spring对JPA实现的核心的API:
--Repository: 所有接口的父接口,而且是一个空接口,目的是为了统一所有Repository的类型,让组件扫描的时候能进行识。
--CrudRepository:是Repository的子接口,提供CRUD的功能。
--PagingAndSortingRepository:是CrudRepository的子接口,添加分页和排序的功能。
--JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,例如批量操作。
--JpaSpecificationExecutor:用来做负责查询的接口。
--Specification:是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可。
实现了JPA接口规范的ORM框架有很多,这里介绍一下Hibernate作为SpringDataJPA的具体ORM框架实现的开发
Hibernate结合SpringdataJPA详细Demo:参见--https://github.com/dlyanghao/SpringDataJPAFrameUse
这篇关于使用SpringDataJPA简化DAO层的开发(只要实现了JPA规范的ORM框架都能支持,方便替换ORM框架)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





