本文主要是介绍经典网络解读——Efficientnet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(2019.5)
作者:Mingxing Tan, Quoc V. Le
链接:https://arxiv.org/abs/1905.11946
代码:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
Efficientnet升级版本EfficientnetV2解读
最近项目上用到,由于之前模型采用IResnet50做识别,在rv1126上量化成int16时间上不满足要求,量化成int8推理造成的精度下降又太大,不能接受,遂想到替换更高效的网络,网上一搜就看到下面这张图,很直观。
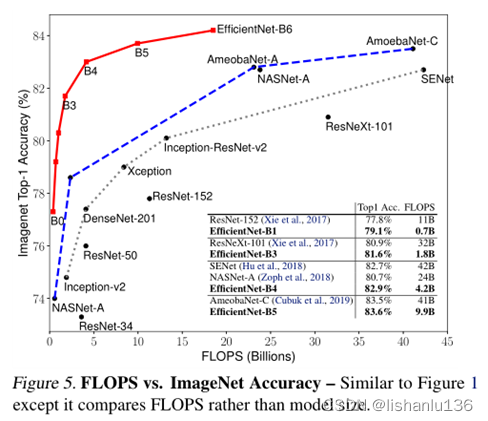
efficientnet-B0比ResNet-50的精度更高且flops更少,且一直扩充到efficientnet-B3都是如此,类比IResnet50,估计efficientnet也比它快;由于efficientnet是分类网络,但我们是识别任务,需要提取feature,所以需做修改,下面是量化成int16后的具体推理时间,与我的猜想基本一致。
| 网络结构 | 转int16的rknn模型大小(M) | input_size | rv1126上用NPU推理时间(ms) |
|---|---|---|---|
| iResnet-50 | 112x112 | 70 | |
| efficientnet-b0(仿照iresnet改造,卷积最后一层,直接flatten) | 25.8 | 112x112 | 17 |
| efficientnet-b0(直接将最后类别数改成num_features数量,精度不行) | 9.3 | 112x112 | 13 |
| efficientnet-b1(仿照iresnet改造,卷积最后一层,直接flatten) | 33 | 112x112 | 25 |
| efficientnet-b2(仿照iresnet改造,卷积最后一层,直接flatten) | 39.7 | 112x112 | 28 |
| efficientnet-b3(仿照iresnet改造,卷积最后一层,直接flatten) | 47.3 | 112x112 | 35 |
虽然之前经常用这个网络,但是由于没涉及到量化,很少留意到这些细节,所以仔细解读一下efficientnet这个经典网络。
文章目录
- 1、算法概述
- 2、Efficientnet细节
- 2.1 单个维度模型缩放
- 2.2 混合缩放
- 2.3 Efficientnet结构
- 3、实验
- 3.1 Scaling up MobileNets and ResNets
- 3.2 Efficientnet在ImageNet上分类精度
- 3.3 Efficientnet在CPU上的延迟
- 3.4 Efficientnet的迁移学习能力
1、算法概述
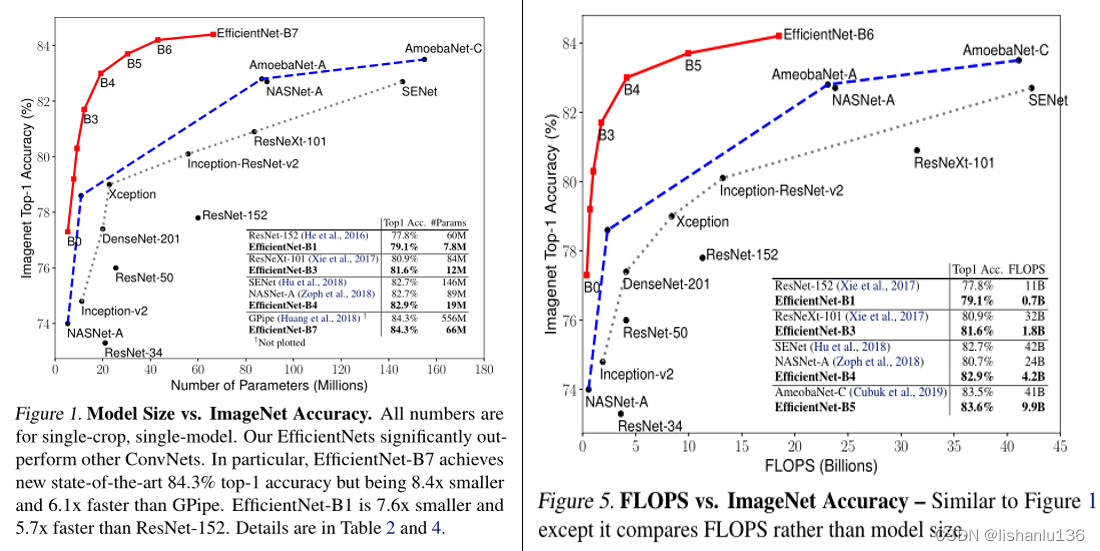
Efficientnet是谷歌针对于模型缩放相关的探索提出的分类网络;在这之前的卷积神经网络(ConvNets)通常是在固定受限的资源下开发的,如果有更多的资源可用,则可以根据扩展以获得更好的准确性。该篇论文通过仔细平衡网络深度,宽度和分辨率之间的关系来获得更好的性能,并且在MobileNet和ResNet上验证了其有效性。论文作者通过神经架构搜索获得一个baseline模型(Efficientnet-B0),然后通过论文所提的模型缩放技术获得一系列缩放模型。这一系列模型在ImageNet分类数据集上的精度和参数量都比现如今最先进的卷积网络有了不小的提升。如下图,左图是精度和模型大小,右图是精度和flops。
2、Efficientnet细节
在这之前也有模型缩放相关的研究,例如将网络放大可以得到更好的性能,比如Resnet系列,通常来说Resnet200比Resnet18得到的分类精度好得多;但是之前的模型缩放通常只缩放三个维度(深度、宽度和图像大小)中的一个。虽然可以任意缩放两个或三个维度,但任意缩放需要繁琐的手动调优,并且仍然经常产生次优的精度和效率。虽然更大的网络能带来更高的精度,但是我们时常受到硬件内存限制,所以需要探索更高效的网络结构;如今“高效”网络结构有:SqueezeNets、MobileNets、ShuffleNets以及通过神经网络搜索得到的NASNet,但这些高效网络设计技巧目前尚不清楚如何推广应用到大规模网络。
本论文通过实验验证得到结论:平衡模型缩放过程中的深度、宽度和分辨率是非常重要的,而且只是简单的通过模型缩放公式就可以得到它们之间的关系。关于网络宽度缩放、深度缩放、和输入图像分辨率缩放及综合缩放的示例图如下图所示:
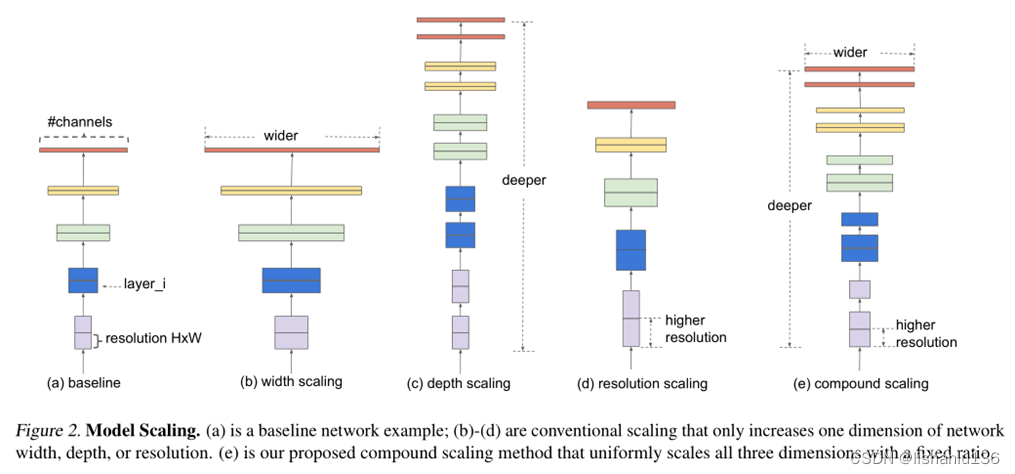
2.1 单个维度模型缩放
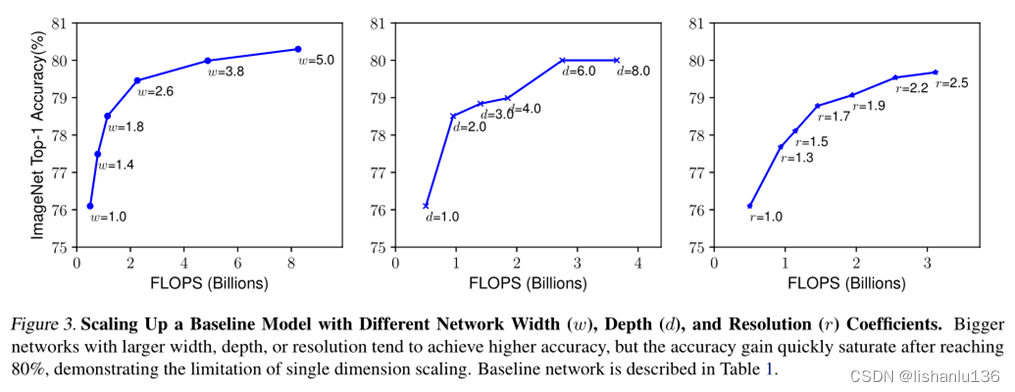
网络深度用d表示,直觉上更深的卷积神经网络可以捕获更丰富、更复杂的特征,并能很好地泛化新任务。然而,由于梯度的消失,更深的网络也更难以训练;虽然现在的跳转连接(skip connection)和batch normalization技术一定程度上缓和了梯度消失问题,但是随着深度增加,精度提升的收益还是会递减,如下图(中);
网络宽度用w表示,缩放网络宽度通常用于小尺度网络结构,通道数“更宽”的网络往往能够捕获更细粒度的特征,并且更容易训练;极宽但较浅的网络往往难以捕捉更高级的特征。而且当网络变得更宽即w更大时,准确性很快会饱和,如下图(左)所示;
网络输入分辨率用r表示,网络接收更高的分辨率,可以捕获更细粒度的特征。但随着分辨率不断提高,其精度收益率也会递减最终达到饱和。如下图(右)所示;
2.2 混合缩放
作者通过实验得出:对于更高分辨率的图像,我们应该增加网络深度,这样有利用在更大图像上用更大的感知域捕获更多像素的特征。相应的也应该同时增加网络宽度,以便于在高分辨率图像中捕获更多像素的更细粒度的特征。如下图所示:
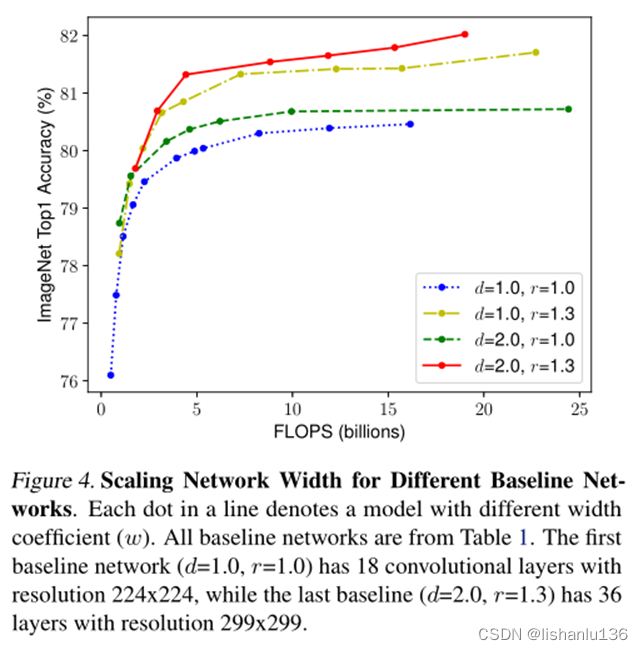
所以我们需要协调和平衡不同的缩放维度,而不是传统的单一维度缩放。
作者通过以下公式设置三个维度的限制,利用网络结构搜索搜出最佳的d,w,r匹配。

2.3 Efficientnet结构
和设计MnasNet一样,作者也是通过网络搜索得到最佳的基线模型efficientnet-B0,与它不同的是设置的搜索最优目标不一样,efficientnet-B0是以最佳flops为目标,而前者是最小推理速度。搜出来的efficientnet-B0结构与MnasNet结构相似,主要组成部分为mobile inverted bottleneck MBConv,其结构如下表所示:
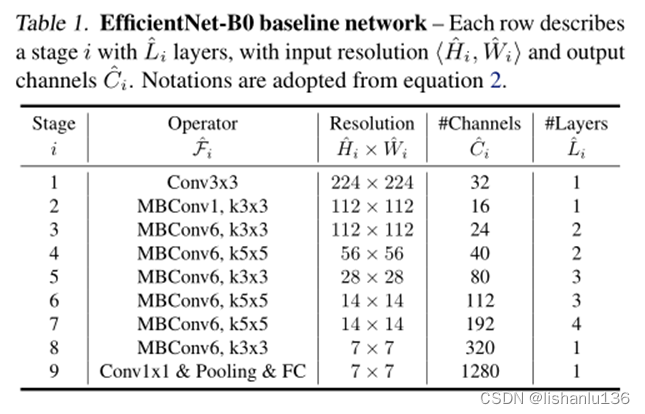
得到efficientnet-B0后,应用本文所提的模型缩放技术,分以下两步得到B1至B7。

论文中说,也可以直接通过网络搜索得到更大规模的网络结构,但这样做太耗费资源,作者提出的规则模型缩放技术,可以通过先搜索小规模网络结构,然后通过模型缩放得到一系列更大规模的网络结构,这样做解决了这个难题。
3、实验
3.1 Scaling up MobileNets and ResNets
作者首先在已有的分类算法网络结构上验证提出的模型缩放方法,评估其在ImageNet上的Top-1及Top-5准确率,实验结果如下:
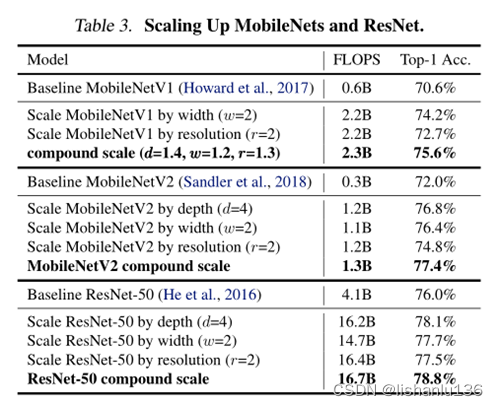
从实验结果可以看出,相对于Baseline模型,单纯扩充w、d或者r,模型的Top-1准确率是有一定提升的,但相对于采用本论文所提的组合扩充方式,组合扩充方式还是有精度方面的优势。
3.2 Efficientnet在ImageNet上分类精度
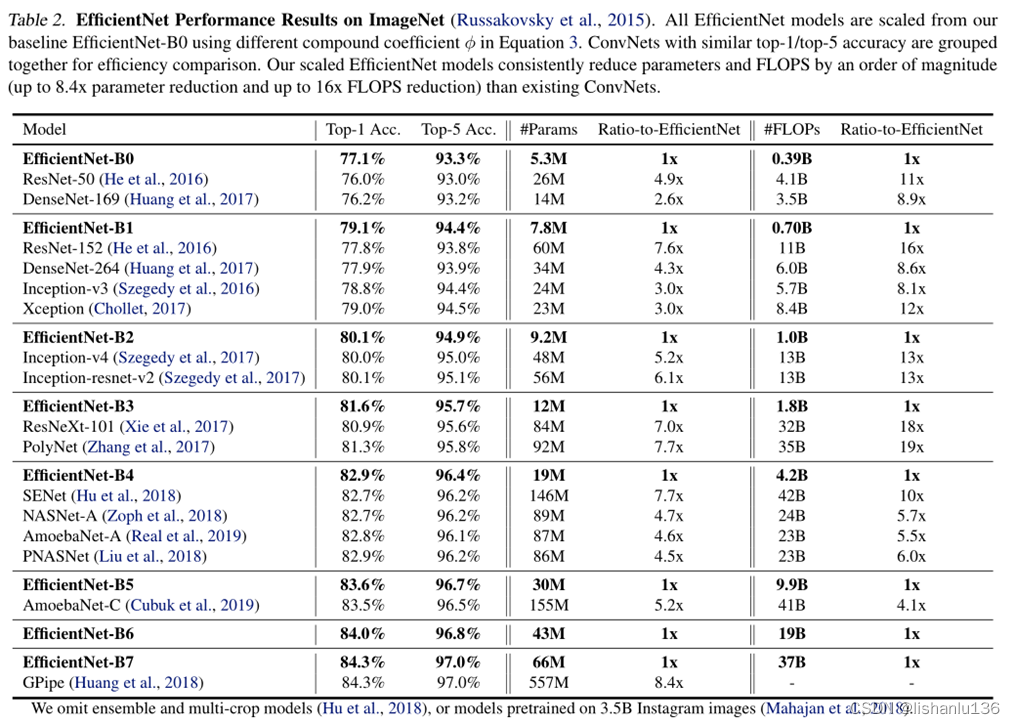
3.3 Efficientnet在CPU上的延迟

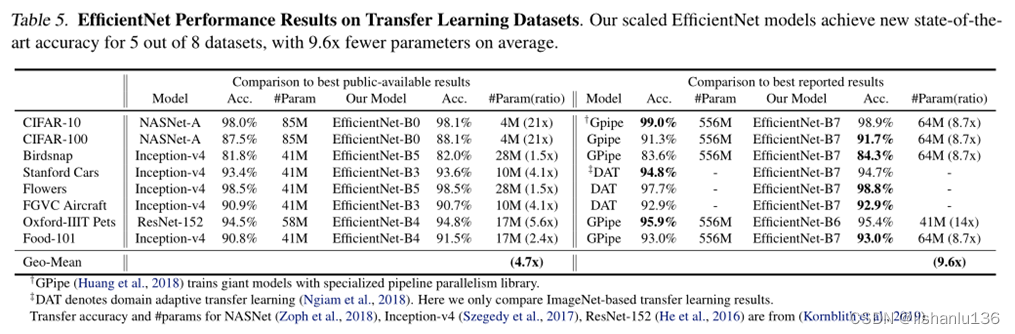
3.4 Efficientnet的迁移学习能力
这篇关于经典网络解读——Efficientnet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







