本文主要是介绍guidance - Microsoft 推出的编程范式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、关于 guidance
- 安装
- 二、加载模型
- llama.cpp
- Transformers
- Vertex AI
- OpenAI
- 三、基本生成
- 四、限制的生成
- 选择(基本)
- 正则表达
- 正则表达式来限制生成
- 正则表达式作为停止标准
- 上下文无关语法
- 五、状态控制+生成
- 1、不可变对象中的状态
- 2、有状态的 `guidance` 函数
- 3、示例:ReAct
- 4、示例:更改聊天会话的中间步骤
- 5、控制和生成的自动交错:工具的使用
- 6、GSM8k 示例
- 7、@guidance函数的自动调用语法
- 六、文本,而不是 tokens
- 七、快速使用
- 1、集成状态控制速度更快
- 2、Guidance 加速度
一、关于 guidance
- github : https://github.com/guidance-ai/guidance
- 示例 notebooks (正在努力更新)
- 基础教程
- 带搜索功能的聊天机器人
- Microsoft Guidance Offers Language for Controlling Large Language Models
https://www.infoq.com/news/2023/06/guidance-microsoft-language/
guidance 是一种编程范例,与传统的提示和链相比,它提供了卓越的控制和效率。
它允许用户限制生成(例如 使用正则表达式和CFG)以及无缝地交错控制(条件、循环)和生成。
以下是一些重要的功能:
1、 纯粹、漂亮的 python以及额外的 LM 功能。例如,这是基本生成:
from guidance import models, gen# load a model (could be Transformers, LlamaCpp, VertexAI, OpenAI...)
llama2 = models.LlamaCpp(path) # append text or generations to the model
llama2 + f'Do you want a joke or a poem? ' + gen(stop='.')

2、 使用selects、正则表达式和上下文无关语法 进行约束生成。
from guidance import select# a simple select between two options
llama2 + f'Do you want a joke or a poem? A ' + select(['joke', 'poem'])

3、 带有 f 字符串的丰富模板:
llama2 + f'''\
Do you want a joke or a poem? A {select(['joke', 'poem'])}.
Okay, here is a one-liner: "{gen(stop='"')}"
'''

4、 有状态控制+生成 可以轻松交错提示/逻辑/生成,无需中间解析器:
# capture our selection under the name 'answer'
lm = llama2 + f"Do you want a joke or a poem? A {select(['joke', 'poem'], name='answer')}.\n"# make a choice based on the model's previous selection
if lm["answer"] == "joke":lm += f"Here is a one-line joke about cats: " + gen('output', stop='\n')
else:lm += f"Here is a one-line poem about dogs: " + gen('output', stop='\n')

5、抽象聊天界面,为任何聊天模型使用正确的特殊tokens:
from guidance import user, assistant# load a chat model
chat_lm = models.LlamaCppChat(path)
***
# wrap with chat block contexts
with user():lm = chat_lm + 'Do you want a joke or a poem?'with assistant():lm += f"A {select(['joke', 'poem'])}."`

6、易于编写可重用组件
import guidance@guidance
def one_line_thing(lm, thing, topic):lm += f'Here is a one-line {thing} about {topic}: ' + gen(stop='\n')return lm # return our updated model# pick either a joke or a poem
lm = llama2 + f"Do you want a joke or a poem? A {select(['joke', 'poem'], name='thing')}.\n"# call our guidance function
lm += one_line_thing(lm['thing'], 'cats')

7、 预构建组件库,例如子字符串:
from guidance import substring# define a set of possible statements
text = 'guidance is awesome. guidance is so great. guidance is the best thing since sliced bread.'# force the model to make an exact quote
llama2 + f'Here is a true statement about the guidance library: "{substring(text)}"'

8、 简单的工具使用,模型在调用工具时 停止生成,调用该工具,然后恢复生成。
例如,这是一个简单版本的计算器,通过四个单独的“工具”:
@guidance
def add(lm, input1, input2):lm += f' = {int(input1) + int(input2)}'return lm
@guidance
def subtract(lm, input1, input2):lm += f' = {int(input1) - int(input2)}'return lm
@guidance
def multiply(lm, input1, input2):lm += f' = {float(input1) * float(input2)}'return lm
@guidance
def divide(lm, input1, input2):lm += f' = {float(input1) / float(input2)}'return lm
现在我们gen使用这些工具作为选项进行调用。请注意生成是如何 自动停止和重新启动的:
lm = llama2 + '''\
1 + 1 = add(1, 1) = 2
2 - 3 = subtract(2, 3) = -1
'''
lm + gen(max_tokens=15, tools=[add, subtract, multiply, divide])

9、 速度:与链接相比,guidance程序相当于单个 LLM 调用。更重要的是,无论附加的非生成文本都是批处理的,因此当您有固定结构时,guidance程序比 LM 生成中间文本更快。
10、 Token修复:用户处理文本(或字节)而不是令牌,因此不必担心不正当的令牌边界问题,例如“提示以空格结尾”。
11、 流支持,也与 Jupyter 笔记本集成:
lm = llama2 + 'Here is a cute 5-line poem about cats and dogs:\n'
for i in range(5):lm += f"LINE {i+1}: " + gen(temperature=0.8, suffix="\n")

对于不支持指南丰富的基于 IPython/Jupyter/HTML 的可视化的环境(例如控制台应用程序),可以通过echo=False在任何对象的构造函数中设置来抑制所有可视化和控制台输出guidance.models:
llama2 = models.LlamaCpp(path, echo=False)
12、 **高兼容性:**可与 Transformers、llama.cpp、VertexAI、OpenAI 配合使用。用户可以编写一个引导程序并在多个后端上执行它。 (请注意,最强大的控制功能需要端点集成,目前与 Transformers 和 llama.cpp 配合使用效果最佳)。
gpt = models.OpenAI("gpt-3.5-turbo")
***
with user():lm = gpt + "What is the capital of France?"with assistant():lm += gen("capital")
***
with user():lm += "What is one short surprising fact about it?"with assistant():lm += gen("fact")

13、 多模态支持。
from guidance import imagegemini = models.VertexAI("gemini-pro-vision")
***
with user():lm = gemini + "What is this a picture of?" + image("longs_peak.jpg")
***
with assistant():lm += gen("answer")

安装
pip install guidance
二、加载模型
llama.cpp
安装 python 绑定:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
加载模型:
from guidance import models
lm = models.LlamaCpp(path_to_model, n_gpu_layers=-1)
Transformers
安装 Transformers:
from guidance import models
lm = models.Transformers(model_name_or_path)
Vertex AI
没有明确指导集成的远程端点会“乐观地”运行。这意味着所有可以强制的文本都会作为提示(或聊天上下文)提供给模型,然后模型在没有硬约束的情况下以流模式运行(因为远程 API 不支持它们)。如果模型违反了约束,则模型流将停止,我们可以选择在此时重试。这意味着所有 API 支持的控制都会按预期工作,如果模型与程序保持一致,API 不支持的更复杂的控制/解析也会工作。
palm2 = models.VertexAI("text-bison@001")
***
with instruction():lm = palm2 + "What is one funny fact about Seattle?"lm + gen("fact", max_tokens=100)

OpenAI
OpenAI端点不直接支持指导语法,但通过乐观运行,我们仍然可以以与模型类型匹配的方式控制它们:
Legacy completion models::
curie = models.OpenAI("text-curie-001")
***
curie + "The smallest cats are" + gen(stop=".")

指导调整模型:
gpt_instruct = models.OpenAI("gpt-3.5-turbo-instruct")
***
with instruction():lm = gpt_instruct + "What are the smallest cats?"lm += gen(stop=".")

聊天模型:
gpt = models.OpenAI("gpt-3.5-turbo")
***
with system():lm = gpt + "You are a cat expert."with user():lm += "What are the smallest cats?"with assistant():lm += gen("answer", stop=".")

三、基本生成
对象lm是不可变的,因此您可以通过创建它的新副本来更改它。默认情况下,当您将内容附加到 时lm,它会创建一个副本,例如:
from guidance import models, gen, select
llama2 = models.LlamaCpp(model)
***
# llama2 is not modified, `lm` is a copy of `llama2` with 'This is a prompt' appended to its state
lm = llama2 + 'This is a prompt'
您可以将生成调用附加到模型对象,例如
lm = llama2 + 'This is a prompt' + gen(max_tokens=10)

您还可以将生成调用与纯文本或控制流交错:
# Note how we set stop tokens
lm = llama2 + 'I like to play with my ' + gen(stop=' ') + ' in' + gen(stop=['\n', '.', '!'])

四、限制的生成
选择(基本)
select将生成限制为一组选项:
lm = llama2 + 'I like the color ' + select(['red', 'blue', 'green'])

正则表达
gen有可选参数regex和stop_regex,允许通过正则表达式控制生成(和停止)。
正则表达式来限制生成
无约束:
lm = llama2 + 'Question: Luke has ten balls. He gives three to his brother.\n'
lm += 'How many balls does he have left?\n'
lm += 'Answer: ' + gen(stop='\n')

受正则表达式约束:
lm = llama2 + 'Question: Luke has ten balls. He gives three to his brother.\n'
lm += 'How many balls does he have left?\n'
lm += 'Answer: ' + gen(regex='\d+')

正则表达式作为停止标准
无约束:
lm = llama2 + '19, 18,' + gen(max_tokens=50)
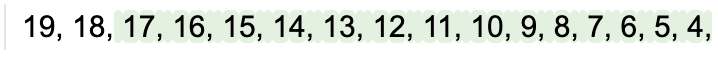
当模型生成数字 7 时,使用传统的停止文本停止:
lm = llama2 + '19, 18,' + gen(max_tokens=50, stop='7')
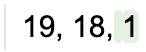
当模型生成7周围没有任何数字的角色时停止:
lm = llama2 + '19, 18,' + gen(max_tokens=50, stop_regex='[^\d]7[^\d]')
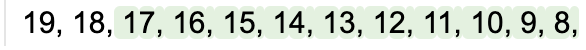
上下文无关语法
我们公开了各种运算符,可以轻松定义 CFG,而 CFG 又可用于约束生成。例如,我们可以使用select运算符(它接受 CFG 作为选项),zero_or_more并one_or_more定义数学表达式的语法:
import guidance
from guidance import one_or_more, select, zero_or_more
# stateless=True indicates this function does not depend on LLM generations
@guidance(stateless=True)
def number(lm):n = one_or_more(select(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']))# Allow for negative or positive numbersreturn lm + select(['-' + n, n])
***
@guidance(stateless=True)
def operator(lm):return lm + select(['+' , '*', '**', '/', '-'])
***
@guidance(stateless=True)
def expression(lm):# Either# 1. A number (terminal)# 2. two expressions with an operator and optional whitespace# 3. An expression with parentheses around itreturn lm + select([number(),expression() + zero_or_more(' ') + operator() + zero_or_more(' ') + expression(),'(' + expression() + ')'])
装饰@guidance(stateless=True)器使得函数(例如)作为无状态语法存在,直到我们调用 call或expression为止不会“执行” 。例如,以下是无约束生成的示例:lm + expression()``lm += expression()
# Without constraints
lm = llama2 + 'Problem: Luke has a hundred and six balls. He then loses thirty six.\n'
lm += 'Equivalent arithmetic expression: ' + gen(stop='\n') + '\n'

请注意模型如何写出正确的方程但却(错误地)求解它。如果我们想限制模型,使其只编写有效的表达式(而不尝试解决它们),我们可以将语法附加到它:
grammar = expression()
lm = llama2 + 'Problem: Luke has a hundred and six balls. He then loses thirty six.\n'
lm += 'Equivalent arithmetic expression: ' + grammar + '\n'
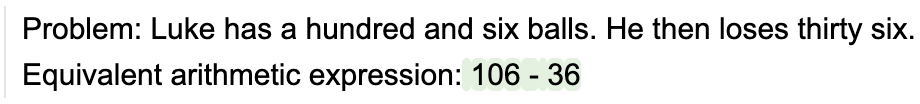
语法很容易编写。例如,假设我们想要一个语法来生成一个数学表达式或一个表达式后跟一个解决方案,然后是另一个表达式。创建这个语法很简单:
from guidance import regex
grammar = select([expression(), expression() + regex(' = \d+; ') + expression()])
我们可以根据它来生成:
llama2 + 'Here is a math expression for two plus two: ' + grammar

llama2 + '2 + 2 = 4; 3+3\n' + grammar
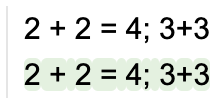
即使您不喜欢用递归语法来思考,这种形式主义也很容易限制生成。例如,假设我们有以下一次性提示:
@guidance(stateless=True)
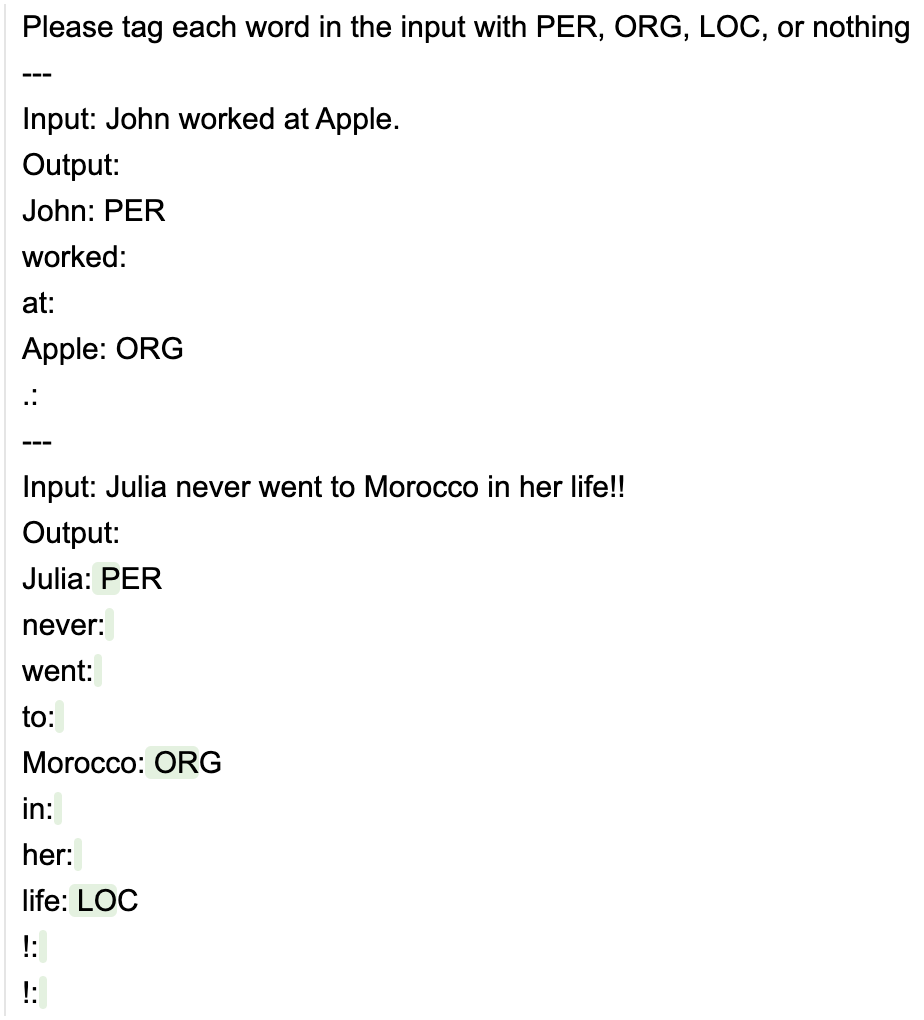
def ner_instruction(lm, input):lm += f'''\Please tag each word in the input with PER, ORG, LOC, or nothing---Input: John worked at Apple.Output:John: PERworked: at: Apple: ORG.: ---Input: {input}Output:'''return lm
input = 'Julia never went to Morocco in her life!!'
llama2 + ner_instruction(input) + gen(stop='---')

请注意,模型没有正确拼写“Morocco”一词。有时,模型也可能会产生一个不存在的标签的幻觉。我们可以通过添加更多的小样本示例等来改进这一点,但我们也可以将生成限制为我们想要的确切格式:
import re@guidance(stateless=True)
def constrained_ner(lm, input):# Split into wordswords = [x for x in re.split('([^a-zA-Z0-9])', input) if x and not re.match('\s', x)]ret = ''for x in words:ret += x + ': ' + select(['PER', 'ORG', 'LOC', '']) + '\n'return lm + ret
llama2 + ner_instruction(input) + constrained_ner(input)
虽然constrained_ner(input) 是一种限制模型生成的语法,但感觉就像您只是使用+=和编写普通的命令式 python 代码selects。
五、状态控制+生成
1、不可变对象中的状态
每当您执行lm + grammar或lm + gen、lm + select等操作时,您都会返回一个具有附加状态的新 lm 对象。例如:
lm = llama2 + 'This is a prompt' + gen(name='test', max_tokens=10)
lm += select(['this', 'that'], name='test2')
lm['test'], lm['test2']

2、有状态的 guidance 函数
引导装饰器是@guidance(stateless=False)默认的,这意味着具有此装饰器的函数取决于 要执行的 lm 状态(先前状态或函数内生成的状态)。例如:
@guidance(stateless=False)
def test(lm):lm += 'Should I say "Scott"?\n' + select(['yes', 'no'], name='answer') + '\n'if lm['answer'] == 'yes':lm += 'Scott'else:lm += 'Not Scott'return lm
llama2 + test()

3、示例:ReAct
有状态控制的一大优点是,您不必编写任何中间解析器,并且添加后续“提示”很容易,即使后续取决于模型生成的内容。
例如,假设我们要在this中实现 ReAct 提示的第一个示例,并且假设有效行为只有“搜索”或“完成”。我们可以这样写:
@guidance
def react_prompt_example(lm, question, max_rounds=10):lm += f'Question: {question}\n'i = 1while True:lm += f'Thought {i}: ' + gen(suffix='\n')lm += f'Act {i}: ' + select(['Search', 'Finish'], name='act') lm += '[' + gen(name='arg', suffix=']') + '\n'if lm['act'] == 'Finish' or i == max_rounds:breakelse:lm += f'Observation {i}: ' + search(lm['arg']) + '\n'i += 1return lm
请注意,我们不必为 Act 和 argument 编写解析器,并希望模型生成有效的内容:我们强制执行它。另请注意,只有当模型选择“完成”(或达到最大轮数)时,循环才会停止。
4、示例:更改聊天会话的中间步骤
我们还可以隐藏或更改模型生成的一些内容。例如,下面我们得到一个聊天模型(注意我们使用特殊role块)来命名一些专家来回答问题,但如果提到他,我们总是从列表中删除“Ferriss”:
from guidance import user, system, assistant
lm = llama2query = 'How can I be more productive?'
with system():lm += 'You are a helpful and terse assistant.'
with user():lm += f'I want a response to the following question:\n{query}\n'lm += 'Name 3 world-class experts (past or present) who would be great at answering this.'
with assistant():temp_lm = lmfor i in range(1, 4):# This regex only allows strings that look like names (where every word is capitalized)# list_append appends the result to a listtemp_lm += f'{i}. ' + gen(regex='([A-Z][a-z]*\s*)+', suffix='\n',name='experts', list_append=True)experts = [x for x in temp_lm['experts'] if 'Ferriss' not in x]# Notice that even if the model generates 'Ferriss' above,# it doesn't get added to `lm`, only to `temp_lm`lm += ', '.join(experts)
with user():lm += 'Please answer the question as if these experts had collaborated in writing an anonymous answer.'
with assistant():lm += gen(max_tokens=100)

5、控制和生成的自动交错:工具的使用
工具使用是状态控制的常见情况。为了简化此操作,gen调用采用tools可选参数,其中每个工具由 (1) 触发其调用并捕获参数(如果有)的语法和 (2) 实际工具调用定义。然后,随着生成的展开,每当模型生成与工具调用的语法相匹配的内容时,它就会 (1) 停止生成,(2) 调用该工具(它可以将它想要的任何内容附加到 LM 会话中),以及 (3)继续一代。
例如,以下是我们如何利用expression上面的语法来实现计算器工具:
from guidance import capture, Tool
@guidance(stateless=True)
def calculator_call(lm):# capture just 'names' the expression, to be saved in the LM statereturn lm + 'calculator(' + capture(expression(), 'tool_args') + ')'@guidance
def calculator(lm):expression = lm['tool_args']# You typically don't want to run eval directly for save reasons# Here we are guaranteed to only have mathematical expressionslm += f' = {eval(expression)}'return lm
calculator_tool = Tool(calculator_call(), calculator)
lm = llama2 + 'Here are five expressions:\ncalculator(3 *3) = 33\ncalculator(2 + 1 * 3) = 5\n'
lm += gen(max_tokens=30, tools=[calculator_tool], stop='\n\n')
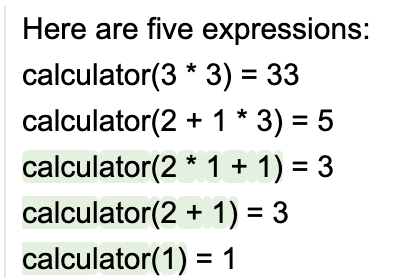
6、GSM8k 示例
请注意,计算器只是在生成过程中无缝调用。这是解决 gsm8k 问题的模型的更实际示例:
@guidance
def math_with_calc(lm, question):# Two-shot examplelm += '''\Question: John starts with 2 balls. He then quintupled his number of balls. Then he lost half of them. He then gave 3 to his brother. How many does he have left?Reasoning:1. He quintupled his balls. So he has calculator(2 * 5) = 10 balls.1. He lost half. So he has calculator(10 / 2) = 5 balls.3. He gave 3 to his brother. So he has calculator(5 - 3) = 2 balls.Answer: 2Question: Jill get 7 dollars a day in allowance. She uses 1 each day to by a bus pass, then gives half away. How much does she have left each day?Reasoning:1. She gets 7 dollars a day.1. She spends 1 on a bus pass. So she has calculator(5 - 1) = 6.3. She gives half away. So that makes calculator(6 / 2) = 3.Answer: 3'''lm += f'Question: {question}\n'lm += 'Reasoning:\n' + gen(max_tokens=200, tools=[calculator_tool], stop='Answer')# Only numbers or commaslm += 'Answer: ' + gen(regex='[-\d,]+')return lmquestion = '''Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market?'''
llama2 + math_with_calc(question)

7、@guidance函数的自动调用语法
您还可以Tool使用任何@guidance- 修饰的函数来初始化 a ,默认的调用语法将类似于 python 调用。以下是在同一调用中使用多个此类工具的示例gen:
@guidance
def say_scott(lm, n):lm += '\n'for _ in range(int(n)):lm += 'Scott\n'return lm@guidance
def say_marco(lm, n):lm += '\n'for _ in range(int(n)):lm += 'marco\n'return lmtools = [Tool(callable=say_scott), Tool(callable=say_marco)]
llama2 + '''\
I am going to call say_scott and say_marco a few times:
say_scott(1)
Scott
''' + gen(max_tokens=20, tools=tools)

六、文本,而不是 tokens
大多数语言模型使用的标准贪婪标记化引入了各种微妙而强大的偏差,这可能会对您的提示产生各种意想不到的后果。例如,采用 gpt-2(标准贪婪标记化)的以下提示:
hf_gen(提示,max_tokens=10)
from transformers import pipeline
pipe = pipeline("text-generation", model="gpt2")
def hf_gen(prompt, max_tokens=100):return pipe(prompt, do_sample=False, max_length=max_tokens, return_full_text=False)[0]['generated_text']prompt = 'http:'
hf_gen(prompt, max_tokens=10)
请注意 LLM 生成的输出如何不使用明显的下一个字符(两个正斜杠)来完成 URL。相反,它会创建一个中间有空格的无效 URL 字符串。为什么?因为字符串://是它自己的标记,所以一旦模型本身看到冒号,它就会假设接下来的字符不能是//;否则,分词器不会使用:,而是会使用://。这就是为什么会出现关于以空格结束提示的警告,但问题比这更普遍:任何可能跨越多个标记的边界都会导致问题,例如,注意部分单词如何导致不正确的完成:
prompt = 'John is a'
hf_gen(prompt, max_tokens=5)
prompt = 'John is a fo'
hf_gen(prompt, max_tokens=5)
虽然对于正常提示来说问题已经足够多了,但对于我们在本自述文件中编写的提示类型来说,这些问题将是一场灾难,其中提示和生成会多次交错发生(因此有多个出现问题的机会)。这就是为什么guidance要实现令牌修复,这是一种自动处理提示边界的功能,允许用户仅根据文本而不是令牌进行思考。例如:
from guidance import models
gpt = models.Transformers('gpt2')
prompt = 'http:'
gpt + prompt + gen(max_tokens=10)
prompt = 'John is a fo'
gpt + prompt + gen(max_tokens=2)
七、快速使用
1、集成状态控制速度更快
transformers在与和 的集成中,我们可以完全控制解码循环llamacpp,从而允许我们添加控制和附加提示,而无需任何额外成本。
相反,如果我们调用服务器,则需要支付发出额外请求的额外成本,如果服务器有缓存,这可能没问题,但如果服务器没有细粒度缓存,这很快就会变得不切实际。例如,再次注意上面计算器的 gsm8k 示例的输出: 
每次调用 时calculator,我们都必须停止生成,将结果附加到提示中,然后恢复生成。为了避免在第一次调用后速度变慢,服务器需要将 KV 缓存保持在“3”作为早餐。所以她有计算器(16 - 3)',然后从该点开始向前滚动生成。即使有缓存的服务器通常也无法保证在每次停止和启动时保留状态,因此用户在每次中断时都要付出巨大的开销。将所有内容视为新提示的正常方法会导致每次calculator调用时速度显着减慢。
2、Guidance 加速度
除了上述好处之外,guidance调用通常比以传统方式运行等效提示更快,因为我们可以在执行展开时批处理用户添加的任何其他文本(而不是生成它)。以下面的示例为例,我们llama2使用 llama.cpp 执行,生成一个带有 GGUF 压缩 7B 的 json :
@guidance
def character_maker(lm, id, description, valid_weapons):lm += f"""\The following is a character profile for an RPG game in JSON format.```json{{"id": "{id}","description": "{description}","name": "{gen('name', stop='"')}","age": {gen('age', regex='[0-9]+', stop=',')},"armor": "{select(options=['leather', 'chainmail', 'plate'], name='armor')}","weapon": "{select(options=valid_weapons, name='weapon')}","class": "{gen('class', stop='"')}","mantra": "{gen('mantra', stop='"')}","strength": {gen('strength', regex='[0-9]+', stop=',')},"items": ["{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}", "{gen('item', list_append=True, stop='"')}"]}}```"""return lm
a = time.time()
lm = llama2 + character_maker(1, 'A nimble fighter', ['axe', 'sword', 'bow'])
time.time() - a

所有非绿色的东西实际上并不是由模型生成的,因此是批处理的(速度更快)。在 A100 GPU 上,此提示大约需要 1.2 秒。现在,如果我们让模型生成所有内容(如下面大致等效的提示所示),大约需要2.6几秒钟(不仅速度更慢,而且我们对生成的控制也更少)。
@guidance
def character_maker2(lm, id, description):lm += f"""\The following is a character profile for an RPG game in JSON format. It has fields 'id', 'description', 'name', 'age', 'armor', weapon', 'class', 'mantra', 'strength', and 'items (just the names of 3 items)'please set description to '{description}'```json""" + gen(stop='```')return lm
a = time.time()
lm = llama2 + character_maker2(1, 'A nimble fighter')
time.time() - a

2024-05-02(四)
这篇关于guidance - Microsoft 推出的编程范式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






