本文主要是介绍万方数据基于PaddleNLP的文献检索系统实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
又是一年开学季,看着大批莘莘学子步入高校,同时又有大批学生即将面临毕业,这一年要饱受论文的洗礼。在学术论文领域,几乎每一位大学生都避不开论文检索、查重环节。想写出一篇高质量论文,前期大量的信息储备必不可少,而文献检索成为我们获取信息的重要途径。
万方数据知识服务平台以客户需求为导向,整合了数亿条全球优质知识资源,依托强大的数据采集能力,应用先进的信息处理技术和检索技术,为决策主体、科研主体、创新主体提供高质量的信息资源产品。
今天就来聊聊,我们如何使用百度飞桨 PaddleNLP 升级论文检索系统。
业务背景
万方论文检索系统的核心问题是文本匹配任务,这个系统需要在数亿条知识资源中,基于检索匹配算法,根据用户的检索词快速地在海量文献中查找相似文献。
在系统任务执行过程中,检索词和文献的相关性会直接反映到结果页面的排序上面,而排序准确率直接影响着用户的搜索决策效率和搜索体验。因此,快速且准确地刻画检索词和文档之间的深度语义相关性至关重要。
然而,面对海量数据和频繁的用户搜索请求,同时解决高速和高效问题,给万方文献检索系统带来了诸多挑战:
难点 1— 标注数据少:由于人力资源紧张无法对系统中海量的数据资源进行标注,如何利用海量无监督数据,自动生成弱监督数据?
难点 2— 很难精准计算语义相似度:如何准确计算用户检索词和文献之间的相似度?
难点 3— 检索时效性差:面对海量资源和不断增长的用户需求,如何快速、高效得找到相关文献也是一大挑战。
除了检索场景外,论文查重、相似论文推荐的核心方法也是文本相似度计算。在这些业务上,我们经历了长期的探索,最终使用飞桨。得益于 PaddleNLP 丰富的中文预训练模型,面向工业级场景的模型选型与部署能力,使得我们非常高效的搭建了端到端工业级的文本向量学习和计算环境,实现了学术检索系统的多方面升级。
技术选型和项目实践
飞桨在产业实践方面提供了强悍的产品功能和技术支持,我们基于 PaddleNLP 中丰富前沿的预训练模型、使用 Paddle Serving 实现了服务端的快速部署,解决了实际业务落地中的痛点。
我们通过 PaddleNLP 提供的高质量中文预训练 Word Embedding 构造训练数据标签,结合 SimCSE 以及飞桨深度优化过的文本匹配预训练模型 Sentence-BERT,大幅提升了算法精度。
在模型性能方面,我们采用了多线程数据预处理、模型降层、TensorRT 部署。成熟开发工具的选用,极大地降低了应用深度学习技术进行产业落地的难度。
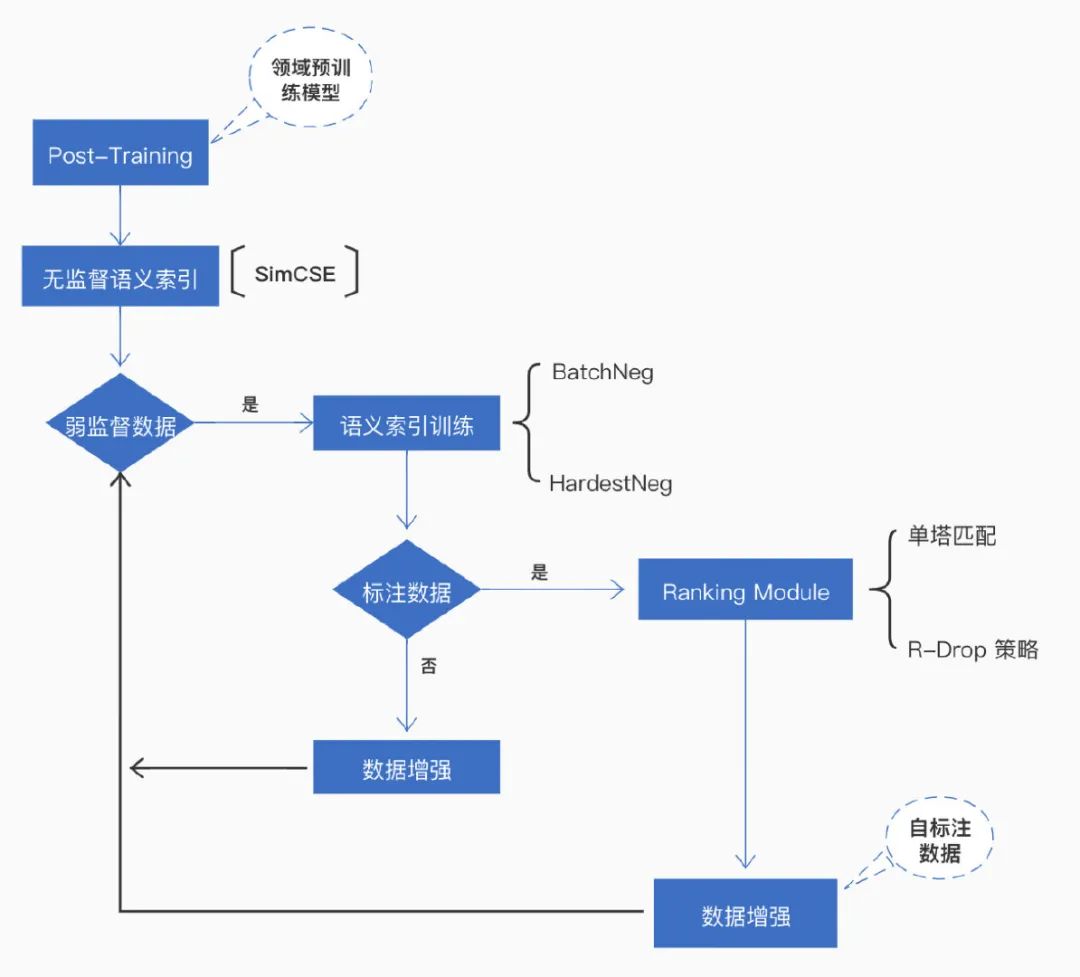
 技术方案整体架构图
技术方案整体架构图
我们的技术方案整体架构图如上所示。概括来说,主要包括三部分:构造数据、模型选择和产业部署。
1. 构造数据
万方业务积累了海量的无监督数据,但是标注数据极少。我们使用 PaddleNLP 开源的高质量中文预训练词向量,快速构建了弱监督的相似文本匹配数据,节省了大量的人力标注成本。
为了数据指标的进一步提升,我们还采用了无监督语义匹配模型 SimCSE。
此外,万方搜索系统积累了大量用户行为日志数据(如浏览、点击、阅读、下载等),我们也从业务角度筛选出了大量监督数据。
SimCSE 参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_matching/simcse
2. 模型选择
关于文本相似度计算,我们使用过字面匹配、word2vec、FastText 等方法,都无法学到足够精度的文本语义表示。我们知道百度在搜索场景有丰富的技术积累,也关注到 PaddleNLP 里集成了 ERNIE、BERT 等一系列预训练语义模型,并且针对检索场景给出了系统化方案。

近年来,以 BERT、ERNIE 为代表的预训练语言模型成为 NLP 任务的主流模型。
Sentence-BERT 使用孪生网络结构,在 BERT 模型的基础上进行 Fine-Tune,引入(DSSM)双塔模型,符合我们的业务场景,因此我们选择该模型作为我们的基准模型。
较 FastText 模型,Sentence-BERT 的匹配效果提升了 70%,用户的整体体验大幅度提高。
我们将数据库中的文献预先通过 Sentence-BERT 计算得到文献向量后,通过开源向量数据库 Milvus 建立索引库,快速召回相似向量,减少了检索系统的响应时间。
Sentence-BERT 参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_matching/sentence_transformers
语义索引策略参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/semantic_indexing
3. 产业部署
线上检索系统尤其需要考虑快速响应需求。Sentence-BERT 12 层 Transfomer 结构,具有庞大的参数量和计算量,在部署上线时面临响应实时性的巨大挑战。
为了满足线上业务对于性能上的要求,我们通过飞桨原生推理库 Paddle Inference 结合飞桨服务化部署框架 Paddle Serving 进行推理预测。
在不损失精度的前提下,我们将 Sentence-BERT 从 12 层压缩至 6 层,并结合了 TensorRT 加速等优化手段,使得 QPS 达到 2600,超预期完成了目标。
延伸 - 检验场景整体方案
以上我们参考了 PaddleNLP 检索场景整体方案,其主要包括领域预训练 (Post-Training)、语义匹配和语义索引三大部分。
领域预训练是在通用预训练模型基础上,在领域数据上继续预训练,让预训练模型学习更多的领域知识。
语义匹配模块针对存在高质量监督数据的场景,给出了检索系统中排序模型方案。此外,针对高质量标注数据获取成本高,数据量少的问题,语义匹配模块还内置了 R-Drop 数据增强策略,进一步提升小数据量场景下排序模型效果,从而帮助检索系统达到更优的效果。
语义索引模块针对无监督和有监督数据场景,分别给出了无监督语义索引 (SimCSE) 和监督语义索引的方案,即使没有监督数据,也能利用无监督语义索引方案提升检索系统的召回效果。
针对工业应用落地部署的高性能需求,预测部署环节还提供了基于 FasterTransformer 的高性能预测能力以及简单易用的 Python API,便于我们将模型快速落地到实际业务中。
后续在万方业务中,我们将使用 R-Drop 数据增强策略、FasterTransformer 进一步应对持续新增的用户需求。
如果您想了解详细方案,可关注 PaddleNLP,⭐️Star⭐️收藏,跟进其最新功能,也可在直播中与我交流哦:
GitHub Repo: https://github.com/PaddlePaddle/PaddleNLP
直播预告
万方数据的技术负责人将为大家直播讲解,如果你也有相同的业务痛点,或者想进一步了解 PaddleNLP 在产业实践中的具体实现,欢迎大家扫码上车!
9 月 14 日晚 19:00-20:00,直播间不见不散~
扫码报名课程,立即加入交流群

精彩内容抢先看

这篇关于万方数据基于PaddleNLP的文献检索系统实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






