本文主要是介绍OS复习笔记ch4,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
上一章,我们学习了进程的相关概念和知识,不知道小伙伴们的学习进度如何,没看的小伙伴记得去专栏看完哦。
线程从何而来
我们之前说过,进程是对程序运行过程的抽象,它的抽象程度是比较高的。
一个进程往往对应一个程序。所以当我们需要登录多个QQ帐户的时候,打开了多个QQ.exe,OS创建了多个对应的进程,在每一个QQ进程中我们可以聊天和传输文件等。
但是,小伙伴们有没有想过这个问题,我们的程序绝大多数都是顺序执行的。只有少数开发语言执行会有异步的问题(比如JavaScript),绝大多数代码是按照我们书写的顺序,从上到下依次执行。
如果是这样的话,一个QQ.exe,它对应了一份代码(将相关的代码看成一个整体),那么它似乎就做不到可以同时聊天和传输文件了。
事实是这样吗?
显然,我们的QQ是十分智能的,它不仅可以一边上传文件、一边聊天、还能一边视频……,按照我们之前的逻辑这不对啊,QQ这一个程序怎么能同时执行多个模块的代码呢?
原因其实很简单,在QQ进程底下,会细分成处理聊天的线程、处理文件的线程、处理视频的线程,它们并发执行,类似于OS的多进程,而这就是我们线程的由来。
进程存在的问题
说到这,可能有小伙伴问了,竟然多线程和OS的多进程很像,为啥要多整了个线程的概念,直接创建进程不就行了吗?
这就不得不提进程存在的问题了
- 进程创建、切换开销大(服务器的成千上万的请求响应要创建进程、分配资源)
- 进程通信代价大:经过内核
- 进程间的并发性粒度较粗,并发度不高。
- 不适合并行计算和分布式并行计算的需求。
说白了,就是进程的抽象程度比较高,每次进程要做点啥事都要在内核里面执行,来回切换非常麻烦,效率也比较低。
解决方法
在讲解本节之前,就让我们回顾一下进程的两个重要特征
- 资源的拥有者——进程包括容纳进程映像的虚拟地址空间
- 调度和执行的单位——沿着执行轨迹与其他进程交替执行
以上两个特征独立的,构成进程并发的基础。
很容易想到,之前我们的进程通信、切换等都要经过内核主要是因为他们是调度和执行的基本单位。那为了提高进程切换和通信的效率,我们就要对这个基本单位动一点手脚。
当我们分别对待上述两个特征
- 将资源的拥有者继续作为进程,即资源分配和保护的基本单位,不需要频繁切换。
- 然后通过引入线程,作为调度和分派执行的基本单位。
这样,不就完美解决了上述问题了吗,感觉自己很崇明的样子,嘿嘿。
于是乎,线程继承了进程的一些特征

其中
- 线程也有自己ID和控制块(TCB),实现思路和进程很像
- 具有运行、就绪、阻塞三种基本状态
- 有线程的上下文,也就是栈、堆、寄存器级别的信息
- 执行栈,用于存放运行的中间变量
- 共享所在进程的内存和资源,线程之间并发执行
既然我们的方案这么完美,那么这种设计到底有哪些优点呢?
- 已有进程内创建一个线程比创建全新进程用时少。
- 终止一个线程比进程用时少
- 同进程内线程的切换比进程切换用时少
- 线程提高了程序间的通信效率
- 减少并发执行的时间和空间的开销,提高并发程度。
- 适合多处理器系统。
线程分类
- 用户级线程(User Level Thread,ULT):应用程序负责所有线程的管理(内核不知用户级线程的存在)
- 内核级线程/轻量进程(Kernel-Level Threads,KLT):由OS管理的线程(类似于进程管理,对应于一个或者多个用户级线程)
ULT
如图所示
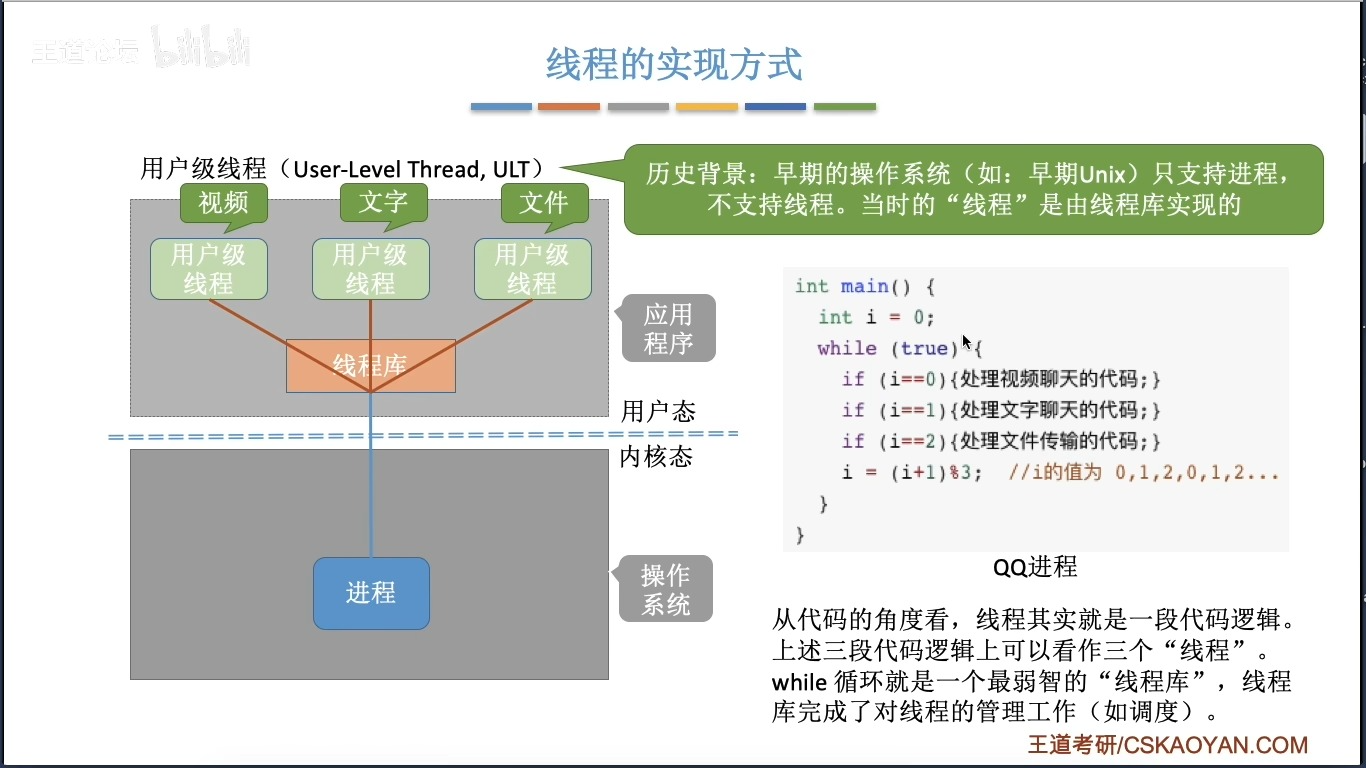
优:
- 无需用户态/核心态的切换
- 线程调度算法(线程库)可以针对应用优化
缺:
一个线程发起系统调用而被阻塞,则整个进程中的线程都被阻塞(CPU看不到线程级别,就阻塞给整个进程,而线程的状态来不及发生变化)。
KLT
如图所示
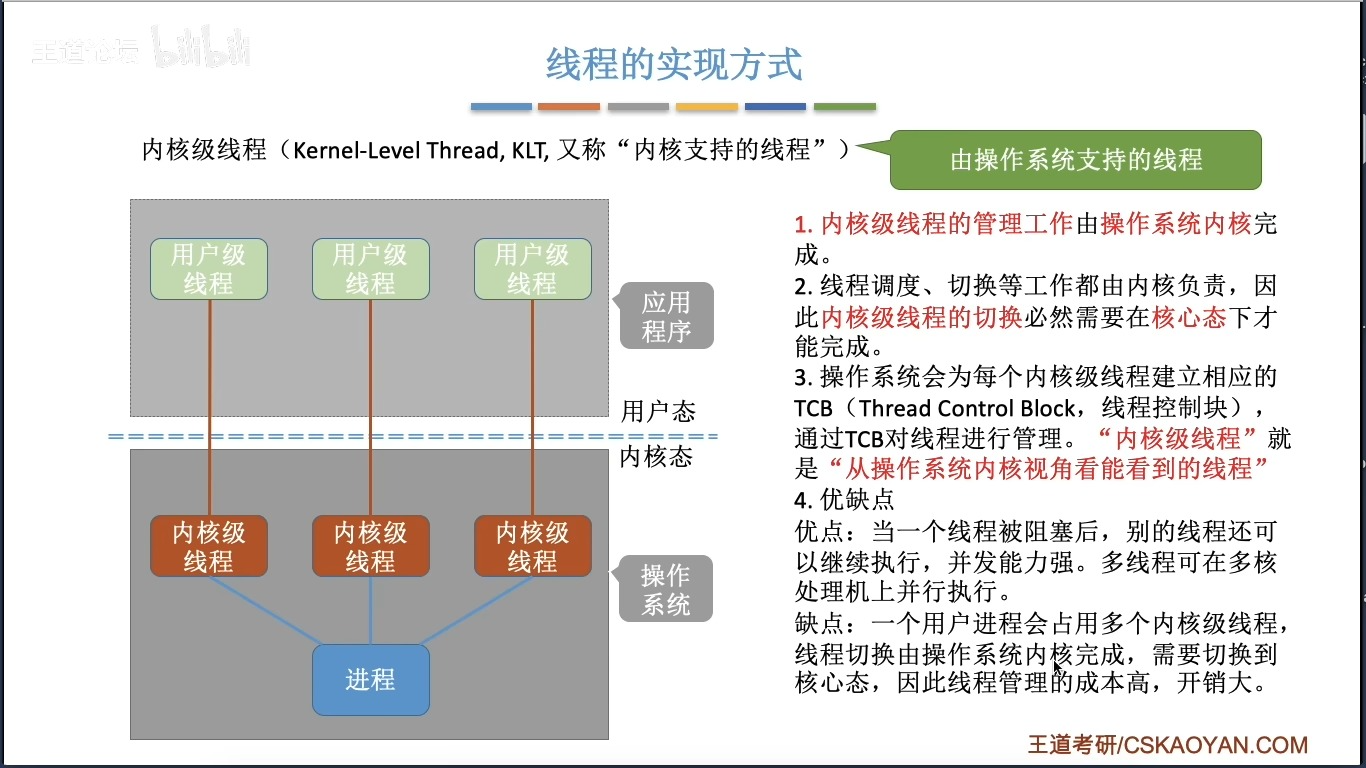
优:
- 内核可以同时在多处理器上调度进程的多个线程
- 一个线程被阻塞,内核可调度其他线程
- 内核例程也可以是多线程(比如,openEuler的2号进程)
缺:
同一个进程中一个线程切换到另一线程需要内核的模式切换。
两者结合
将ULT映射到KLT,在某些OS,例如Solaris系统是这样

取ULT和KLT的两者所长,有点像CO里面的组相联映射,既获得了仅有用户级线程的开销,又获得了仅有内核级线程的并发度,中庸之道妙哉妙哉。
多核和多线程(拓展)
多核系统的多线程支持

这里的speedup,f是程序并行部分占比,f/N是放在N个核上的时间,1-f是不可并行的时间。
这个公式表明,当增加更多的处理器时,总体的速度提升受到程序可并行化部分的比例的限制。如果 𝑓是一个较小的数,即使增加了很多处理器,总的速度提升也可能不大;如果 𝑓接
近1,也就是说程序几乎完全可以并行化,那么增加更多的处理器会显著提高速度。
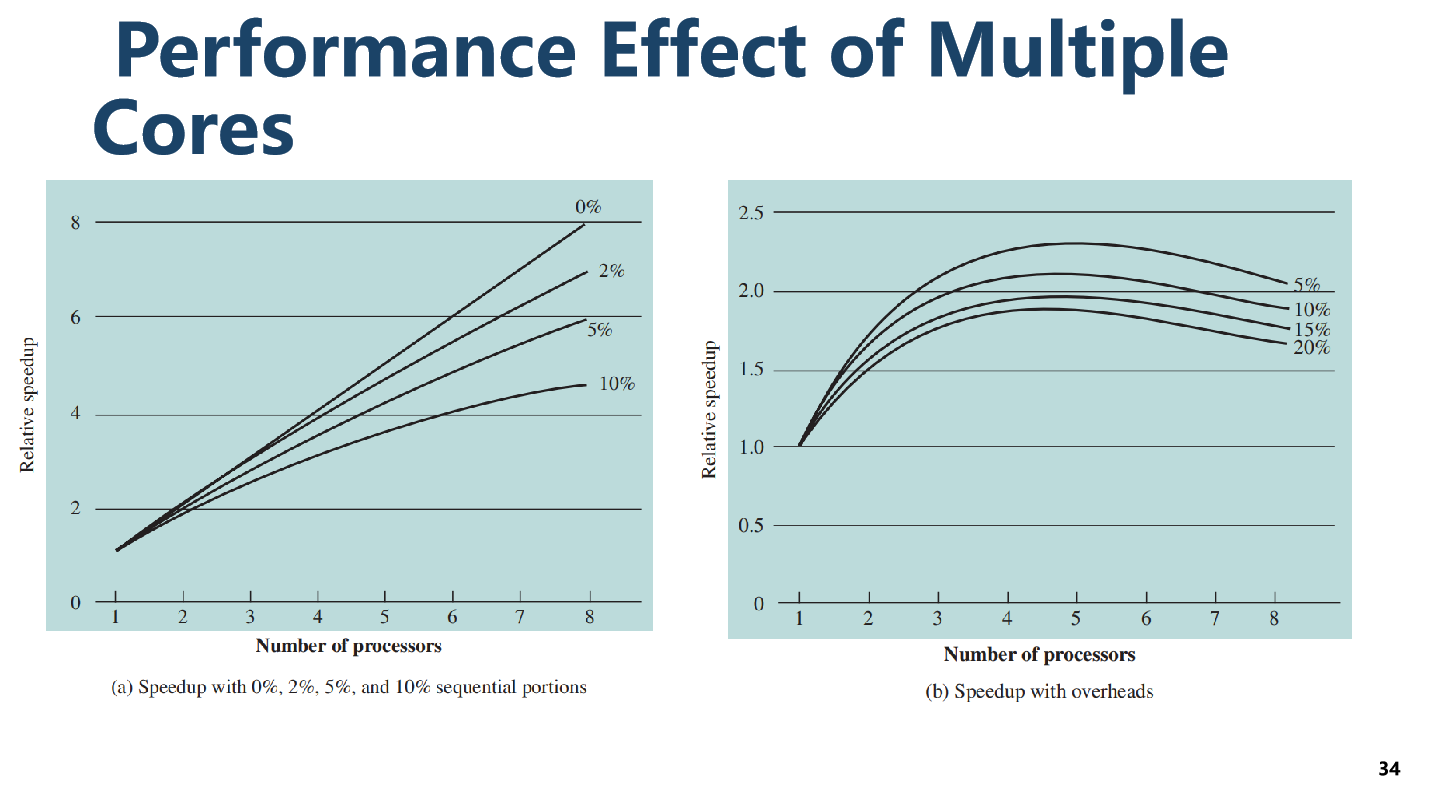
图(a)–不考虑系统开销,1 - f = 0%、2%、5%、10%的各组对比实验,符合上述公式
图(b)–考虑系统开销,1 - f = 0%、2%、5%、10%的各组对比实验。
实际上,即使是完全可以并行化的程序(𝑓=1),并行处理的速度提升也不会接近处理器的数量 𝑁。这表明有一个性能的上限,即不管你有多少处理器,速度提升永远不会无限大。因为处理器的数量增多开销也会增大,比如增加处理器之间的通信、同步等,并行执行的额外成本。
此外,由于引入了多核,程序可以设计有了更多的可能,比如多线程,多进程,或者像Java这种一个进程多个线程,以及多个并行实例。
小结
 本章节的知识和内容一般会和进程放在一起去考察,涉及到的概念也比较多,小伙伴们要像糖葫芦那样多串一串,这样有助于形成一个良好的知识体系。
本章节的知识和内容一般会和进程放在一起去考察,涉及到的概念也比较多,小伙伴们要像糖葫芦那样多串一串,这样有助于形成一个良好的知识体系。
这篇关于OS复习笔记ch4的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








