本文主要是介绍Linux IO流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3、 IO体系概览
先看看本文主题IO调度和IO队列处于整个IO体系的哪个位置,这个IO体系是非常重要的,了解IO体系我们可以对整个IO过程有个全面的认识。虽然一下两下并不清楚IO体系各个部分的细节,但是我们总是能从这儿找到脉络。知道什么问题在什么位置,这个是解决问题的时候最关键的。任何所谓的专家都不太可能100%的了解全部细节,但是知道脉络,可以针对问题有的放矢。
接下来咱们还是继续主题,请看下图
对于read系统调用在内核的处理,经过了VFS【其在内核中为用户空间层的文件系统(ext4、xfs等)提供了相关的接口】、具体文件系统,如ext2、页高速缓冲存层(page cache)、IO调度层、设备驱动层、和设备层。其中,VFS主要是用来屏蔽下层具体文件系统操作的差异,对上提供一个统一接口,正是因为有了这个层次,所以可以把设备抽象成文件。具体文件系统,则定义了自己的块大小、操作集合等。引入cache层的目的,是为了提高IO效率。它缓存了磁盘上的部分数据,当请求到达时,如果在cache中存在该数据且是最新的,则直接将其传递给用户程序,免除了对底层磁盘的操作。IO调度层则试图根据设置好的调度算法对通用块层的bio请求合并和排序,回调驱动层提供的请求处理函数,以处理具体的IO请求。驱动层的驱动程序对应具体的物理设备,它从上层取出IO请求,并根据该IO请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据。设备层都是具体的物理设备。
(注意:本图不涉及direct I/O)
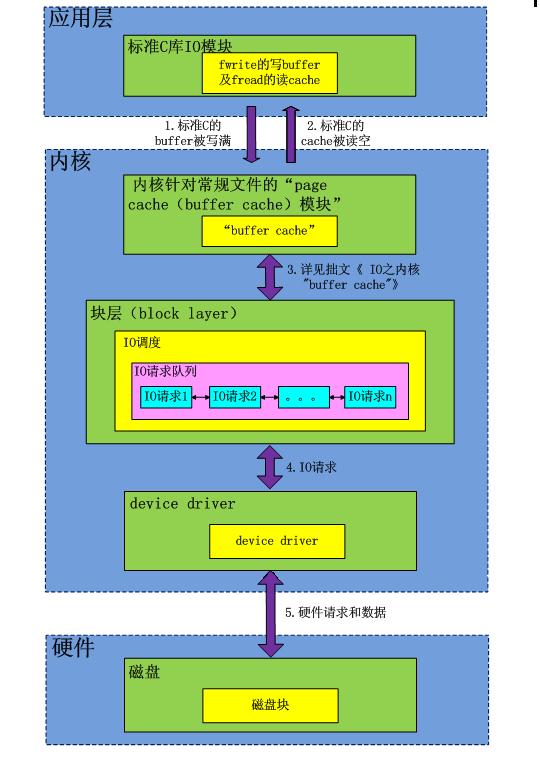
图中数据流箭头1,2如果不了解请参照拙文《IO之标准C库buffer》。
图中数据流箭头3如果不了解请参照拙文《IO之内核buffer—-“buffer cache”》。
3.1 IO调度和IO队列
1.向块设备写入数据块或是从块设备读出数据块时,IO请求要先进入IO队列,等待调度。
2.这个IO队列和调度的目标是针对某个块设备而言的,换句话说就是每个块设备都有一个独立的IO队列。
3.本篇所涉及的所谓的块设备就是iostat命令里面列出的形如sda,sdb这样的块设备,并不是指物理磁盘。假如一个盘被分成5个分区,那么在这个主题下,5个分区代表5个块设备,每个块设备都有自己独立的IO队列。
4.I/O 调度程序维护这些队列,以便更有效地利用外存设备。简单来说,IO调度程序将无序的IO操作变为大致有序的IO请求。比如调度的时候调整几个IO请求的顺序,合并那些写盘区域相邻的请求,或者按照写磁盘的位置排序这些请求,以降低磁头在磁盘上来回seek的操作,继而加速IO。
5.每个队列的每一次调度都会把整个队列过一遍,类似于进程调度的时候每次调度都要计算RUN队列的全部进程的优先级。
3.2 IO队列深度
这个参数是iostat里面呈现的,字面意思显而易见,就是IO队列的深度,这个参数有何意义呢?
针对每个机械物理盘,如果这个盘对应的IO队列深度超过3,那么基本上表示这个盘处理IO硬件请求有点吃紧,这个盘对应的IO队列深度怎么算呢?
还拿上面一个盘被切成5个分区说事儿,5个分区对应5个块设备,5个块设备对应5个IO队列,这5个IO队列的深度总和就是这个机械物理盘的IO队列深度了。
如何解决这个盘的IO请求吃紧呢,最简单的办法硬件加速,把这个盘换成SSD盘:)
说到这儿,我想提一提RAID卡。咱们使用RAID卡把几个硬盘放在一起,让系统只能看见一个块设备。这个时候,假如有4个盘被放在RAID后面。那么这个RAID卡对应的块设备的IO队列深度允许超过12(4个磁盘,每个盘承受深度为3)。
SSD盘可承受的IO队列深度值很大,这个多少深度合适,我没有注意具体观察过。
3.3 iostat另一个参数—-“%util”
实际生产系统上,我观察IO设备是否吃紧,其实是看这个util的。这个值长期高于60,咱们就得考虑物理磁盘IO吃不消了。
如果是使用机械硬盘的服务器上这个值达到90以上,最简单的解决方案仍然是换SSD盘,换完之后这个值会下降到20左右,非常有效。
3.4 IO调度算法
IO调度算法存在的意义有两个:一是提高IO吞吐量,二是降低IO响应时间。然而IO吞吐量和IO响应时间往往是矛盾的,为了尽量平衡这两者,IO调度器提供了多种调度算法来适应不同的IO请求场景。
以下几个算法介绍是网上抄来的,说的很详细,作者水平很高:)
1、NOOP
该算法实现了最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说”大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。
假设有如下的io请求序列:
100,500,101,10,56,1000
NOOP将会按照如下顺序满足:
100(101),500,10,56,1000
2、CFQ
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
假设有如下的io请求序列:
100,500,101,10,56,1000
CFQ将会按照如下顺序满足:
100,101,500,1000,10,56
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
3、DEADLINE
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
这个算法特别适合数据库这种随机读写的场景。
4、ANTICIPATORY
CFQ和DEADLINE考虑的焦点在于满足离散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。
IO调度器算法的选择,既取决于硬件特征,也取决于应用场景。
在传统的SAS盘上,CFQ、DEADLINE、ANTICIPATORY都是不错的选择;对于专属的数据库服务器,DEADLINE的吞吐量和响应时间都表现良好。然而在新兴的固态硬盘比如SSD、Fusion IO上,最简单的NOOP反而可能是最好的算法,因为其他三个算法的优化是基于缩短寻道时间的,而固态硬盘没有所谓的寻道时间且IO响应时间非常短。
3.5 IO调度算法的查看和设置
查看和修改IO调度器的算法非常简单。假设我们要对sda进行操作,如下所示:
cat /sys/block/sda/queue/scheduler
echo ‘cfq’ >/sys/block/sda/queue/scheduler
还有持久化设置,不一一列举了。
Ps:
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。
而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备
这篇关于Linux IO流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





