本文主要是介绍C语言中关于 strlen 和 sizeof 的用法及区别(含例题及解析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
首先我们需要知道的是,sizeof既是一个单目操作符,也是一个关键字,其作用是求操作数的类型长度(以字节为单位)。

而strlen是一个字符串操作函数,是一个参数为指针类型返回值为size_t(unsigned int)的函数,求的是字符串的长度。
![]()

所以现在我们知道sizeof是一个求操作数类型长度的操作符(关键字),而strlen是一个求字符串长度的字符串操作函数 。
二、sizeof和strlen的用法
2.1 sizeof操作符在简单变量中的用法
int a = 10;
char c = 'c';printf("%d\n",sizeof(a)); //答案是4(操作数a的类型为整型,32位机器中占4个字节,64位机器中占8个字节)
printf("%d\n",sizeof(int)); //答案是4
printf("%d\n",sizeof a); //答案是4(求变量的大小时可以去掉括号)
printf("%d\n",sizeof int); //错误(求类型的大小时不能去掉括号)printf("%d\n",sizeof(c)); //答案是1(操作数c的类型为字符型,占1个字节)
printf("%d\n",sizeof(char)); //答案是1
printf("%d\n",sizeof c); //答案是1(求变量的大小时可以去掉括号)
printf("%d\n",sizeof char); //错误((求类型的大小时不能去掉括号))2.2 strlen函数在字符指针变量中的简单用法
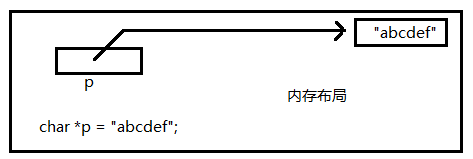
char *p = "abcdef";
printf("%d\n",strlen(p)); //答案是6我们知道strlen()函数的参数是一个指针变量,存放的是一个地址。而strlen()函数就是从这个地址开始往后数,直到遇到字符串结束标志'\0' ,停止计数('\0'不纳入计数范围),并返回字符串的长度。
在上面例子中,p是一个指针变量,存放的是字符串首元素'a'的地址。所以将p作为参数传给strlen()函数后,该函数从a开始计数,直到遇到'f'后边的'\0',停止计数,此时字符串长度为6。
2.3sizeof和strlen在数组中的用法
注意:
1.数组名单独放在sizeof内部时,此时数组名表示整个数组,sizeof求的是整个数组的大小。
2.&数组名,此时数组名也表示整个数组,取出的是整个数组的地址。
3.除上述两种情况外,数组名均表示首元素的地址。
一维整型数组中:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a)); //16
printf("%d\n",sizeof(a+0)); //4
printf("%d\n",sizeof(*a)); //4
printf("%d\n",sizeof(a+1)); //4
printf("%d\n",sizeof(a[1])); //4
printf("%d\n",sizeof(&a)); //4
printf("%d\n",sizeof(*&a)); //16
printf("%d\n",sizeof(&a+1)); //4
printf("%d\n",sizeof(&a[0])); //4
printf("%d\n",sizeof(&a[0]+1)); //4例1:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a)); //16解析:此时数组名a单独放在sizeof内部,表示整个数组,所以求的是整个数组的大小 = 4*4=16。
例2:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a+0)); //4解析:此时数组名并未单独放在sizeof内部,也没有取地址,所以表示首元素地址,+0后仍表示首元素地址。我们知道只要是地址,在32位机器下便占4个字节,在64位机器下便占8个字节。
例3:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(*a)); //4
解析:此时数组名a表示首元素地址,解引用(*)后表示首元素1,而1是一个整型,32位机器下占4个字节。
例4:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a+1)); //4解析:此时数组名表示首元素地址,首元素地址+1指向第2个元素,表第二个元素的地址。
例5:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a[1])); //4解析:a[1]表示第二个元素2(整型)。
例6:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(&a)); //4解析:&数组名取的是整个数组的地址(此时的数组名表示整个数组)。
例7:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(*&a)); //16解析:因为&a中,a表示整个数组,所以*&a,解引用a后计算的是整个数组的大小。
例8:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(&a+1)); //4解析:由于&a取出的是整个数组的地址,所以&a+1跳过的是整个数组,但仍表示一个地址。
例9:
int a[] = {1,2,3,4};
printf("%d\n", sizeof(&a[0])); //4解析:&a[0]取出的是首元素1的地址。
例10:
int a[] = {1,2,3,4};
printf("%d\n", sizeof(&a[0] + 1)); //4解析:&a[0]取出的是首元素1的地址,加1后指向第二个元素2,表第二个元素的地址。
字符数组中:
sizeof的用法:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(c)); //6
printf("%d\n",sizeof(c+0)); //4
printf("%d\n",sizeof(*c)); //1
printf("%d\n",sizeof(c[1])); //1
printf("%d\n",sizeof(&c)); //4
printf("%d\n",sizeof(&c+1)); //4
printf("%d\n",sizeof(&c[0]+1)); //4例1:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(c)); //6解析:此时数组名c单独放在sizeof内部,表整个数组,所以求的是整个数组的大小 。
例2:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(c+0)); //4解析:此时数组名并未单独放在sizeof内部,也没有取地址,所以此时的数组名表示首元素'a'的地址,加0后仍表示首元素的地址。
例3:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(*c)); //1解析:此时的数组名表示首元素的地址,解引用后表示首元素(字符型)。
例4:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(c[1])); //1解析:c[1]表示第二个元素'b'(字符型)。
例5:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(&c)); //4解析:&数组名取出的是整个数组的地址。
例6:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(&c+1)); //4解析:&数组名取出的是整个数组的地址,&数组名+1跳过整个数组。
例7:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",sizeof(&c[0]+1)); //4解析:&c[0]取的是首元素的地址,加1后表第二个元素的地址。
strlen()的用法:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(c)); //随机值
printf("%d\n",strlen(c+0)); //随机值
printf("%d\n",strlen(*c)); //错误
printf("%d\n",strlen(c[1])); //错误
printf("%d\n",strlen(&c)); //随机值
printf("%d\n",strlen(&c+1)); //随机值
printf("%d\n",strlen(&c[0]+1)); //随机值例1:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(c)); //随机值解析:由于strlen()函数求的是字符串长度,而字符串又是以'\0'作为字符串结束标志 。此时的数组中并无'\0'元素,所以当strlen()函数从'a'开始往后数,遇到'\0'停下来的时候我们并不知道确切的字符串长度。
例2:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(c+0)); //随机值解析:给首元素地址加0后仍从首元素开始往后数,此时仍不知道何时会遇到'\0'并停止计数。
例3:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(*c)); //错误解析:在文章最开始时我们就已经知道strlen()函数需要的参数是一个指针类型,而*c表示的是首元素,并不是一个地址,强行调用会引发程序中断。
例4:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(c[1])); //错误解析:此时c[1]也不是指针类型,而是字符型。
例5:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(&c)); //随机值解析:当取得了整个数组的地址后,strlen()函数从该地址开始往后数,由于不知道什么时候会遇到'\0',所以此字符串长度仍为随机值。
例6:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(&c+1)); //随机值解析:给整个数组的地址加1跳过的是整个数组,即从元素'f'后边开始计数,且字符串长度仍为随机值。但我们可以确定的是strlen(&c) 和 strlen(&c+1)相差的是整个数组的大小6。
例7:
char c[] = {'a','b','c','d','e','f'};
printf("%d\n",strlen(&c[0]+1)); //随机值解析:首元素地址加1表第二个元素的地址,此时函数从'b'处往后数,直到遇到'\0'停止计数。
sizeof的用法:
char c[] = "abcdef";
printf("%d\n",sizeof(c)); //7
printf("%d\n",sizeof(c+0)); //4
printf("%d\n",sizeof(*c)); //1
printf("%d\n",sizeof(c[1])); //1
printf("%d\n",sizeof(&c)); //4
printf("%d\n",sizeof(&c+1)); //4
printf("%d\n",sizeof(&c[0]+1)); //4例1:
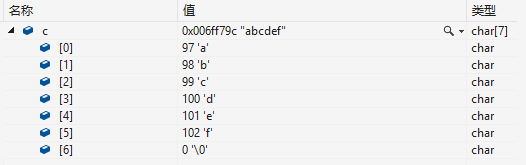
char c[] = "abcdef";
printf("%d\n",sizeof(c)); //7解析:通过调试并监视c,我们发现此时由于数组是一个字符串,所以会将'\0'存入该数组中,计算字符串长度时,由于'\0'也是数组的一个元素,所以最后字符串长度为7而不是6。
例2:
char c[] = "abcdef";
printf("%d\n",sizeof(c+0)); //4解析:首元素地址加0仍表示首元素地址。
例3:
char c[] = "abcdef";
printf("%d\n",sizeof(*c)); //1解析:此时数组名表示首元素地址,解引用后表示首元素(字符型)。
例4:
char c[] = "abcdef";
printf("%d\n",sizeof(c[1])); //1解析:c[1]表示第二个元素(字符型)。
例5:
char c[] = "abcdef";
printf("%d\n",sizeof(&c)); //4解析:&数组名取的是整个数组的地址。
例6:
char c[] = "abcdef";
printf("%d\n",sizeof(&c+1)); //4解析:&数组名+1跳过整个数组。
例7:
char c[] = "abcdef";
printf("%d\n",sizeof(&c[0]+1)); //4解析:首元素地址加1指向第二个元素,表第二个元素的地址。
strlen的用法:
char c[] = "abcdef";
printf("%d\n",strlen(c)); //6
printf("%d\n",strlen(c+0)); //6
printf("%d\n",strlen(*c)); //错误
printf("%d\n",strlen(c[1])); //错误
printf("%d\n",strlen(&c)); //6
printf("%d\n",strlen(&c+1)); //随机值
printf("%d\n",strlen(&c[0]+1)); //5例1:
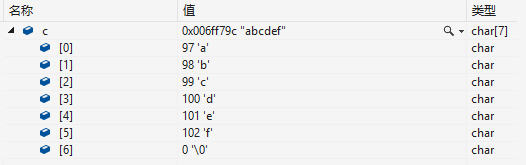
char c[] = "abcdef";
printf("%d\n",strlen(c)); //6解析:此时c在内存中的存储形式如下。由于字符串计算长度时不将'\0'计算在内,所以此字符串长度为6。
例2:
char c[] = "abcdef";
printf("%d\n",strlen(c+0)); //6解析:首元素地址加0仍从首元素开始往后数,不将'\0'纳入长度计算范围内。
例3:
char c[] = "abcdef";
printf("%d\n",strlen(*c)); //错误解析:所传参数*c是字符型而不是指针类型。
例4:
char c[] = "abcdef";
printf("%d\n",strlen(c[1])); //错误解析:所传参数c[1]是字符型而不是指针类型。
例5:
char c[] = "abcdef";
printf("%d\n",strlen(&c)); //6解析:&数组名取的是整个数组的地址,该地址在数值上跟首元素地址一样,所以也从字符串首元素开始往后数。
例6:
char c[] = "abcdef";
printf("%d\n",strlen(&c+1)); //随机数解析:&数组名加1后跳过整个数组,从该数组的'\0'后面开始往后数。
例7:
char c[] = "abcdef";
printf("%d\n",strlen(&c[0]+1)); //5解析:&c[0]加1表示从第二个元素开始往后数。
sizeof的用法:
char *p = "abcdef";
printf("%d\n",sizeof(p)); //4
printf("%d\n",sizeof(p+1)); //4
printf("%d\n",sizeof(*p)); //1
printf("%d\n",sizeof(p[0])); //1
printf("%d\n",sizeof(&p)); //4
printf("%d\n",sizeof(&p+1)); //4
printf("%d\n",sizeof(&p[0]+1)); //4例1:
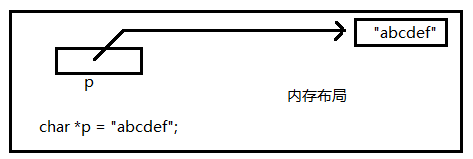
char *p = "abcdef";
printf("%d\n",sizeof(p)); //4解析:此时p指向字符串所在空间,所以p是一个指针变量,存的是该字符串首元素的地址。
例2:
char *p = "abcdef";
printf("%d\n",sizeof(p+1)); //4解析:给p加1后,指向第二个元素,表第二个元素的地址。
例3:
char *p = "abcdef";
printf("%d\n",sizeof(*p)); //1解析:因为p指向首元素,所以解引用后*p='a'(字符型)。
例4:
char *p = "abcdef";
printf("%d\n",sizeof(p[0])); //1解析:p[0]表首元素(字符型)。
例5:
char *p = "abcdef";
printf("%d\n",sizeof(&p)); //4解析:&p表示将存有字符串首元素地址的变量p的地址取出来,此时的指针变量char **pp = &p(第二颗*表示pp是一个指针变量,char *表示pp变量所存地址的类型)。
例6:
char *p = "abcdef";
printf("%d\n",sizeof(&p+1)); //4解析:char **pp = &p ,所以&p+1相当于跳过一个char *型的字节,即4个字节。
例7:
char *p = "abcdef";
printf("%d\n",sizeof(&p[0]+1)); //4解析:&p[0]取出的是首元素的地址,加1表示第二个元素的地址。
strlen的用法:
char *p = "abcdef";
printf("%d\n",strlen(p)); //6
printf("%d\n",strlen(p+1)); //5
printf("%d\n",strlen(*p)); //错误
printf("%d\n",strlen(p[0])); //错误
printf("%d\n",strlen(&p)); //随机值
printf("%d\n",strlen(&p+1)); //随机值
printf("%d\n",strlen(&p[0]+1)); //5例1:
char *p = "abcdef";
printf("%d\n",strlen(p)); //6解析:从首元素'a'开始往后数,遇到'f'后面的'\0'停止计数。
例2:
char *p = "abcdef";
printf("%d\n",strlen(p+1)); //5解析:从第二个元素开始往后数。
例3:
char *p = "abcdef";
printf("%d\n",strlen(*p)); //错误解析:strlen()函数要求所传参数必须为指针类型。
例4:
char *p = "abcdef";
printf("%d\n",strlen(p[0])); //错误解析:strlen()函数要求所传参数必须为指针类型。
例5:
char *p = "abcdef";
printf("%d\n",strlen(&p)); //随机数解析:由于p是一个指针变量,从该变量的地址开始往后数计算字符串长度。
例6:
char *p = "abcdef";
printf("%d\n",strlen(&p+1)); //随机值解析:char **pp = &p ,所以&p+1相当于跳过一个char *型的字节之后开始计数字符串的长度。
例7:
char *p = "abcdef";
printf("%d\n",strlen(&p[0]+1)); //5解析:&p[0]+1后指向第二个元素,所以从'b'开始往后计数字符串的长度。
二维数组:
我们知道二维数组在内存中是以一维数组形式存储的。
以int a[3][4]为例,存储形式如下:
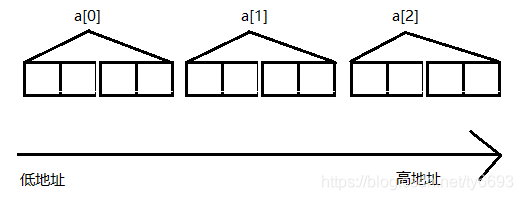
那么我们可以将a[0]当成 第一行元素的数组名,a[1]作为第二行元素的数组名,同理,a[2]就是第三行元素的数组名。
int a[3][4] = {0};
printf("%d\n",sizeof(a)); //48
printf("%d\n",sizeof(a[0][0])); //4
printf("%d\n",sizeof(a[0])); //16
printf("%d\n",sizeof(a[0]+1)); //4
printf("%d\n",sizeof(a+1)); //4
printf("%d\n",sizeof(&a[0]+1)); //4
printf("%d\n",sizeof(*a)); //16
printf("%d\n",sizeof(a[3])); //16例1:
int a[3][4] = {0};
printf("%d\n",sizeof(a)); //48解析:此时数组名单独放在sizeof内部表示整个数组,所以求的是整个数组的大小。
例2:
int a[3][4] = {0};
printf("%d\n",sizeof(a[0][0])); //4解析:a[0][0]表示数组首元素。
例3:
int a[3][4] = {0};
printf("%d\n",sizeof(a[0])); //16解析:由于a[0]是二维数组第一行的数组名且单独放在sizeof内部,所以此时求的是二维数组第一行的大小。
例4:
int a[3][4] = {0};
printf("%d\n",sizeof(a[0]+1)); //4解析:由于此时a[0]没有单独放在sizeof内部且没有取地址,所以表示的是第一行首元素即a[0][0]的地址,加1表示a[0][1]的地址。
例5:
int a[3][4] = {0};
printf("%d\n",sizeof(a+1)); //4解析:此时a并没有单独放在sizeof内部且没有取地址,所以表示的是首元素第一行a[0]的地址,加1表示第二行a[1]的地址。
例6:
int a[3][4] = {0};
printf("%d\n",sizeof(&a[0]+1)); //4解析:因为&数组名取的是整个数组的地址,所以&a[0]取的是数组第一行的地址,加1将跳过这个数组,即表示数组第二行的地址。
例7:
int a[3][4] = {0};
printf("%d\n",sizeof(*a)); //16解析:此时a并没有单独放在sizeof内部且没有取地址,所以表示的是首元素第一行a[0]的地址,解引用表示第一行。
例8:
int a[3][4] = {0};
printf("%d\n",sizeof(a[3])); //16解析:由于此二维数组并不含有a[3]元素,但sizeof操作符在求操作数的类型长度是在程序编译阶段就已经完成,而且其内部元素并不参与运算,所以a[3]就相当于a[0],a[1],a[2]。
总结:在二维数组中,对于数组名a来说,它的首元素就是a[0],即第一行,加1就是第二行;而对于第一行a[0]来说,它的首元素就是a[0][0],加1就是a[0][1]
这篇关于C语言中关于 strlen 和 sizeof 的用法及区别(含例题及解析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


