本文主要是介绍为什么说SAS、FC对CPU耗费比TCPIP+以太网低,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么说SAS、FC对CPU耗费比TCPIP+以太网低
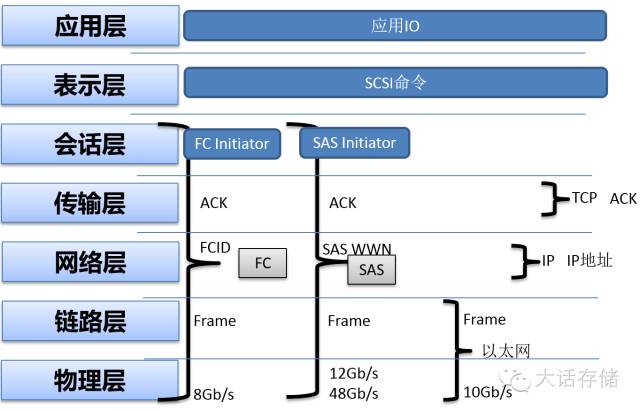
如果按照OSI模型来划分的话,FC/SAS协议都运行在下四层,而以太网运行在下两层,TCP/IP运行在传输层和网络层。那么很自然的,TCP/IP+以太网就可以完成FC、SAS的功能。但是,TCP/IP协议栈是运行在主机端内核中的,需要耗费主机CPU来运算。具体体现在,以太网卡会将每一个接收到的以太网帧都传送到主机TCP/IP协议栈,在这里,TCP/IP模块对接收到的以太网帧进行IP地址分析、TCP层的数据段定界、校验、检测重传、包的拼接操作,这一系列操作都需要主机CPU运行TCP/IP的代码来执行。而FC/SAS的所有下四层,都在FC/SAS控制器的硬件电路或者固件中就完成了,其传送到主机内存里的数据直接就是FC/SAS包中所包含的上层Payload,所以其对主机CPU的耗费较小,产生的时延也较低,因为如果是TCP/IP的话,每个以太网帧被拷贝到主机内存,然后经过CPU每处理,这整个流程的时延将会较高,其中会有多次内存拷贝动作。对于那些对时延有要求的应用,比如OLTP类、同步IO类,基于TCP/IP协议的IO就会有劣势。

这篇关于为什么说SAS、FC对CPU耗费比TCPIP+以太网低的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






