本文主要是介绍Nginx:max_fail和fail_timeout没那么简单,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
今天遇到了一个nginx的问题,稍微深入了解了一下nginx的原生健康检测机制,就在那一刻才发现自己太过迷恋tengine的http_upstream_check_module了,对原生的健康检测有误解。
我一直认为:原生的nginx只能做tcp检测。
我一直认为:原生的nginx在检测后端服务失败后,就会将后端节点踢掉。
我一直认为:fail_timeout是每次检测的超时时间,max_fail是检测的次数。
全NM是误解,C了。

max_fail和fail_timeout
理解
官方文档的位置 https://nginx.org/en/docs/http/ngx_http_upstream_module.html
#样例:upstream backend {server backend1.example.com weight=5;server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;server unix:/tmp/backend3;server backup1.example.com backup;
}max_fails:是失败次数;
fail_timeout: fail_timeout时间内如果失败了max_fails次,就会将节点标记为不可用。不可用的时间为fail_timeout 。 这就轮回起来了。
当max_fails为0的时候,就相当于关闭健康检测了。
怎么判断失败呢
有一个参数 proxy_next_upstream ,他的默认值是error和timeout, 也就是说当建立连接的时候超时或者是报错,就认为这个节点失败的。
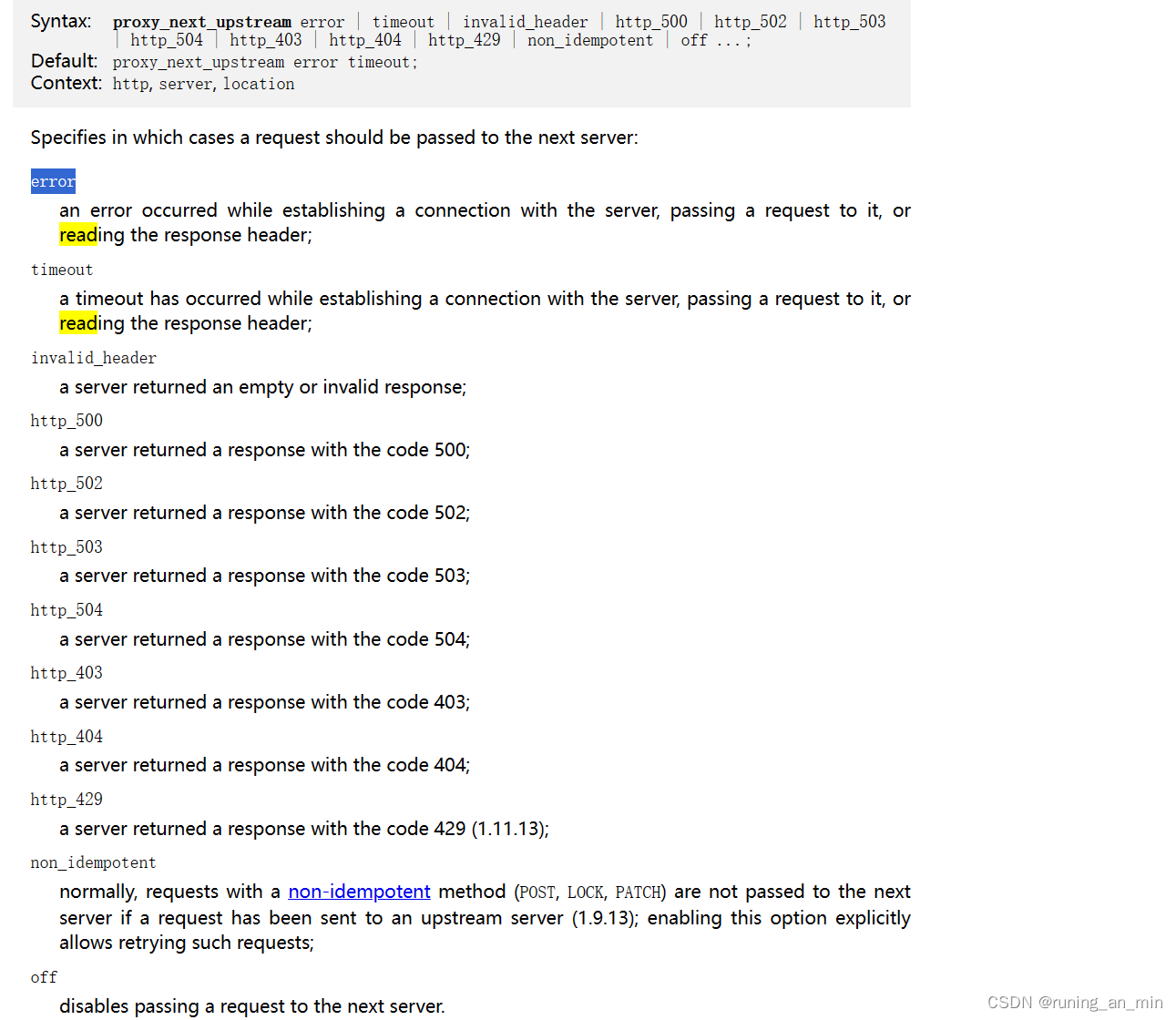
我们此处可以看到也有一些http的状态检测的手段,所以说原生的健康检测也能做七层的检测。
超时时间
既然超时算是失败,那么超时时间是多少呢?这个就比较讲究了。
由proxy_connect_timeout(默认60s)和 net.ipv4.tcp_syn_retries (操作系统的,默认是6)这两个参数中较小的决定。
net.ipv4.tcp_syn_retries是当upstream中的server不返回ack的时候,重传syn的次数,默认是6次,6次的耗时是:1s,2s,4s,8s,16s,32s。 然后64s 后尝试另一个server。这样加起来差不多2m左右。
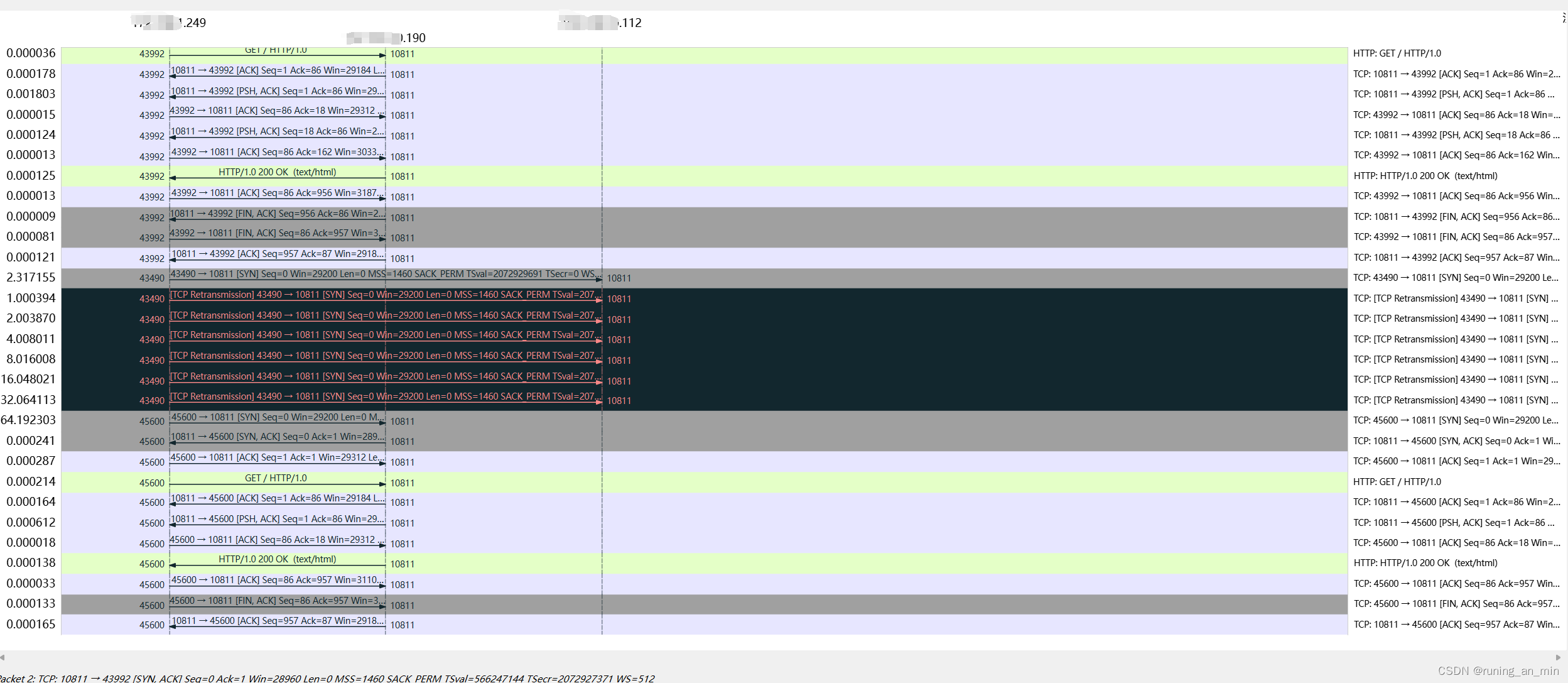
我们最好使用proxy_connect_timeout和proxy_send_timeout(这个我目前还不确定,会不会增加失败次数)来决定超时时间。
这两个值我觉得设置比较小就可以,因为后端服务如果在几秒内还没有接收请求或者建立连接,说明它已经很忙了,我们就可以尝试其他的server,或者返回给前端 502(前端可以设置一些策略,比如重试+按钮转圈+美好的提示等)来提供客户的体验,这样比等着好,因为用户越等越急,可能会暴躁的连击几下按钮,服务就更慢了。
fail_timeout要根据proxy_connect_timeout 和你的服务性能来配置。
如果你的服务平均响应时长是30s,而你的proxy_connect_timeout是5s,那么你接收到的响应肯定都是504 。
如果proxy_connect_timeout是10s,fail_timeout设置了一个1s, 那么这个节点永远不会被标记为不可用,当服务hang住的时候,你每次请求都要等待proxy_connect_timeout后才能尝试下一个server。
proxy_next_upstream_timeout
这个参数意思是:在上一个server失败了以后,需要等待proxy_next_upstream_timeout时间后,再尝试下一个server。
一个节点的情况
当upstream下只配置一个server的时候,这个server不会被标记为不可用,如果这个节点hang住了,你每次请求都要等待超时。 当你的proxy_connect_timeout比较大的时候,就更悲催了。别问我是怎么知道的。。。555....

http_upstream_check_module
# http check
upstream student-service-api {server 172.26.34.101:9050;check interval=3000 rise=2 fall=5 timeout=1000 type=http;check_http_send "HEAD /health/check/status HTTP/1.0\r\n\r\n";check_http_expect_alive http_2xx http_3xx;
}upstream nerf {server 172.16.0.249:8091 weight=1;server 172.16.1.246:9019 weight=4;check interval=1000 rise=2 fall=5 timeout=10000 type=tcp;
}
这是tengine的健康检测模块,他和nginx原生额最大区别就是,他是主动检测的。所以,他不会出现上面一个节点不可能用时,仍然要等待超时的问题。再就是节点不可用的时候,他会打印error l日志,对于用户来说比较友好。
如何模拟服务hang的情况
一个比较无脑的方法:
# 记得 net.ipv4.ip_forward = 1
docker run -itd docker.io/centos:7 -p 10811:10811 bash然后进入容器:
python -m SimpleHTTPServer 10811然后回到服务器上
iptables -F然后10811服务就会hang住了。
如何模拟500报错的服务的情况
# 记得 net.ipv4.ip_forward = 1
docker run -itd docker.io/centos:7 -p 10811:10811 bash然后进入容器,创建一个python脚本
from SimpleHTTPServer import SimpleHTTPRequestHandler
import BaseHTTPServer
import sysclass CustomHTTPRequestHandler(SimpleHTTPRequestHandler):def do_GET(self):if self.path == '/':self.send_response(500)self.end_headers()self.wfile.write('Internal Server Error')else:super(CustomHTTPRequestHandler, self).do_GET()def run(server_class=BaseHTTPServer.HTTPServer, handler_class=CustomHTTPRequestHandler):server_address = ('', 10811)httpd = server_class(server_address, handler_class)print 'Starting httpd on port %d...' % server_address[1]httpd.serve_forever()if __name__ == '__main__':run()
然后执行脚本,就可以了。
##
祝你好运
# 有问题可以进群聊聊
614809646 qq群->数字人和tts,运维、开发等等


这篇关于Nginx:max_fail和fail_timeout没那么简单的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







