本文主要是介绍UNet++学习/实现笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原理:
UNet++解读 + 它是如何对UNet改进 + 作者的研究态度和方式 - 知乎 (zhihu.com)
实现方法有两种:
①跳跃连接改为直接连接
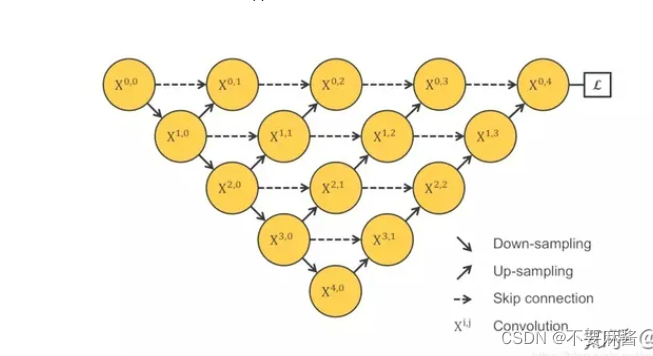
②深度监督方式对于每个子网络输出端加一个1x1的卷积核,相当于监督了每个子网络
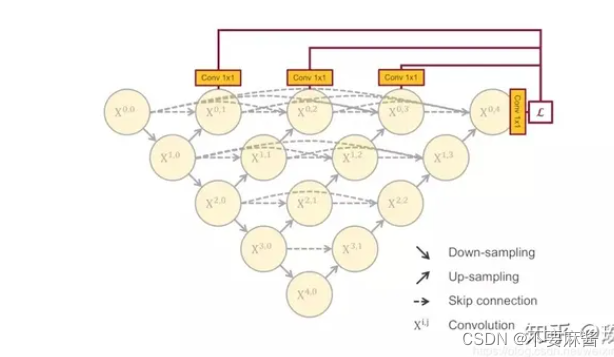
Keras实现
语义分割(三)Unet++_unet++网络结构-CSDN博客
拿L2子网络作为例子解释一下结构:
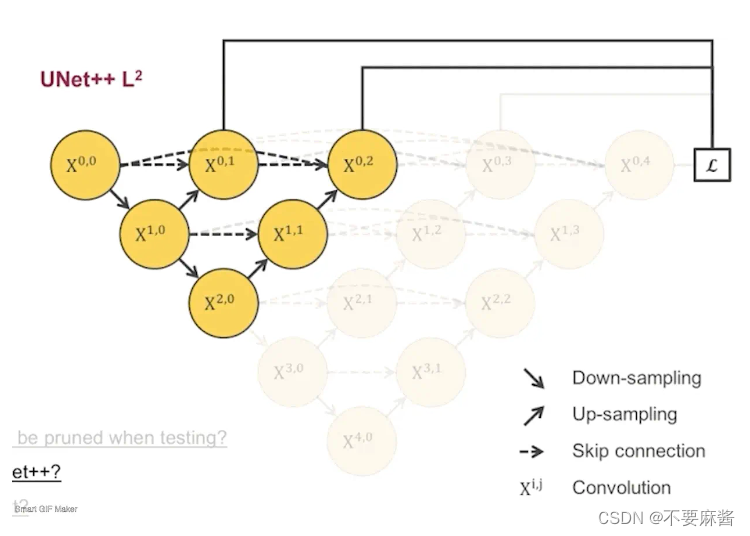
## l2pool10_20 = MaxPool2D(pool_size=(2, 2))(conv1_0)conv2_0 = conv_drop(inputs=pool10_20, filters=filters[2])up20_11 = upsampling(inputs=conv2_0, filters=filters[1])concat2_1 = concatenate([up20_11, conv1_0], axis=3)conv1_1 = conv_drop(inputs=concat2_1, filters=filters[1])up11_02 = upsampling(inputs=conv1_1, filters=filters[0])concat2_2 = concatenate([up11_02, conv0_0, conv0_1], axis=3)conv0_2 = conv_drop(inputs=concat2_2, filters=filters[0])pool10_20 为从 x1,0 到 x2,0 的池化结果, 再对池化结果进行卷积得到 x2, 0的卷积结果 conv2_0
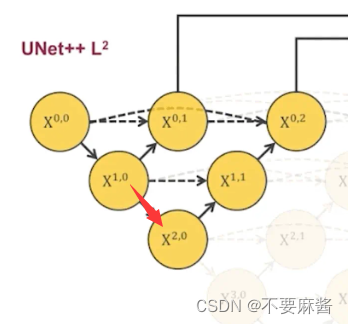
将 x2,0 的卷积结果 上采样得到 x2,0 到 x1,1 的上采样结果 up20_11,并连接 conv1_0 ,再对连接后的结果进行一次卷积得到conv1_1的结果
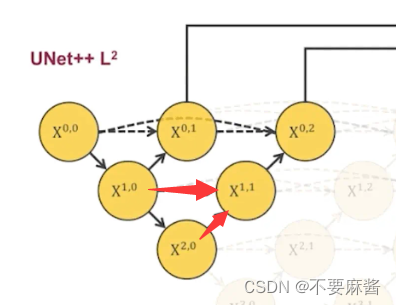
同理可得conv0_2的结果
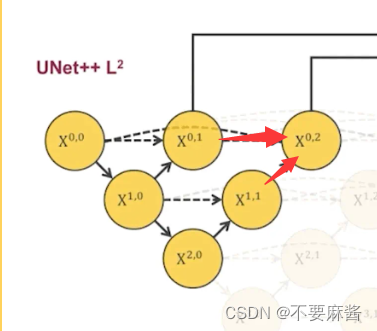
总结起来是:
每一步下采样为先池化后卷积。
每一步上采样为 左下角结构的反卷积 连接 正左所有结构的卷积,将连接结果再做一次卷积。
总代码:
###########################
# Unet++ loss #
###########################
from keras import *
from keras.src.layers import Conv2D, UpSampling2D, concatenate, Reshape, Activation
from keras.src.losses import binary_crossentropy
from keras.src.optimizers import Adam
from tensorflow.python.keras.layers import MaxPool2D############################
# Dice系数,用于评估图像分割任务中预测结果和真实标签之间的相似度指标
############################
def dice_coef(y_true, y_pred):smooth = 1. # 平滑项,避免分母为零y_true_f = K.flatten(y_true)y_pred_f = K.flatten(y_pred)intersection = K.sum(y_true_f * y_pred_f) # 表示预测结果和真实标签的交集(即正确预测的正样本)return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)# 二进制交叉熵损失和Dice系数之间的线性组合
def bce_dice_loss(y_true, y_pred):return 0.5 * binary_crossentropy(y_true, y_pred) - dice_coef(y_true, y_pred)# return 0.5 * categorical_crossentropy(y_true, y_pred) - dice_coef(y_true, y_pred)#############################
# Unet++ conv and upsampling #
#############################
# 下采样:两个3x3卷积
def conv_drop(inputs, filters):conv1 = Conv2D(filters=filters, kernel_size=3, padding='same', activation='relu',kernel_initializer='he_normal')(inputs)# drop1 = Dropout(rate=0.5)(conv1)conv2 = Conv2D(filters=filters, kernel_size=3, padding='same', activation='relu',kernel_initializer='he_normal')(conv1)# drop2 = Dropout(rate=0.5)(conv2)return conv2# 上采样:进行2倍上采样,然后进行一个2x2的卷积
def upsampling(inputs, filters):up = UpSampling2D(size=(2, 2))(inputs)conv = Conv2D(filters=filters, kernel_size=2, activation='relu', padding='same',kernel_initializer='he_normal')(up)return conv###############################
# Unet++ #
###############################
def Unet_plusplus(input_size=(224, 224, 1), n_class=2, filters=(32, 64, 128, 256, 512), re_shape=False):inputs = Input(shape=input_size)## l1conv0_0 = conv_drop(inputs=inputs, filters=filters[0])pool00_10 = MaxPool2D(pool_size=(2, 2))(conv0_0)conv1_0 = conv_drop(inputs=pool00_10, filters=filters[1])up10_01 = upsampling(inputs=conv1_0, filters=filters[0])concat1_1 = concatenate([up10_01, conv0_0], axis=3)conv0_1 = conv_drop(inputs=concat1_1, filters=filters[0])## l2pool10_20 = MaxPool2D(pool_size=(2, 2))(conv1_0)conv2_0 = conv_drop(inputs=pool10_20, filters=filters[2])up20_11 = upsampling(inputs=conv2_0, filters=filters[1])concat2_1 = concatenate([up20_11, conv1_0], axis=3)conv1_1 = conv_drop(inputs=concat2_1, filters=filters[1])up11_02 = upsampling(inputs=conv1_1, filters=filters[0])concat2_2 = concatenate([up11_02, conv0_0, conv0_1], axis=3)conv0_2 = conv_drop(inputs=concat2_2, filters=filters[0])##l3pool20_30 = MaxPool2D(pool_size=(2, 2))(conv2_0)conv3_0 = conv_drop(inputs=pool20_30, filters=filters[3])up30_21 = upsampling(inputs=conv3_0, filters=filters[2])concat3_1 = concatenate([up30_21, conv2_0], axis=3)conv2_1 = conv_drop(inputs=concat3_1, filters=filters[2])up21_12 = upsampling(inputs=conv2_1, filters=filters[1])concat3_2 = concatenate([up21_12, conv1_0, conv1_1], axis=3)conv1_2 = conv_drop(inputs=concat3_2, filters=filters[1])up12_03 = upsampling(inputs=conv1_2, filters=filters[0])concat3_3 = concatenate([up12_03, conv0_0, conv0_1, conv0_2], axis=3)conv0_3 = conv_drop(inputs=concat3_3, filters=filters[0])## l4pool30_40 = MaxPool2D(pool_size=(2, 2))(conv3_0)conv4_0 = conv_drop(inputs=pool30_40, filters=filters[4])up40_31 = upsampling(inputs=conv4_0, filters=filters[3])concat4_1 = concatenate([up40_31, conv3_0], axis=3)conv3_1 = conv_drop(inputs=concat4_1, filters=filters[3])up31_22 = upsampling(inputs=conv3_1, filters=filters[2])concat4_2 = concatenate([up31_22, conv2_0, conv2_1], axis=3)conv2_2 = conv_drop(inputs=concat4_2, filters=filters[2])up22_13 = upsampling(inputs=conv2_2, filters=filters[1])concat4_3 = concatenate([up22_13, conv1_0, conv1_1, conv1_2], axis=3)conv1_3 = conv_drop(inputs=concat4_3, filters=filters[1])up13_04 = upsampling(inputs=conv1_3, filters=filters[0])concat4_4 = concatenate([up13_04, conv0_0, conv0_1, conv0_2, conv0_3], axis=3)conv0_4 = conv_drop(inputs=concat4_4, filters=filters[0])## outputl1_conv_out = Conv2D(filters=n_class, kernel_size=1, padding='same', kernel_initializer='he_normal')(conv0_1)l2_conv_out = Conv2D(filters=n_class, kernel_size=1, padding='same', kernel_initializer='he_normal')(conv0_2)l3_conv_out = Conv2D(filters=n_class, kernel_size=1, padding='same', kernel_initializer='he_normal')(conv0_3)l4_conv_out = Conv2D(filters=n_class, kernel_size=1, padding='same', kernel_initializer='he_normal')(conv0_4)if re_shape == True:l1_conv_out = Reshape((input_size[0] * input_size[1], n_class))(l1_conv_out)l2_conv_out = Reshape((input_size[0] * input_size[1], n_class))(l2_conv_out)l3_conv_out = Reshape((input_size[0] * input_size[1], n_class))(l3_conv_out)l4_conv_out = Reshape((input_size[0] * input_size[1], n_class))(l4_conv_out)l1_out = Activation('sigmoid', name='l1_out')(l1_conv_out)l2_out = Activation('sigmoid', name='l2_out')(l2_conv_out)l3_out = Activation('sigmoid', name='l3_out')(l3_conv_out)l4_out = Activation('sigmoid', name='l4_out')(l4_conv_out)model = Model(input=inputs, output=[l1_out, l2_out, l3_out, l4_out])# model = Model(input=inputs, output=l4_out)model.summary()losses = {'l1_out': bce_dice_loss,'l2_out': bce_dice_loss,'l3_out': bce_dice_loss,'l4_out': bce_dice_loss,}model.compile(optimizer=Adam(lr=1e-4), loss=losses, metrics=['accuracy'])return model
pytorch实现
语义分割系列6-Unet++(pytorch实现)-CSDN博客
import torch
import torch.nn as nnclass ContinusParalleConv(nn.Module):# 一个连续的卷积模块,包含BatchNorm 在前 和 在后 两种模式def __init__(self, in_channels, out_channels, pre_Batch_Norm=True):super(ContinusParalleConv, self).__init__()self.in_channels = in_channelsself.out_channels = out_channelsif pre_Batch_Norm:self.Conv_forward = nn.Sequential(nn.BatchNorm2d(self.in_channels),nn.ReLU(),nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1))else:self.Conv_forward = nn.Sequential(nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1),nn.BatchNorm2d(self.out_channels),nn.ReLU())def forward(self, x):x = self.Conv_forward(x)return xclass UnetPlusPlus(nn.Module):def __init__(self, num_classes, deep_supervision=False):super(UnetPlusPlus, self).__init__()self.num_classes = num_classesself.deep_supervision = deep_supervisionself.filters = [64, 128, 256, 512, 1024]self.CONV3_1 = ContinusParalleConv(512 * 2, 512, pre_Batch_Norm=True)self.CONV2_2 = ContinusParalleConv(256 * 3, 256, pre_Batch_Norm=True)self.CONV2_1 = ContinusParalleConv(256 * 2, 256, pre_Batch_Norm=True)self.CONV1_1 = ContinusParalleConv(128 * 2, 128, pre_Batch_Norm=True)self.CONV1_2 = ContinusParalleConv(128 * 3, 128, pre_Batch_Norm=True)self.CONV1_3 = ContinusParalleConv(128 * 4, 128, pre_Batch_Norm=True)self.CONV0_1 = ContinusParalleConv(64 * 2, 64, pre_Batch_Norm=True)self.CONV0_2 = ContinusParalleConv(64 * 3, 64, pre_Batch_Norm=True)self.CONV0_3 = ContinusParalleConv(64 * 4, 64, pre_Batch_Norm=True)self.CONV0_4 = ContinusParalleConv(64 * 5, 64, pre_Batch_Norm=True)self.stage_0 = ContinusParalleConv(3, 64, pre_Batch_Norm=False)self.stage_1 = ContinusParalleConv(64, 128, pre_Batch_Norm=False)self.stage_2 = ContinusParalleConv(128, 256, pre_Batch_Norm=False)self.stage_3 = ContinusParalleConv(256, 512, pre_Batch_Norm=False)self.stage_4 = ContinusParalleConv(512, 1024, pre_Batch_Norm=False)self.pool = nn.MaxPool2d(2)self.upsample_3_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=4, stride=2, padding=1)self.upsample_2_1 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)self.upsample_2_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)self.upsample_1_1 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)self.upsample_1_2 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)self.upsample_1_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)self.upsample_0_1 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)self.upsample_0_2 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)self.upsample_0_3 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)self.upsample_0_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)# 分割头self.final_super_0_1 = nn.Sequential(nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, self.num_classes, 3, padding=1),)self.final_super_0_2 = nn.Sequential(nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, self.num_classes, 3, padding=1),)self.final_super_0_3 = nn.Sequential(nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, self.num_classes, 3, padding=1),)self.final_super_0_4 = nn.Sequential(nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, self.num_classes, 3, padding=1),)def forward(self, x):x_0_0 = self.stage_0(x)x_1_0 = self.stage_1(self.pool(x_0_0))x_2_0 = self.stage_2(self.pool(x_1_0))x_3_0 = self.stage_3(self.pool(x_2_0))x_4_0 = self.stage_4(self.pool(x_3_0))x_0_1 = torch.cat([self.upsample_0_1(x_1_0), x_0_0], 1)x_0_1 = self.CONV0_1(x_0_1)x_1_1 = torch.cat([self.upsample_1_1(x_2_0), x_1_0], 1)x_1_1 = self.CONV1_1(x_1_1)x_2_1 = torch.cat([self.upsample_2_1(x_3_0), x_2_0], 1)x_2_1 = self.CONV2_1(x_2_1)x_3_1 = torch.cat([self.upsample_3_1(x_4_0), x_3_0], 1)x_3_1 = self.CONV3_1(x_3_1)x_2_2 = torch.cat([self.upsample_2_2(x_3_1), x_2_0, x_2_1], 1)x_2_2 = self.CONV2_2(x_2_2)x_1_2 = torch.cat([self.upsample_1_2(x_2_1), x_1_0, x_1_1], 1)x_1_2 = self.CONV1_2(x_1_2)x_1_3 = torch.cat([self.upsample_1_3(x_2_2), x_1_0, x_1_1, x_1_2], 1)x_1_3 = self.CONV1_3(x_1_3)x_0_2 = torch.cat([self.upsample_0_2(x_1_1), x_0_0, x_0_1], 1)x_0_2 = self.CONV0_2(x_0_2)x_0_3 = torch.cat([self.upsample_0_3(x_1_2), x_0_0, x_0_1, x_0_2], 1)x_0_3 = self.CONV0_3(x_0_3)x_0_4 = torch.cat([self.upsample_0_4(x_1_3), x_0_0, x_0_1, x_0_2, x_0_3], 1)x_0_4 = self.CONV0_4(x_0_4)if self.deep_supervision:out_put1 = self.final_super_0_1(x_0_1)out_put2 = self.final_super_0_2(x_0_2)out_put3 = self.final_super_0_3(x_0_3)out_put4 = self.final_super_0_4(x_0_4)return [out_put1, out_put2, out_put3, out_put4]else:return self.final_super_0_4(x_0_4)if __name__ == "__main__":print("deep_supervision: False")deep_supervision = Falsedevice = torch.device('cpu')inputs = torch.randn((1, 3, 224, 224)).to(device)model = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)outputs = model(inputs)print(outputs.shape)print("deep_supervision: True")deep_supervision = Truemodel = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)outputs = model(inputs)for out in outputs:print(out.shape)这篇关于UNet++学习/实现笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







