本文主要是介绍轻松扩展你的机器学习能力 : Kubeflow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提起机器学习,尤其是深度学习,大家可能会对诸如Tensorflow,Pytorch,Caffee的工具耳熟能详。但其实在实际的机器学习的生命周期中,训练模型(上述工具主要解决的问题)只是整个机器学习生命周期的很小一部分。

数据如何准备?模型训练好了如何部署?如何上云?如何上规模Scale?等等挑战随之而来。随着机器学习的广泛应用,许多工具响应而生,以解决模型部署的问题。例如:
- Oracle 的 graphpipe
- Databricks 的 mlflow
- Google的 kubeflow
我们今天就来看一看Google推出的Kubeflow。Kubeflow,顾名思义,是Kubernetes + Tensorflow,是Google为了支持自家的Tensorflow的部署而开发出的开源平台,当然它同时也支持Pytorch和基于Python的SKlearn等其它机器学习的引擎。与其它的产品相比较,因为是基于强大的Kubernetes之上构建,Kubeflow的未来和生态系统更值得看好。

Kukeflow主要提供在生产系统中简单的大规模部署机器学习的模型的功能,利用Kubernetes,它可以做到:
- 简单,可重复,可移植的部署
- 利用微服务提供松耦合的部署和管理
- 按需扩大规模
Kubeflow是基于K8S的机器学习工具集,它提供一系列的脚本和配置,来管理K8S的组件。Kubeflow基于K8s的微服务架构,其核心组件包括:
- Jupyterhub 多租户Nootbook服务
- Tensorflow/Pytorch/MPI/MXnet/Chainer 主要的机器学习引擎
- Seldon 提供在K8s上对于机器学习模型的部署
- Argo 基于K8s的工作流引擎
- Ambassador API Gateway
- Istio 提供微服务的管理,Telemetry收集
- Ksonnet K8s部署工具
基于K8s,扩展其它能力非常方便,Kubeflow提供的其它扩展包括:
- Pachyderm 基于容器和K8s的数据流水线 (git for data)
- Weaveworks flux 基于git的配置管理
- ... ...
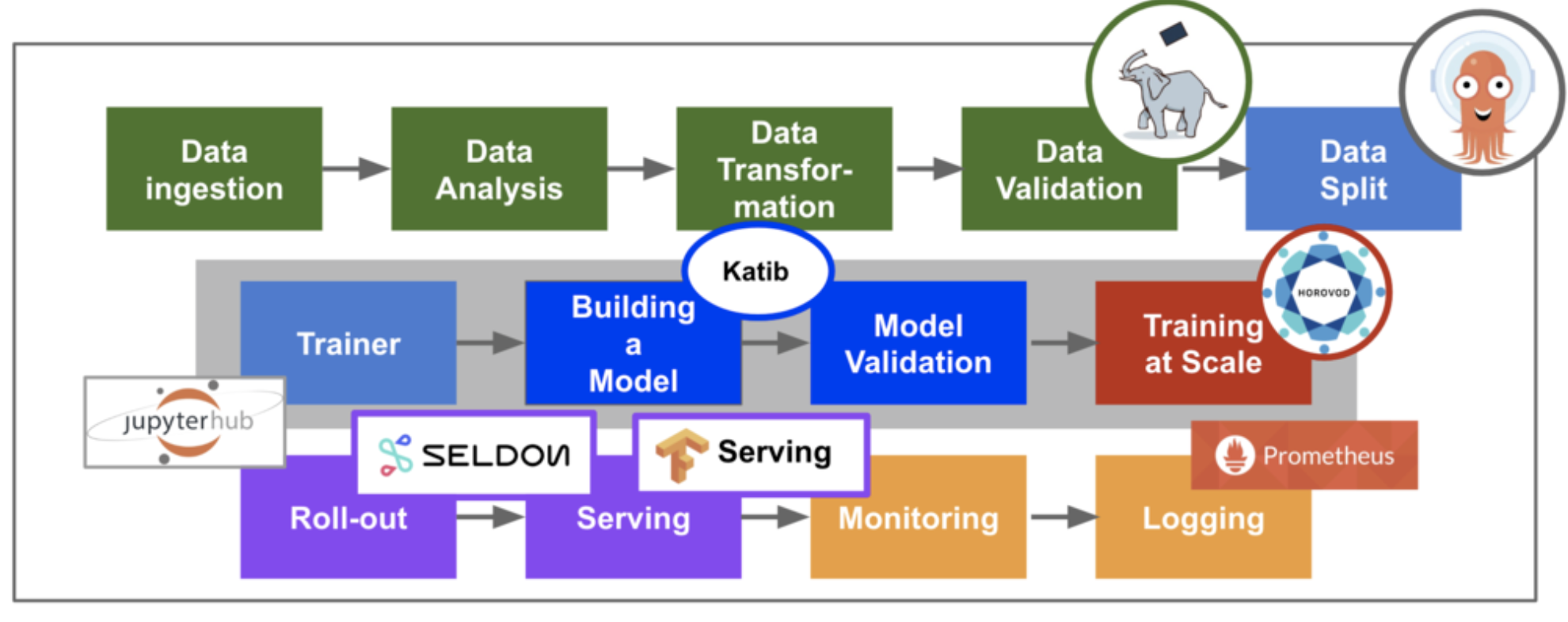
我们可以看出,基于K8s,Kubeflow利用已有的生态系统来构微服务,可以说充分体现了微服务的高度扩展性。
我们下面就来看看Kubeflow是如何整合了这些组件,来提供机器学习模型部署的功能的。
JupyterHub
Jupyter Notebook是深受数据科学家喜爱的开发工具,它提供出色的交互和实时反馈。JupyterHub提供一个使用Juypter Notebook的多用户使用环境,它包含以下组件:
- 多用户Hub
- 可配置的HTTP代理
- 多个但用户Notebook server
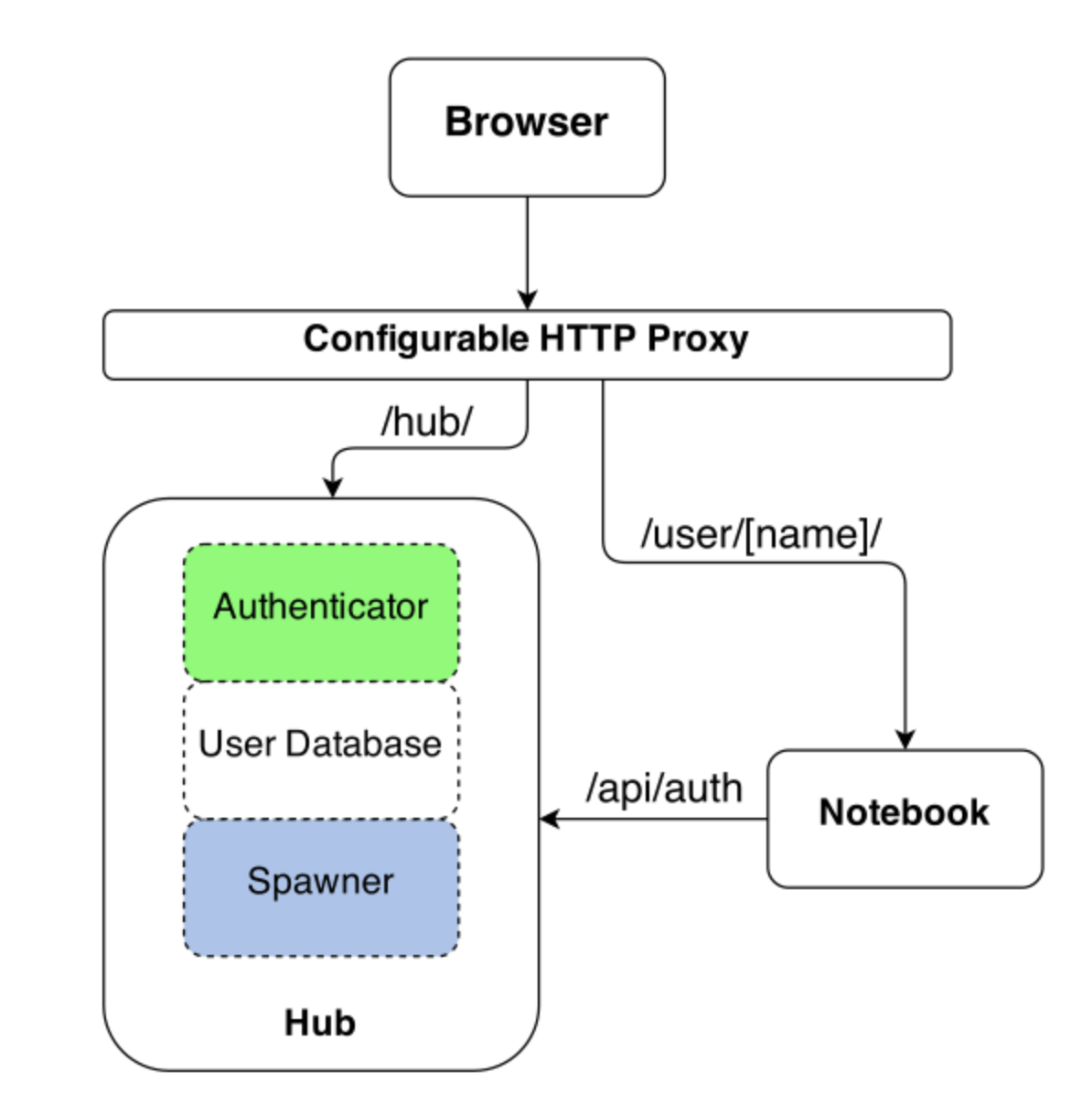
运行以下的命令通过port-forward访问jyputer hub
kubectl port-forward tf-hub-0 8000:8000 -n <ns>第一次访问,可以创建一个notebook的实例。创建的实例可以选择不同的镜像,可以实现对GPU的支持。同时需要选择配置资源的参数。
创建好的jupyterlab (JupyterLab是新一代的Juypter Notebook)的界面如下:
不过我还是比较习惯传统的notebook界面。Lab的优点是可以开Console,这个不错。(Lab也支持打开传统的notebook界面)
Kubeflow在notebook镜像中集成了Tensorboard,可以方便的对tensflow的程序进行可视化和调试。
在jyputerlab的Console中,输入下面的命令开启Tensorboard:
tensorboard --logdir <logdir>$ tensorboard --logdir /tmp/logs
2018-09-15 20:30:21.186275: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
W0915 20:30:21.204606 Reloader tf_logging.py:121] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event.
W0915 20:30:21.204929 Reloader tf_logging.py:121] Found more than one metagraph event per run. Overwriting the metagraph with the newest event.
W0915 20:30:21.205569 Reloader tf_logging.py:121] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event.
TensorBoard 1.8.0 at http://jupyter-admin:6006 (Press CTRL+C to quit)访问tensorboard也需要port-forward,这里user是创建notebook的用户名,kubeflow为为一个实例创建一个Pod。缺省的tensorboard的端口是6006。
kubectl port-forward jupyter-<user> 6006:6006 -n <ns>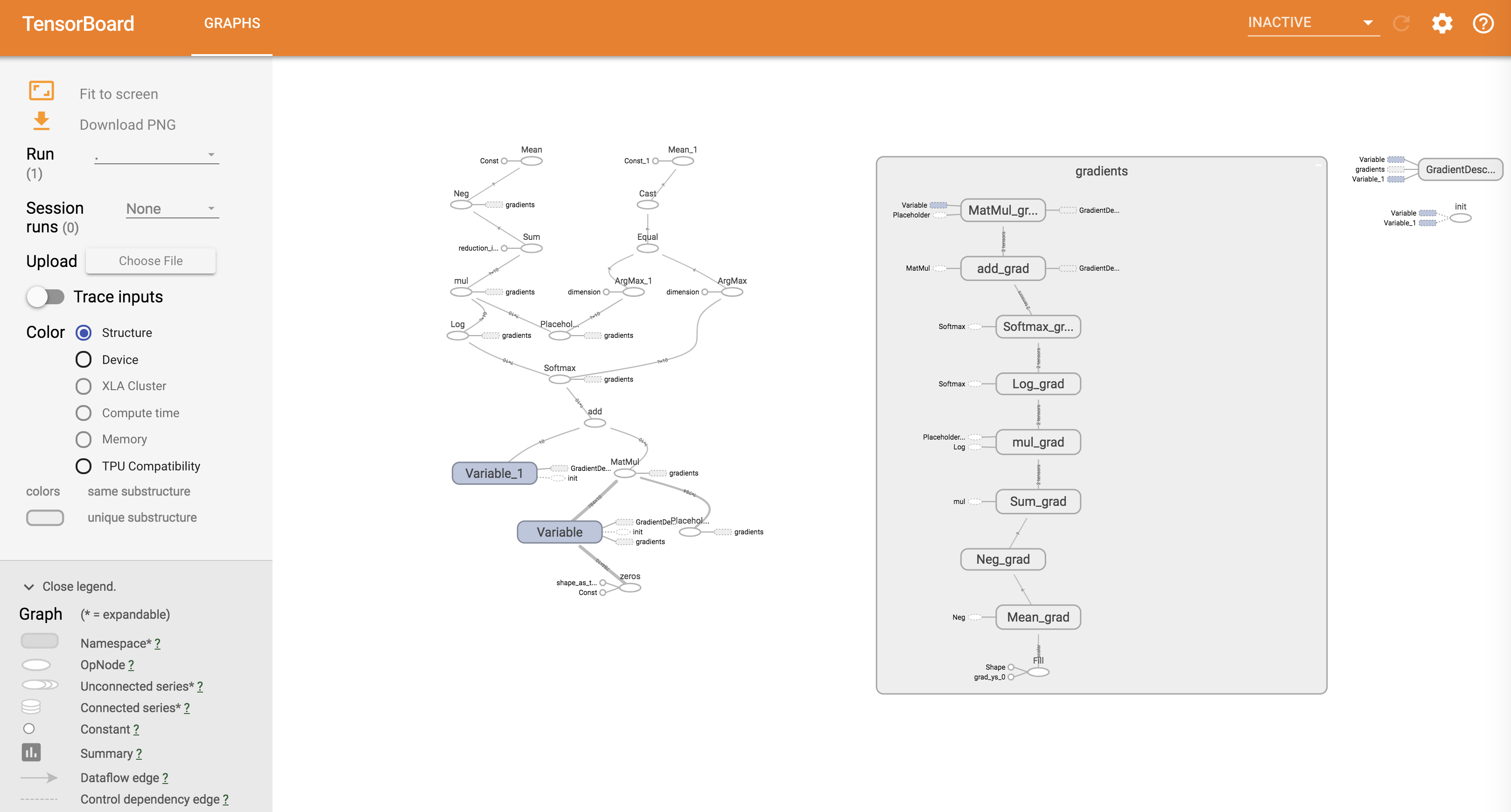
Tensorflow 训练
为了支持在Kubernete中进行分布式的Tensorflow的训练,Kubeflow开发了K8s的CDR,TFJob (tf-operater)。

如上图所示,分布式的Tensorflow支持0到多个以下的进程:
- Chief 负责协调训练任务
- Ps Parameter servers,参数服务器,为模型提供分布式的数据存储
- Worker 负责实际训练模型的任务. 在某些情况下 worker 0 可以充当Chief的责任.
- Evaluator 负责在训练过程中进行性能评估
下面的yaml配置是Kubeflow提供的一个CNN Benchmarks的例子。
---
apiVersion: kubeflow.org/v1alpha2
kind: TFJob
metadata:labels:ksonnet.io/component: mycnnjobname: mycnnjobnamespace: kubeflow
spec:tfReplicaSpecs:Ps:template:spec:containers:- args:- python- tf_cnn_benchmarks.py- --batch_size=32- --model=resnet50- --variable_update=parameter_server- --flush_stdout=true- --num_gpus=1- --local_parameter_device=cpu- --device=cpu- --data_format=NHWCimage: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3name: tensorflowworkingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarksrestartPolicy: OnFailuretfReplicaType: PSWorker:replicas: 1template:spec:containers:- args:- python- tf_cnn_benchmarks.py- --batch_size=32- --model=resnet50- --variable_update=parameter_server- --flush_stdout=true- --num_gpus=1- --local_parameter_device=cpu- --device=cpu- --data_format=NHWCimage: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3name: tensorflowworkingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarksrestartPolicy: OnFailure在Kubeflow中运行这个例子,会创建一个TFjob。可以使用Kubectl来管理,监控这个Job的运行。
# 监控当前状态
kubectl get -o yaml tfjobs <jobname> -n <ns># 查看事件
kubectl describe tfjobs <jobname> -n <ns># 查看运行日志
kubectl logs mycnnjob-[ps|worker]-0 -n <ns>Tensoflow 服务(Serving)
Serving就是指当模型训练好了以后,提供一个稳定的接口,供用户调用,来应用该模型。
基于Tensorflow的Serving功能,Kubeflow提供一个Tensorflow模型服务器(model server)的Ksonnet模块来提供模型服务的功能。
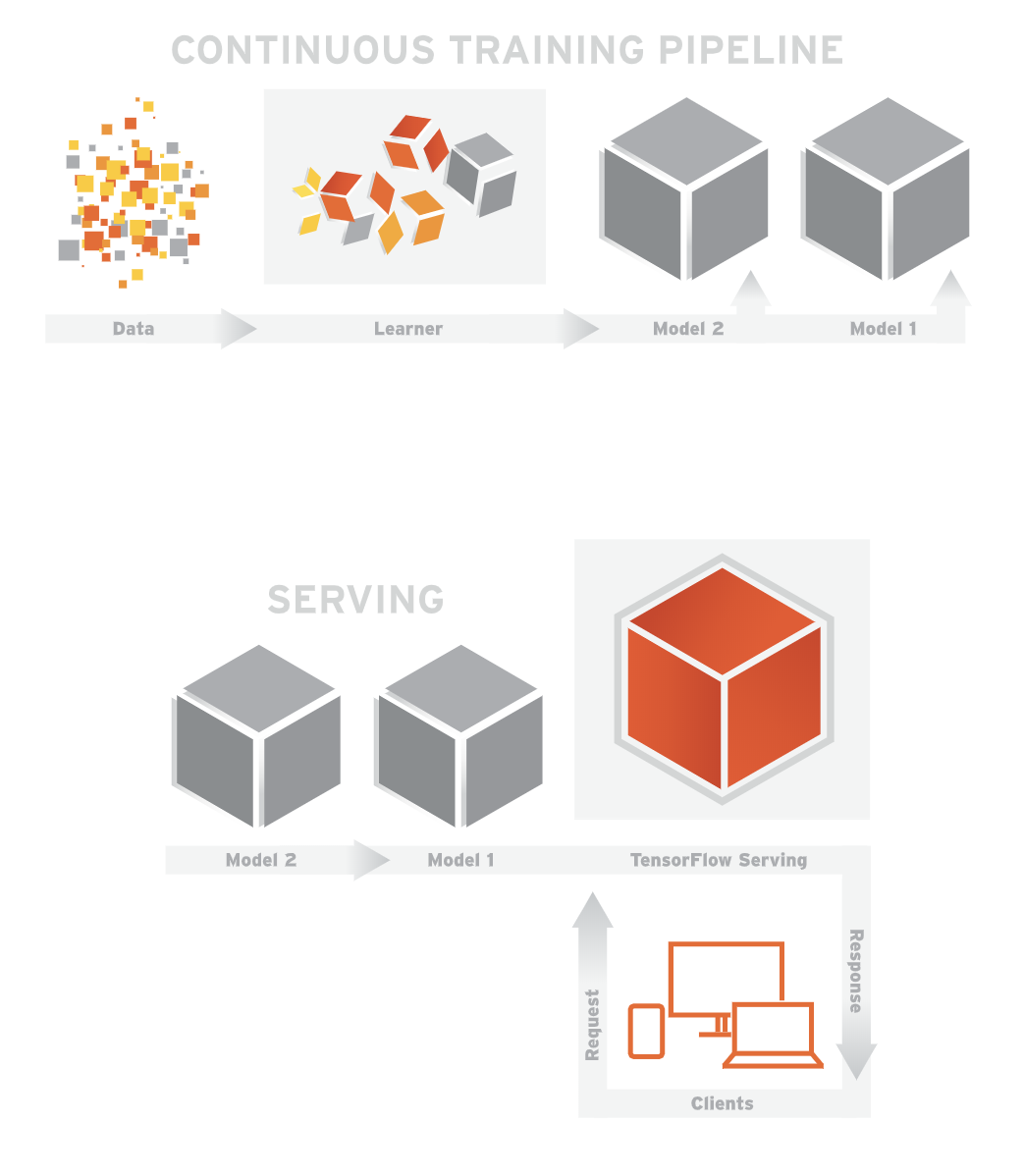
Kukeflow支持使用S3,Google Cloud或者NFS来存贮模型。并支持利用Istio来收集Telemetry。
其它机器学习引擎的支持
虽说Tensorflow是自家的机器学习引擎,但是Google的Kubeflow也提供了对其它不同引擎的支持,包含:
- Pytorch PyTorch是由Facebook的人工智能研究小组开发,基于Torch的开源Python机器学习库。
- MXnet Apache MXNet是一个现代化的开源深度学习软件框架,用于训练和部署深度神经网络。它具有可扩展性,允许快速模型培训,并支持灵活的编程模型和多种编程语言 MXNet库是可移植的,可以扩展到多个GPU和多台机器。
- Chainer Chainer是一个开源深度学习框架,纯粹用Python编写,基于Numpy和CuPy Python库。 该项目由日本风险投资公司Preferred Networks与IBM,英特尔,微软和Nvidia合作开发。 Chainer因其早期采用“按运行定义”方案以及其在大规模系统上的性能而闻名。Kubeflow对Chainer的支持要到下一个版本。现在还在Beta。
- MPI 使用MPI来训练Tensorflow。这部分看到的资料比较少。
这些都是用Kubernetes CDRs的形式来支持的,用户只要利用KS创建对应的组件来管理就好了。
Seldon Serving
既然要支持不同的机器学习引擎,当然也不能只提供基于Tensforflow的模型服务,为了提供其它模型服务的能力,Kubeflow集成了Seldon。
Seldon Core是基于K8s的开源的机器学习模型部署平台。
机器学习部署面临许多挑战。 Seldon Core希望帮助应对这些挑战。它的高级目标是:
- 允许数据科学家使用任何机器学习工具包或编程语言创建模型。我们计划最初涵盖以下工具/语言:
- 基于Python的模型包括
- Tensorflow模型
- Sklearn模特
- Spark模型
- H2O模型
- R模型
- 基于Python的模型包括
- 在部署时通过REST和gRPC自动公开机器学习模型,以便轻松集成到需要预测的业务应用程序中。
- 允许将复杂的运行时推理图部署为微服务。这些图可以包括:
- 模型 - 可执行机器学习模型的运行时推理
- 路由器 - 将API请求路由到子图。示例:AB测试,多武装强盗。
- 组合器 - 结合子图的响应。示例:模型集合
- 变形器 - 转换请求或响应。示例:转换要素请求。
- 处理已部署模型的完整生命周期管理:
- 更新运行时图表,无需停机
- 缩放
- 监控
- 安全
除了提供单模型服务的功能,Seldon还支持AB测试,异常检测等等。
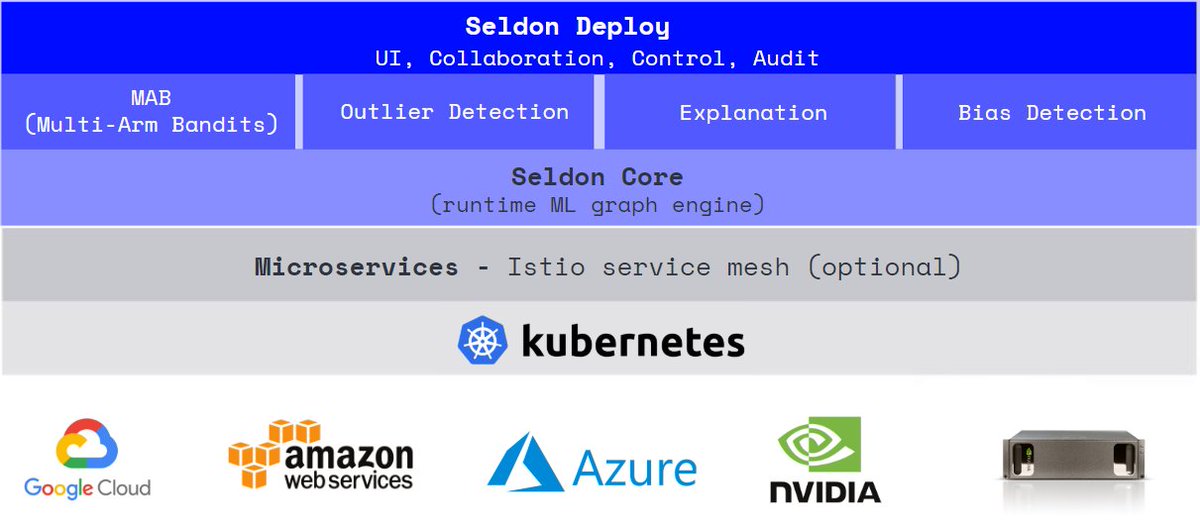
模型部署好了之后,通过API Gateway暴露的endpoint来访问和使用模型。
http://<ambassadorEndpoint>/seldon/<deploymentName>/api/v0.1/predictions
Argo
argo是一个开源的基于容器的工作流引擎,并实现为一个K8S的CRD。
- 用容器实现工作流的每一个步骤
- 用DAG的形式描述多个任务之间的关系的依赖
- 支持机器学习和数据处理中的计算密集型任务
- 无需复杂配置就可以在容器中运行CICD
用容器来实现工作流已经不是什么新鲜事了,codeship就是用容器来实现CICD的每一步。所以Argo很适合CICD。
下图就是一个Argo工作流的例子:
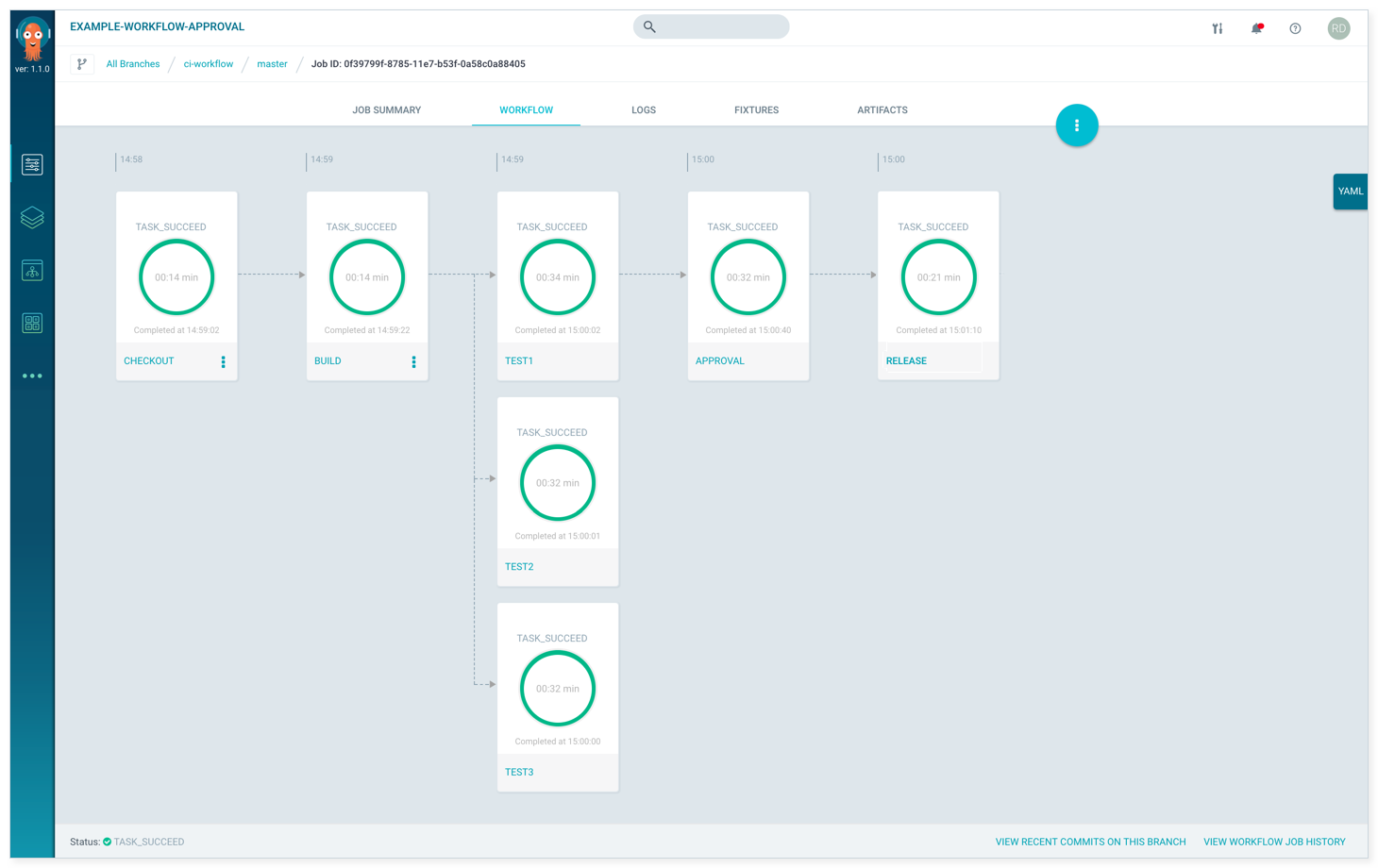
机器学习同样可以抽象为一个或者多个工作流。Kubeflow继承了Argo来作为其机器学习的工作流引擎。
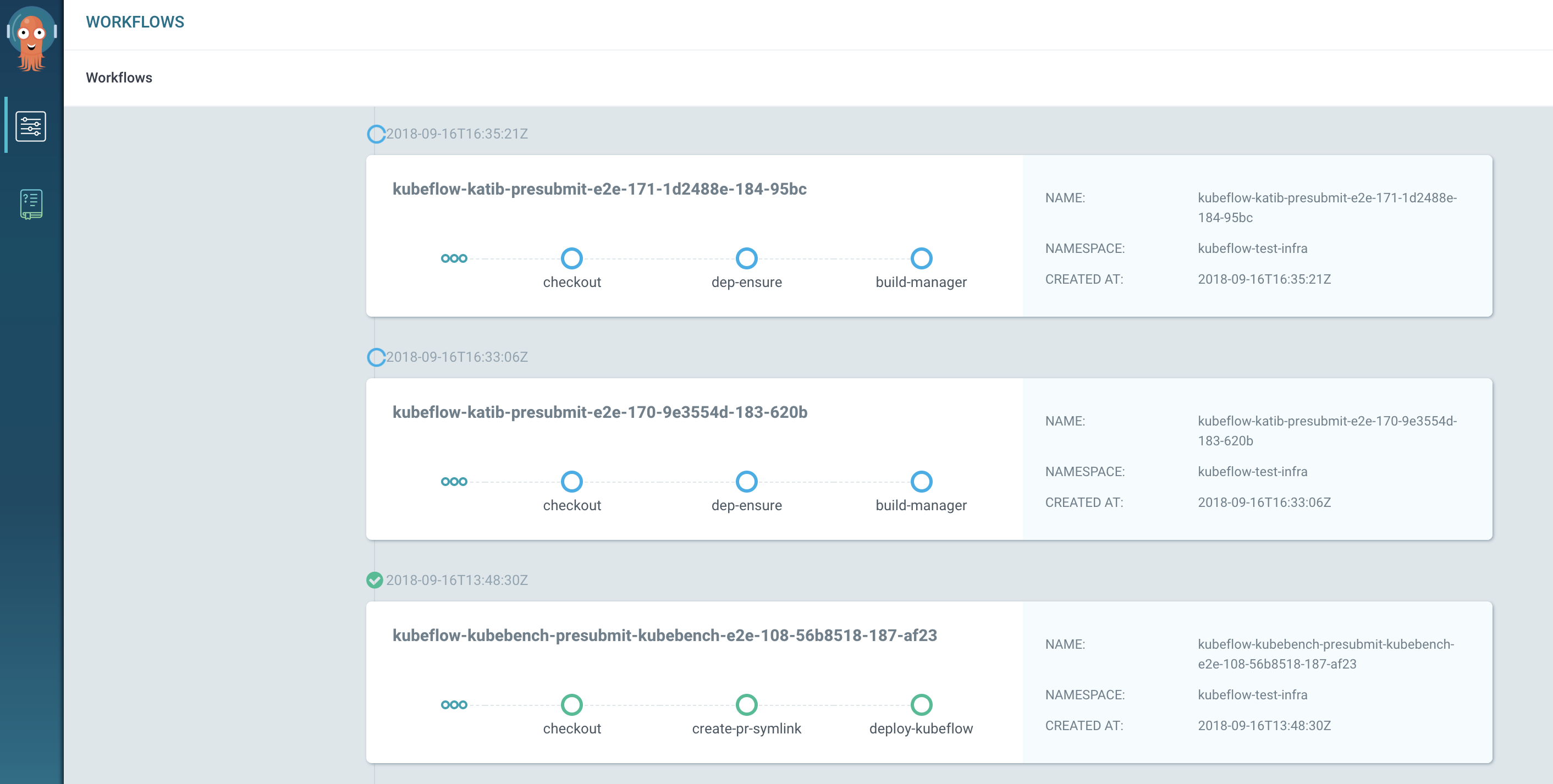
可以通过Kubectl proxy来访问Kubeflow中的Argo UI。 http://localhost:8001/api/v1/namespaces/kubeflow/services/argo-ui/proxy/workflows
现阶段,并没有实际的Argo工作流来运行机器学习的例子。但是Kubeflow在使用Argo来做自己的CICD系统。
Pachyderm

Pychyderm是容器化的数据池,提供像git一样的数据版本系统管理,并提供一个数据流水线,来构建你的数据科学项目。
总结
Kubeflow利用Google自家的两大利器Kubernete和Tensorflow,强强联手,来提供一个数据科学的工具箱和部署平台。我们可以看到他有很多优点:
- 云优化 - 基于K8s,可以说,所有功能都很容易的在云上扩展。诸如多租户功能,动态扩展,对AWS/GCP的支持等等
- 利用微服务架构,扩展性强,基于容器,加入心得组件非常容易
- 出色的DevOps和CICD支持,使用Ksonnet/argo,部署和管理组件和CICD都变得非常轻松
- 多核心支持,除了我们本文提到的深度学习引擎,Kubeflow很容易扩展新的引擎,例如Caffe2正在开发中。
- GPU支持
同时我们也可以看到Kubeflow的一些问题:
- 组件比较多,缺乏协调,更像是一推工具集合。希望能有一个整合流畅的工作流,能统一各个步骤。
- 文档还需改善
当然,kubeflow的当前版本是0.2.5,我相信,未来Kubeflow会有很好的发展。
这篇关于轻松扩展你的机器学习能力 : Kubeflow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




