本文主要是介绍26版SPSS操作教程(高级教程第十八章),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
粉丝及官方意见说明
第十八章一些学习笔记
第十八章一些操作方法
经典判别分析
数据假设
具体操作
结果解释
判别结果的图形化展示
结果解释
判别效果验证
结果解释
适用条件的判断
结果解释
贝叶斯判别分析
具体操作
结果解释
逐步判别法
结束语
前言
#坚持不懈
#本期内容:经典判别分析
#由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次高级教程第十七章的学习笔记,希望能得到一些指正和帮助~
#感觉最近有点偷懒啊,爬武功山去了,五一去玩了,也没有更新......到今天晚上才更新
粉丝及官方意见说明
#针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件澄清如下:1、操作演示的数据全部由我本人随意假设输进去的,重在演示操作;2、本人也只是在学习阶段,希望友友们能谅解哈,手里有数据的宝子当然更好啦,没有咱就自己假设数据练习一下也没多大关系的哈;3、我也会在后续教程中尽量增加一些数据的必要性说明;4、大家有什么好的意见也可以在评论区一起交流吖~
第十八章一些学习笔记
- SPSS中的线性判别分析或者Fisher判别分析,简写为LDF/DF(linear discriminant analysis),判别分析的因变量是无序或有序分类变量,而自变量可以是任何测量尺度的变量,只是定性变量需要以哑变量(虚拟变量)的方式进入模型,目的在于建立一种变量的线性组合来概括分类变量之间的差异,从而可以根据已知样本的分类情况来判断未知分类样本的归属问题。--统计分析高级教程(第三版)P344
- SPSS中判别分析的适用条件:1、自变量和因变量间的关系符合线性假定;2、因变量的取值是独立的,且必须是事先就已经确定的;3、自变量服从多元正态分布;4、所有自变量在各组间的方差齐同,协方差矩阵也齐同;5、自变量间不存在多重共线性。若轻微违反条件,对结果的影响其实不大,样本量上,一般而言,样本量n至少为所使用的自变量个数p的5倍,为p的10~20倍时,函数才稳定,自变量个数在8~10个时,判别效果才比较理想,主要注意的是,自变量的个数越多,并不代表效果就越好。违反适用条件时的处理方法:1、多元正态分布假设被违反(一般影响不大,可以采用分段判别分析,还可以考虑变量变换);2、方差不齐(可以采用非参数判别分析、距离判别分析等无此适用条件的方法);3、多重共线性(逐步判别分析、岭判别分析等);4、线性假定被违反(二次判别分析、K-最近邻分类法或核密度估计法等方法)。--统计分析高级教程(第三版)P345-346
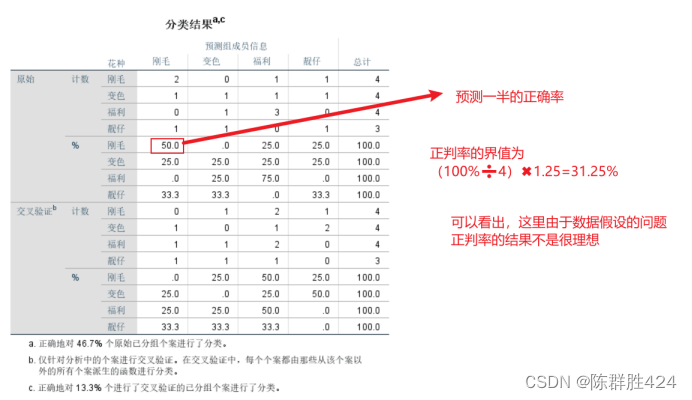
- SPSS中正判率达到多少合适,一般正确分类的比率应该超过随机分组正判率的20%或者25%;
 --统计分析高级教程(第三版)P346
--统计分析高级教程(第三版)P346 - SPSS判别分析的最终目的是将相应的模型用于对未知分类的新案例进行判别,完成建模后,在SPSS中至少有以下三种方式可以将模型用于新案例的分类工作:1、利用公式、领域图判别;2、在建模的同时进行判别;3、将模型储存为XML文件用于判别。--统计分析高级教程(第三版)P353
- SPSS判别分析和因子分析的相似性和差异:1、判别分析的结构反应在因变量的不同水平上,而因子分析的结构反应的是不可测量的潜变量;2、判别分析是因果模型(dependence model),因子分析是相依模型(interdependence model),在研究上没有因变量、自变量的区分;3、判别分析是尝试找到这种结构或者几个维度,在维度上因变量的不同类别差异最大,因子分析是尝试找到某种结构或者几个维度使变量之间的结构关系更加清晰;4、判别分析的维度是判别函数【标识不同因变量类别间的结构关系】,因子分析的维度是公因子【标识每个变量相对位置以及位置之间所揭示的结构关系】。--统计分析高级教程(第三版)P356
第十八章一些操作方法
经典判别分析
数据假设
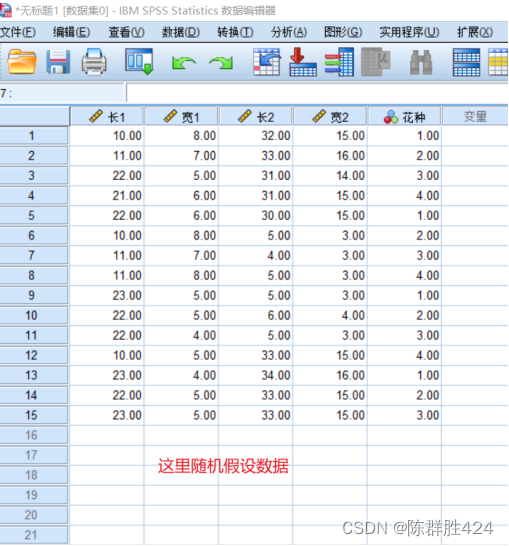
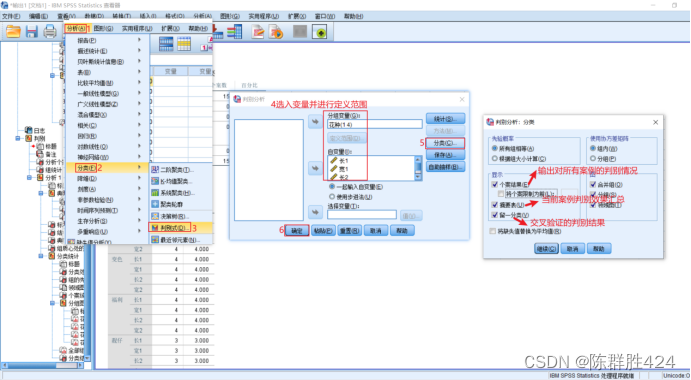
具体操作
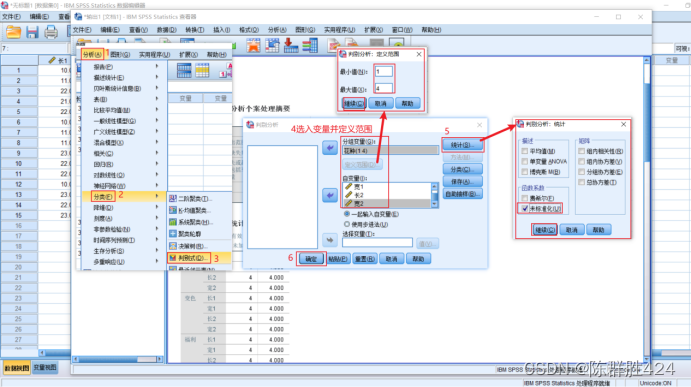
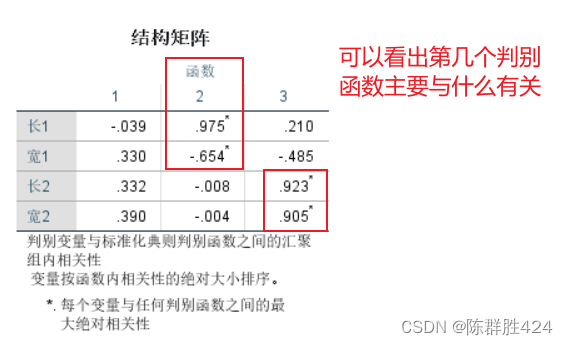
结果解释



判别结果的图形化展示
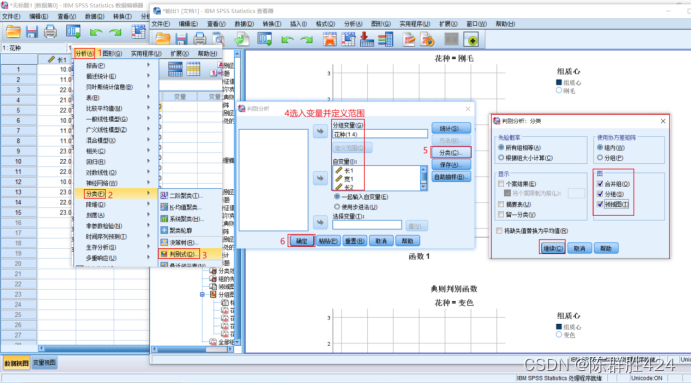
结果解释
领域图【字符绘制的低分辨率图形,将得出典型判别函数用图形的形式加以表达】

联合分布图【同时输出所有的类别,类似于分组分布图的叠加】
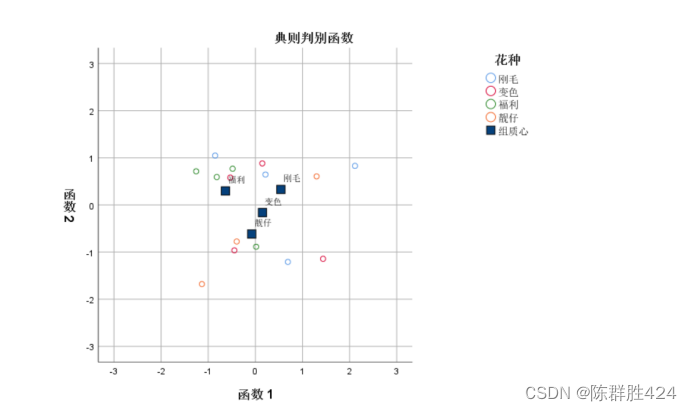
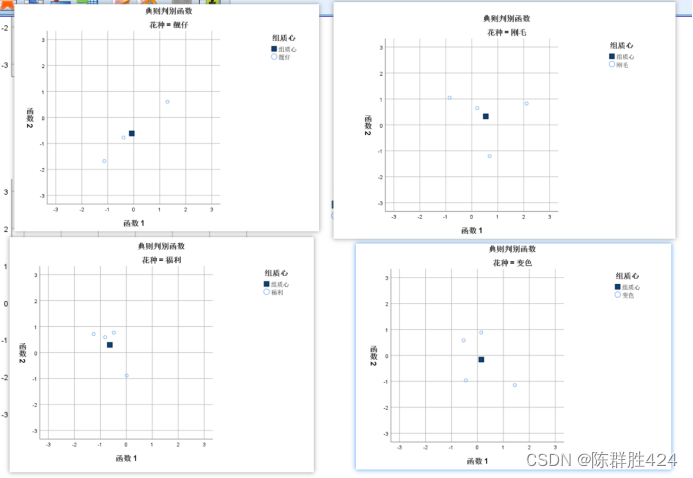
分组分布图【展示样本中各类别在判别空间中的分布情况,每一类别单独出一幅图】
判别效果验证
结果解释
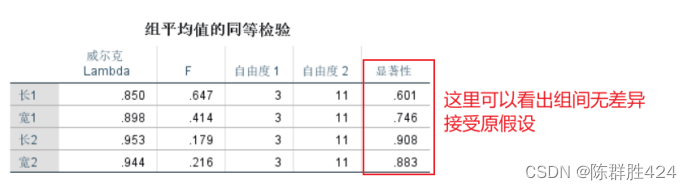
适用条件的判断
结果解释

贝叶斯判别分析
该方法与典型判别分析的差异在于,典型判别分析不考虑样本的具体分布,只求组间差异和组内差异的比值最大化;而贝叶斯判别分析是从样本的多元分布出发,充分利用多元正态分布的概率密度提供的信息计算后验概率。
具体操作
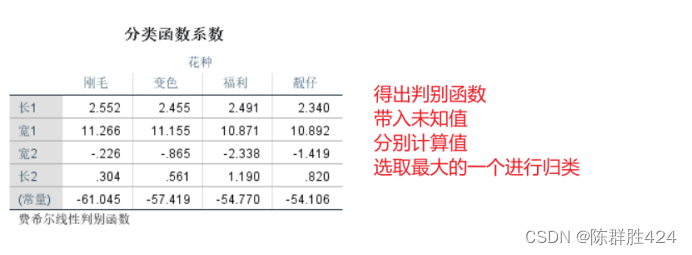
结果解释
逐步判别法

结束语
#好啦~,以上就是我SPSS第三十六期学习笔记——高级教程第十八章的学习情况啦~,希望能与大家交流学习经验,共同进步吖~
#考虑高级教程的难度与深度,主要是内容太多辣,后续依然会尽力更新内容~争取日更!
#也非常感谢大家对我的一路陪伴,宝子们的关注、支持和打赏就是up儿不断更新滴动力,我近期也会坚持学习SPSS,更新相应的学习内容及笔记到平台上,咱们下期高级教程不见不散~
这篇关于26版SPSS操作教程(高级教程第十八章)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





