本文主要是介绍shard,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一个MongoDB Sharding由三部分组成:
1. Shards
Shard即存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replica Set。为了实现每个Shard内部的auto-failover,MongoDB官方建议每个Shard为一组Replica Set。
2. Config Servers
为了将一个collection拆分为多个chunk,存储在多个shard中,需要为该collection指定一个shard key. 例如{name: 1}, {_id: 1}, {lastname:1, firstname:1}等。shard key决定了该条记录属于哪个chunk,例如当1 < shard key < 100时为一个chunk,该chunk保存在shard1上。而Config Servers就是用来存储:所有shard节点的配置信息;每个chunk的shard key范围;chunk在各shard的分布;该集群中所有DB和collection的sharding配置。
3. Routing Process
MongoDB的二进制包中有一个mongos程序,它是用来做为MongoDB集群的Routing Process的。它相当于一个透明代理,接收来自客户端的查询或更新请求,然后询问Config Servers需要到哪个Shard上查询或保存记录,再连接相应的Shard进行操作,最后将结果返回给客户端。客户端只需要将原本发给mongod的查询或更新请求原封不动地发给Routing Process,而不必关心所操作的记录存储在哪个Shard上。
、 什么是shard
副本集实现了网站的安全备份和故障的无缝转移,但是并不能实现数据的大容量存储,MongoDB实现的是分布式部署,把数据保存到其他机器上。实现这一过程的就是分片。
2、 什么时候需要分片
a) 用光了当前机器的磁盘空间
b) 单个的Mongod已经无法提供你要的写入性能了
c) 需要把大部分数据驻留在内存中籍此来提供更好的性能
3、 分片需要的三个部分
a) shard服务器(Shard Server)。Shard服务器是存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replica Sets。MongoDB官方建议每个Shard为一组Replica Sets(结合了Master/Slave模式与自动数据容错、自动恢复的综合体,结构如下图)。

b) 配置服务器(Config Server)。它存储了所有Shard节点的配置信息,每个chunk的Shard key范围,chunk在各Shard的分布情况以及集群中所有DB和collection的Shard配置信息。
c) 路由进程(Route Process)。一个前端路由,客户端由此接入,首先询问配置服务器需要到那个Shard上查询或保存记录,然后连接相应Shard执行操作,最后将结果返回客户端。(类似于网络中路由器的功能)
4、 未分片和分片Client反问mongod 的区别如下图。
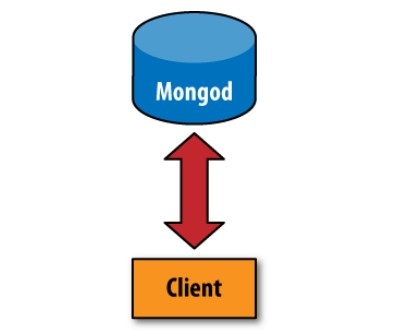

未分片客户端的连接 分片后客户端的连接
5、 Shard Keys
MongoDB主要根据Shard Keys来划分数据,Shard Keys可以由文档的一个或者多个物理键值组成,对于分片Key的选定直接决定了集群中数据分布是否均衡、集群性能是否合理。
配置命令(参考《MongoDB:The Definiive Guide》,以及官网上的《MongoDB Manual》, http://docs.mongodb.org/manual/MongoDB-Manual.pdf)
一. 整体架构
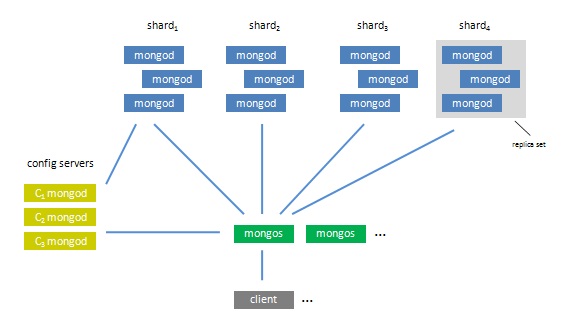
说明:
1. 由于config servers非常重要,建议使用3个config servers,但是可以只是用一个config servers。
2. 一个较好的Auto Sharding解决方案是将每个一shard(分片)定为一个Replica Sets(复制集)。一个Replica Sets由若干个mongod instance组成,在这个集合中,所有的instance的数据相同,这使得即使有某一台机子当掉了,其它机子还是可以正常运行,而且这部分的控制是由Mongo自动完成的,因而尽可能地减少了因当机而产生的错误及人工处理的部分。而Sharding是可以将庞大的数据库拆分为几个部分分别发放到每一个shard,一来降低了单一一台服务器的压力,同时通过减少潜在的损失比例来提高效率。也就是说一个基于Replica Sets的Auto Sharding结构,可以把一个完整而且庞大的数据库根据个人定制,拆分到若干个服务器集合,每个服务器集合中的服务器群又相互保持数据同步,所以除非一个服务器集合中的所有服务器都当掉了,否则某台或几台的当机对数据库的影响是微忽其微的。
3. 一个完整的Auto Sharding功能的实现需要用到mongod和mongos,其中mongos作为真正的应用接口,数据的输入输出都应经过它。然后还需要一个或多个config server(建议是三个),它是mongod,但它不会用来存储应用程序的数据库,通俗的来说而是存放了这整个结构的配置属性,mongos会从config server中读取配置来进行工作。最后是真正会存储数据的mongod们,它们按组分为若干个Replica Sets,用来存放mongos拆分下来的各个sharding。
4. Config服务器存储着集群的metadata信息,包括每个服务器,每个shard的基本信息和chunk(后面介绍)信息Config服务器主要存储的是chunk信息。每一个config服务器都复制了完整的chunk信息。
这篇关于shard的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


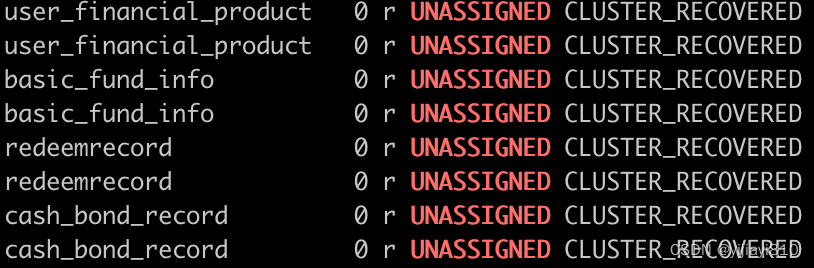
![No shard available for [get [service_name][type][-87]: routing [null]]解决方案](https://img-blog.csdn.net/20180809102309338?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTE4NzAyODA=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)