本文主要是介绍pe结构之初体验(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
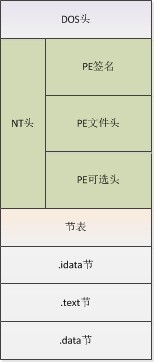
pe结构之初体验(一)我已经讲了dos及NT的Signature字段和IMAGE_FILE_HEADER结构。
在pe结构之初体验(二)中我将接着讲IMAGE_OPTIONAL_HEADER32结构
struct _IMAGE_OPTIONAL_HEADER {
18h: WORD Magic; //01 0B //(!重要) |10B-32位下的PE文件
1Ah: BYTE MajorLinkerVersion; //AA
1Bh: BYTE MinorLinkerVersion; //AA
1Ch: DWORD SizeOfCode; //AA AA AA AA
20h: DWORD SizeOfInitializedData; //AA AA AA AA
24h: DWORD SizeOfUninitializedData; //AA AA AA AA
28h: DWORD AddressOfEntryPoint; //00 00 00 02 //(!重要) |程序入口点(02,断在CC处)
2Ch: DWORD BaseOfCode; //AA AA AA AA
30h: DWORD BaseOfData; //AA AA AA AA
34h: DWORD ImageBase; //00 40 00 00 //(!重要) |内存镜像基址
38h: DWORD SectionAlignment; //00 00 10 00 //(!重要) |内存对齐
3Ch: DWORD FileAlignment; //00 00 02 00 //(!重要) |文件对齐
40h: WORD MajorOperatingSystemVersion; //AA AA
42h: WORD MinorOperatingSystemVersion; //AA AA
44h: WORD MajorImageVersion; //AA AA
46h: WORD MinorImageVersion; //AA AA
48h: WORD MajorSubsystemVersion; //00 04 //(!重要) |子系统版本号
WORD MinorSubsystemVersion; //AA AA
DWORD Win32VersionValue; //AA AA AA AA
DWORD SizeOfImage; //00 00 20 00 //(!重要) |PE文件映射到内存后的尺寸,SectionAlignment的倍数
DWORD SizeOfHeaders; //00 00 02 00 //(!重要) |所有头+节表按照文件对齐后的大小
DWORD CheckSum; //AA AA AA AA
WORD Subsystem; //00 02 //(!重要) |子系统
WORD DllCharacteristics; //00 00 //(!重要) |
DWORD SizeOfStackReserve; //00 40 00 00 //(!重要) |初始化时保留的栈大小(桟最大值)
DWORD SizeOfStackCommit; //00 00 10 00 //(!重要) |初始化时实际提交的栈大小(实际使用桟大小)
DWORD SizeOfHeapReserve; //00 10 00 00 //(!重要) |初始化时保留的堆大小(堆最大值)
DWORD SizeOfHeapCommit; //00 01 00 00 //(!重要) |初始化时实际提交的堆大小(实际使用堆大小)
DWORD LoaderFlags; //AA AA AA AA
DWORD NumberOfRvaAndSizes; //00 00 00 04 //(!重要) |目录项数目(4),其实最优是2项,有导入表即可
_IMAGE_DATA_DIRECTORY DataDirectory[16]; //目录项(4个目录项,先全初始化为0)
};AddressOfEntryPoint字段,指出文件被执行时的入口地址,这是一个RVA地址(相对虚拟地址)。这个域表示应用程序入口点的位置。并且,对于系统黑客来说,这个位置就是导入地址表(IAT)的末尾。
ImageBase字段:进程映像地址空间中的首选基地址(文件的优先装入地址)。Windows NT的Microsoft Win32 SDK链接器将exe文件这个值默认设为0x00400000(而DLL默认为10000000h),但是你可以使用-BASE:linker开关改变这个值。(如果装入地址被占据,则由Windows装载器改架到其它地方,所以就需要进行重定位操作,影响效率。对于EXE文件因为它总是使用独立的虚拟地址空间,所以装入地址不可能被占用,而DLL文件则必须包含重定位信息了)
SectionAlignment字段:内存中的区块的对齐大小。Windows NT虚拟内存管理器规定,段对齐不能少于页尺寸(当前的x86平台是4096字节),并且必须是成倍的页尺寸。4096字节是x86链接器的默认值,但是它可以通过-ALIGN: linker开关来设置。 (32位位1000h,即4kb;64位为2000h,即8kb。而一般我们的程序兼容或者不兼容,就是因为这个对齐大小不一样)
FileAlignment字段:文件(磁盘)中的区块大小。映像文件首先装载的最小的信息块间隔。例如,链接器将一个段实体(段的原始数据)加零扩展为文件中最接近的FileAlignment边界。早先提及的2.39版链接器将映像文件以0x200字节的边界对齐,这个值可以被强制改为512到65535这么多。 (一般情况下32位为200h,即200个字节)
NumberOfRvaAndSizes字段。这个域标识了接下来的DataDirectory数组。请注意它被用来标识这个数组,而不是数组中的各个入口数字,这一点非常重要。(自Windows NT发布以来一直都是16)
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]。
即DataDirectory字段。数据目录表示文件中其它可执行信息重要组成部分的位置。它事实上就是一个由16个相同的IMAGE_DATA_DIRECTORY结构的数组组成(结构里面的结构的结构),位于可选头部结构的末尾。当前的PE文件格式定义了16种可能的数据目录,这之中的11种现在在使用中。
IMAGE_DATA_DIRECTORY结构的定义:
IMAGE_DATA_DIRECTORY STRUCT
VirtualAddress DWORD?; //数据的起始RVA
isize DWORD?; //数据块的长度
IMAGE_DATA_DIRECTORY ENDS数据目录列表的含义:
一、PE文件到内存的映射
(1)在执行一个PE文件的时候,windows 并不在一开始就将整个文件读入内存的,而是采用与内存映射文件类似的机制。也就是说,windows 装载器在装载的时候仅仅建立好虚拟地址和PE文件之间的映射关系。当且仅当真正执行到某个内存页中的指令或者访问某一页中的数据时,这个页面才会被从磁盘提交到物理内存,这种机制使文件装入的速度和文件大小没有太大的关系。
(2)但是要注意的是,系统装载可执行文件的方法又不完全等同于内存映射文件。当使用内存映射文件的时候,系统对“原著”相当忠实,如果将磁盘文件和内存映像比较的话,可以发现不管是数据本身还是数据之间的相对位置它丫丫的都是完全相同的。而我们知道,在装载可执行文件的时候,有些数据在装入前会被预处理,如重定位等,正因此,装入以后,数据之间的相对位置可能发生微妙的变化。
(3)Windows 装载器在装载DOS部分、PE文件头部分和节表(区块表)部分是不进行任何特殊处理的,而在装载节(区块)的时候则会自动按节(区块)的属性做不同的处理。
一般情况下,它会处理以下几个方面的内容:
内存页的属性;
节的偏移地址;
节的尺寸;
不进行映射的节。
二、对节(区块)的处理
(1)内存页的属性:
对于磁盘映射文件来说,所有的页都是按照磁盘映射文件函数指定的属性设置的。但是在装载可执行文件时,与节对应的内存页属性要按照节的属性来设置。所以,在同属于一个模块的内存页中,从不同节映射过来的的内存页的属性是不同的。
(2)节的偏移地址:
1.节的起始地址在磁盘文件中是按照 IMAGE_OPTIONAL_HEADER32 结构的 FileAlignment 字段的值进行对齐的,而当被加载到内存中时是按照同一结构中的 SectionAlignment 字段的值对其的,两者的值可能不同,所以一个节被装入内存后相对于文件头的偏移和在磁盘文件中的偏移可能是不同的。
2.注意,节事实上就是相同属性数据的组合!当节被装入到内存中的时候,相同一个节所对应的内存页都将被赋予相同的页属性, 事实上,Windows 系统对内存属性的设置是以页为单位进行的,所以节在内存中的对齐单位必须至少是一个页的大小。(小甲鱼温馨提示:对于32位操作系统来说,这个值一般是4KB==1000H; 对于64位操作系统这个值一般是8KB==2000H)
3.在磁盘中就没有这个限制,因为在磁盘中排放是以什么为主?肯定是以空间为主导,在磁盘只是存放,不是使用,所以不用设置那么详细的属性。试想想看,如果在磁盘中都是以4KB为大小对齐的话,不够就用0来填充,那么一个只占20字节的数据就要消耗4KB的空间来存放,是不是浪费?有木有??
(3)节的尺寸:
对节的尺寸的处理主要分为两个方面:
第一个方面,正如刚刚我们所讲的,由于磁盘映像和内存映像中节对齐存储单位的不同而导致了长度扩展不同(填充的0数量不同嘛~);
第二个方面,是对于包含未初始化数据的节的处理问题。既然是未初始化,那么没有必要为其在磁盘中浪费空间资源,但在内存中不同,因为程序一运行,之前未初始化的数据便有可能要被赋值初始化,那么就必须为他们留下空间。
(4)不进行映射的节:
有些节并不需要被映射到内存中,例如.reloc节,重定位数据对于文件的执行代码来说是透明的,无作用的,它只是提供Windows 装载器使用,执行代码根本不会去访问到它们,所以没有必要将他们映射到物理内存中。(重定位在上一讲PE可选头中的ImageBase字段粗略讲过大致意思,后面会具体讲的)
三、节表(区块表)
(1)PE文件中所有节的属性都被定义在节表中,节表由一系列的IMAGE_SECTION_HEADER结构排列而成,每个结构用来描述一个节,结构的排列顺序和它们描述的节在文件中的排列顺序是一致的。全部有效结构的最后以一个空的IMAGE_SECTION_HEADER结构作为结束,所以节表中总的IMAGE_SECTION_HEADER结构数量等于节的数量加一。节表总是被存放在紧接在PE文件头的地方。
(2)另外,节表中 IMAGE_SECTION_HEADER 结构的总数总是由PE文件头 IMAGE_NT_HEADERS 结构中的 FileHeader.NumberOfSections 字段来指定的。
typedef struct _IMAGE_SECTION_HEADER
{BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 节表名称,如“.text” //IMAGE_SIZEOF_SHORT_NAME=8union{DWORD PhysicalAddress; // 物理地址DWORD VirtualSize; // 真实长度,这两个值是一个联合结构,可以使用其中的任何一个,一// 般是取后一个} Misc;DWORD VirtualAddress; // 节区的 RVA 地址DWORD SizeOfRawData; // 在文件中对齐后的尺寸DWORD PointerToRawData; // 在文件中的偏移量DWORD PointerToRelocations; // 在OBJ文件中使用,重定位的偏移DWORD PointerToLinenumbers; // 行号表的偏移(供调试使用地)WORD NumberOfRelocations; // 在OBJ文件中使用,重定位项数目WORD NumberOfLinenumbers; // 行号表中行号的数目DWORD Characteristics; // 节属性如可读,可写,可执行等
}IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
这篇关于pe结构之初体验(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







