本文主要是介绍npm 开源模块,如何配置属于本模块的命令集,全局、局部安装可以使用该命令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
其实要配置属于本模块专属命令并不复杂,只需在 package.json 里配置 bin 属性就可以了,下面我们通过一个列子来说明
// package.json"bin": {"tracelib": "./bin/tracelib.js"},#!/usr/bin/env node
const fs = require('fs');
const path = require('path');
const package = require('../package.json');
const { tracelib } = require('../dist/tracelib.js');// 输出数据
function outputData(result, outputPath) {if (outputPath) {fs.writeFile(path.resolve(process.cwd(), outputPath), JSON.stringify(result), 'utf-8', function(error) {console.log('写入成功');});} else {console.log(result);}
}function run(argv) {if (argv[0] === '-v' || argv[0] === '--version') {console.log(' version is ' + package.version);} else if (argv[0] === '-h' || argv[0] === '--help') {console.log(' usage:\n');console.log(' -v --version [show version]');console.log(' [logPath][getSummary][outputPath?] Fetch total time-durations of scripting, rendering, painting from tracelogs.');console.log(' [logPath][getWarningCounts][outputPath?] Fetch amount of forced synchronous layouts and styles as well as long recurring handlers.');console.log(' [logPath][getFPS][outputPath?] Fetch frames per second.');console.log(' [logPath][getMemoryCounters][outputPath?] Fetch data for JS Heap, Documents, Nodes, Listeners and GPU Memory from tracelogs.');console.log(' [logPath][getDetailStats][outputPath?] Fetch data (timestamp and values) of scripting, rendering, painting from tracelogs.');} else if (argv.length >= 2) {const logData = require(path.resolve(process.cwd(), argv[0]));const type = argv[1];let result = '';switch (type) {case 'getSummary':result = tracelib.getSummary(logData);break;case 'getWarningCounts':result = tracelib.getWarningCounts(logData);break;case 'getFPS':result = tracelib.getFPS(logData);break;case 'getMemoryCounters':result = tracelib.getMemoryCounters(logData);break;case 'getDetailStats':result = tracelib.getDetailStats(logData);break;default:console.log(new Error('This method is not available yet.'));break;}outputData(result, argv[2]);}
}run(process.argv.slice(2));
这里是一个简单的一个封装命令的源码
其实就是一个简单的 cmd 命令参数的解析,process.argv值的处理
process 对象是一个全局变量,它提供当前 Node.js 进程的有关信息,以及控制当前 Node.js 进程。 因为是全局变量,所以无需使用 require()。
process.argv 属性返回一个数组,这个数组包含了启动Node.js进程时的命令行参数,
其中:
数组的第一个元素process.argv[0]——返回启动Node.js进程的可执行文件所在的绝对路径
第二个元素process.argv[1]——为当前执行的JavaScript文件路径
剩余的元素为其他命令行参数
node index.js param1 param2
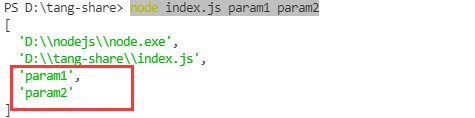
这我们可以看到,从第二个参数后就是我们传的参数,以空格分开。
只要配置在 bin 属性后,通过命令安装后,就会在全局、局部 node_modules\bin 目录下生成对应环境的可执行文件。
这样就可以通过 bin 中的命令属性,按我们预定的规则执行代码了。
下面我们来演示一下刚才封装的命令,是否能正常执行
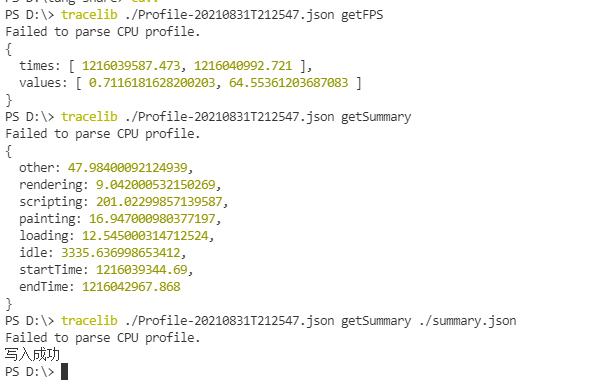
如果有不明白的可以具体参考下面的开源库
这是一个非常适用的库,主要功能是,根据 chrome 生成的 trace log 文件,通过模块封装的函数,输出具体的性能值,方便图表展示
tracelib-cjs: This library provides a set of models from the devtools-frontend code base in order to parse trace log files.Note: This is early development and not ready to be consumed yet!
如何发布自己封装的库到 npm 请参考
vue 如何开发封装自己的公共组件库,并发布到 npm 上
这篇关于npm 开源模块,如何配置属于本模块的命令集,全局、局部安装可以使用该命令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







