本文主要是介绍lt Redis变慢的原因及排查解决方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
Redis 作为优秀的内存数据库,其拥有非常高的性能,单个实例的 OPS 能够达到 10W 左右(5-10W)。但也正因此如此,当我们在使用 Redis 时,如果发现操作延迟变大的情况,就会与我们的预期不符。
你也许或多或少地,也遇到过以下这些场景:
-
在 Redis 上执行同样的命令,为什么有时响应很快,有时却很慢?
-
为什么 Redis 执行 SET、DEL 命令耗时也很久?
-
为什么我的 Redis 突然慢了一波,之后又恢复正常了?
-
为什么我的 Redis 稳定运行了很久,突然从某个时间点开始变慢了?
…
Redis真的变慢了吗?
首先,在开始之前,你需要弄清楚 Redis 是否真的变慢了?
如果你发现你的业务服务 API 响应延迟变长,首先你需要先排查服务内部,究竟是哪个环节拖慢了整个服务。
比较高效的做法是,在服务内部集成 链路追踪,也就是在服务访问外部依赖的出入口,记录下每次请求外部依赖的响应延时。
(无监控,不调优)
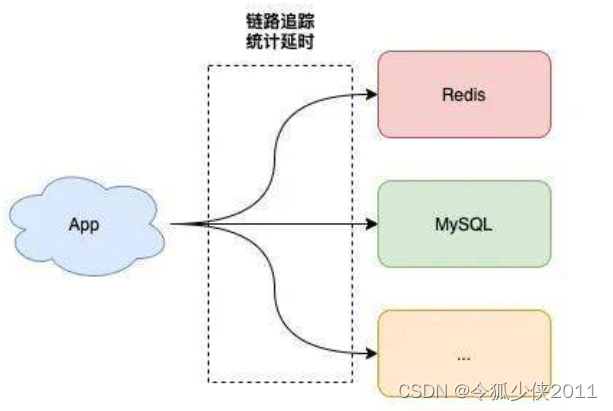
如果你发现确实是操作 Redis 的这条链路耗时变长了,那么此刻你需要把焦点关注在业务服务到 Redis 这条链路上。
从你的业务服务到 Redis 这条链路变慢的原因可能也有 2 个:
- 业务服务器到 Redis 服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况
- Redis 本身存在问题,需要进一步排查是什么原因导致 Redis 变慢
通常来说,第一种情况发生的概率比较小,如果是服务器之间网络存在问题,那部署在这台业务服务器上的所有服务都会发生网络延迟的情况(可是一些get商品查询接口正常返回),此时你需要联系网络运维同事,让其协助解决网络问题。
所以 我们重点关注的是第二种情况。
也就是从 Redis 角度来排查,是否存在导致变慢的场景,以及都有哪些因素会导致 Redis 的延迟增加,然后针对性地进行优化。
一、实例内存达到上限
排查思路
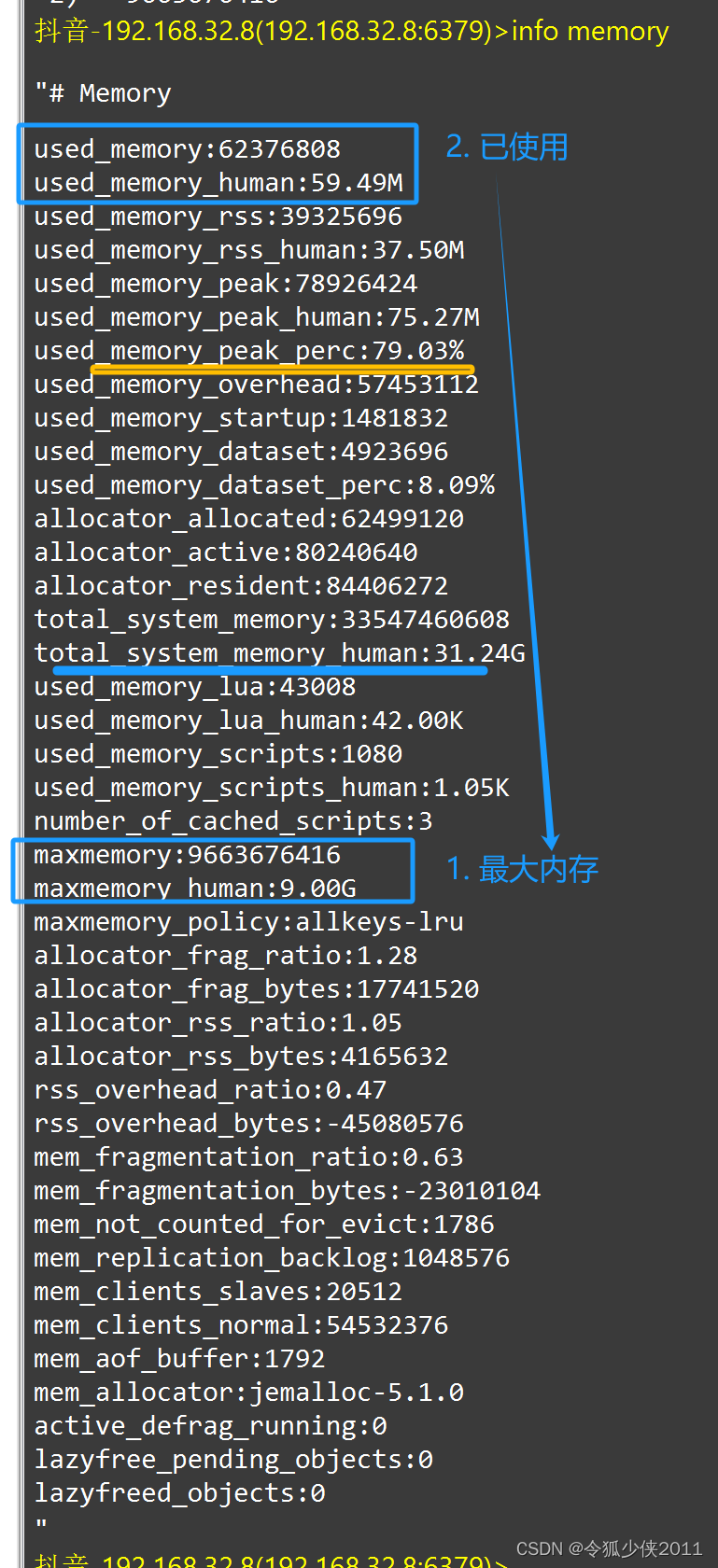
如果你的 Redis 实例设置了内存上限 maxmemory,那么也有可能导致 Redis 变慢。
当我们把 Redis 当做纯缓存使用时,通常会给这个实例设置一个内存上限 maxmemory,然后设置一个数据淘汰策略。而当实例的内存达到了 maxmemory 后,你可能会发现,在此之后每次写入新数据,操作延迟变大了。
导致变慢的原因
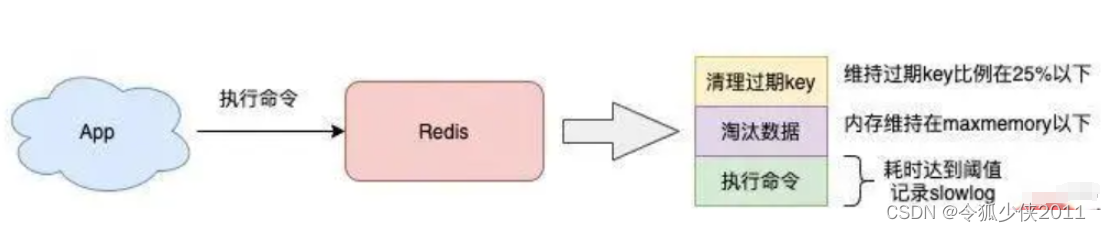
当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
info memory
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略:
- allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 key
- volatile-lru:只淘汰最近最少访问、并设置了过期时间的 key
- allkeys-random:不管 key 是否设置了过期,随机淘汰 key
- volatile-random:只随机淘汰设置了过期时间的 key
- allkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 key
- noeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错误
- allkeys-lfu:不管 key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)
- volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
具体使用哪种策略,我们需要根据具体的业务场景来配置。一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略,它们的处理逻辑是,每次从实例中随机取出一批 key(这个数量可配置),然后淘汰一个最少访问的 key,之后把剩下的 key 暂存到一个池子中,继续随机取一批 key,并与之前池子中的 key 比较,再淘汰一个最少访问的 key。以此往复,直到实例内存降到 maxmemory 之下。
需要注意的是,Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。
另外,如果此时你的 Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
看到了么?bigkey 的危害到处都是,这也是前面我提醒你尽量不存储 bigkey 的原因。
解决方案
- 避免存储 bigkey,降低释放内存的耗时
- 淘汰策略改为随机淘汰,随机淘汰比 LRU 要快很多(视业务情况调整)
- 拆分实例,把淘汰 key 的压力分摊到多个实例上
- 如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes)
二、排查大 key 的方法
多大的 key 算大呢?
Redis 实践总结(仅供参考):
合理的 Key 中 Value 的字节大小,推荐小于 10 KB。
过大的 Value 会引发数据倾斜、热点Key、实例流量或 CPU 性能被占满等问题,应从设计源头上避免此类问题带来的性能影响。
那么 value Bytes > 10 kb 可以作为判断 大 key 的一个参考值。
————————————————
排查大 key 的方法
- 使用命令 --bigkeys
–bigkeys 是 redis 自带的命令,对整个 Key 进行扫描,统计 string,list,set,zset,hash 这几个常见数据类型中每种类型里的最大的 key。
string 类型统计的是 value 的字节数;另外 4 种复杂结构的类型统计的是元素个数,不能直观的看出 value 占用字节数,所以 --bigkeys 对分析 string 类型的大 key 是有用的,而复杂结构的类型还需要一些第三方工具。
注:元素个数少,不一定 value 不大;元素个数多,也不一定 value 就大
D:\redis-64.3.0>redis-cli.exe -h 192.168.32.8 -p 6379 -a 123456 --bigkeys -i 0.1
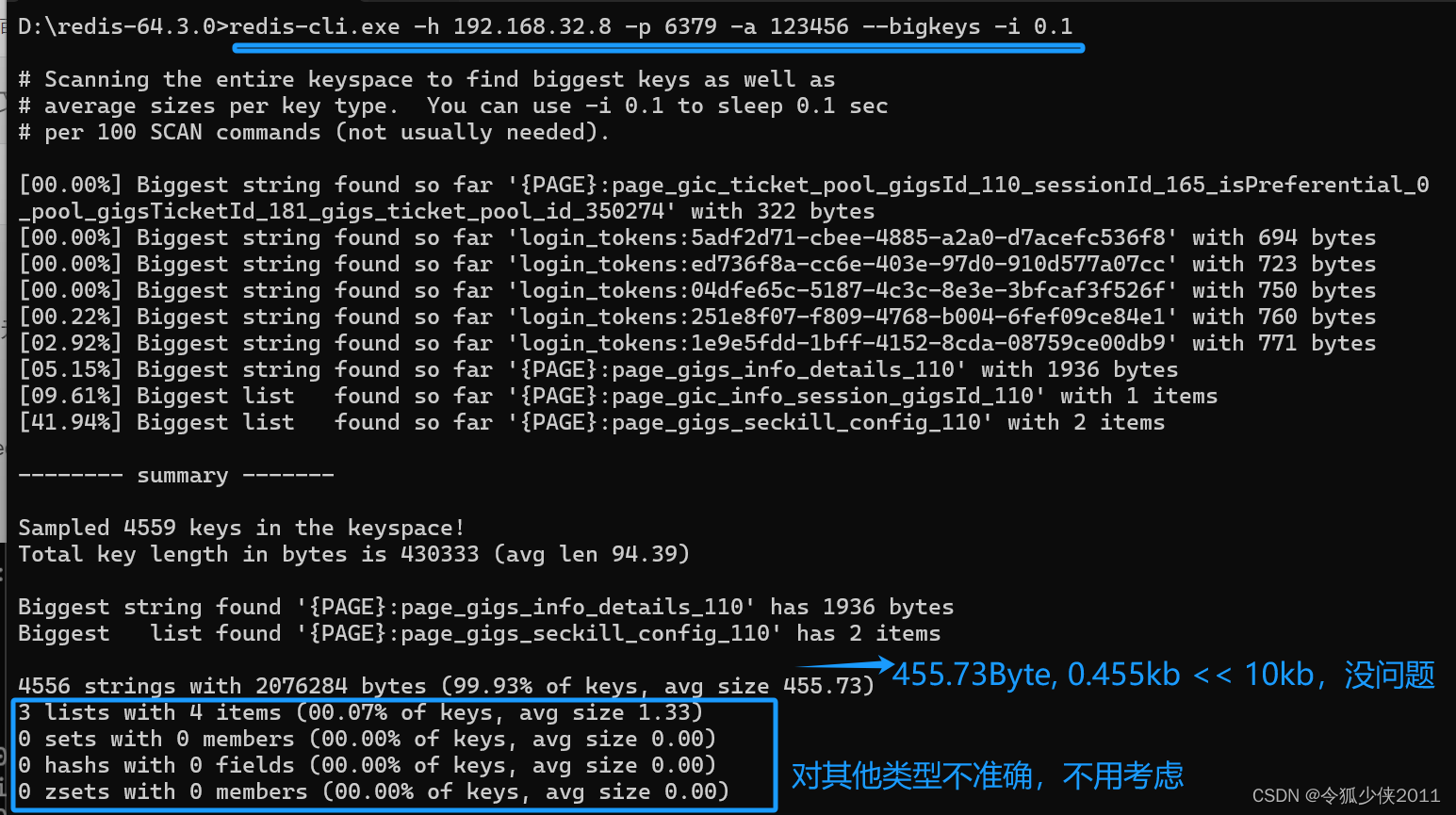
- –bigkeys 是以 scan 延迟计算的方式扫描所有 key,因此执行过程中不会阻塞 redis,但实例存在大量的 keys 时,命令执行的时间会很长,这种情况建议在 slave 上扫描。
- –-bigkeys 其实就是找出类型中最大的 key,最大的 key 不一定是大 key,最大的 key 都不超过 10kb 的话,说明不存在大 key。
但某种类型如果存在较多的大key (>10kb),只会统计 top1 的那个 key,如果要统计所有大于 10kb 的 key,需要用第三方工具扫描 rdb 持久化文件。
这篇关于lt Redis变慢的原因及排查解决方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






