本文主要是介绍MySQL统计一个表的行数,使用count(1), count(字段), 还是count(*)?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么要使用count函数?
在开发系统的时候,我们经常要计算一个表的行数。比如我最近开发的牛客社区系统,有一个帖子表,其中一个功能就是要统计帖子的数量,便于分页显示计算总页数。
CREATE TABLE `discuss_post` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '帖子Id,主键',`user_id` varchar(45) DEFAULT NULL COMMENT '贴子所属的用户id,帖子是由谁发表的',`title` varchar(100) DEFAULT NULL COMMENT '帖子标题',`content` text COMMENT '帖子内容',`type` int(11) DEFAULT NULL COMMENT '帖子类型:0-普通; 1-置顶;',`status` int(11) DEFAULT NULL COMMENT '帖子状态:0-正常; 1-精华; 2-删除;',`create_time` timestamp NULL DEFAULT NULL COMMENT '帖子创建时间',`comment_count` int(11) DEFAULT NULL COMMENT '帖子评论数量(回帖、评论、回复)',`score` double DEFAULT NULL COMMENT '帖子分数(根据分数进行热度排行)',PRIMARY KEY (`id`),KEY `index_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=281 DEFAULT CHARSET=utf8;
统计帖子的总行数:
<select id="selectDiscussPostRows" resultType="int">select count(*)from discuss_postwhere status != 2<if test="userId!=0">and user_id = #{userId}</if>
</select>
count(*) MySQL是如何实现的?
对于不同的存储引擎,count(*)的实现方式不一样:
- MyISAM存储引擎将一张表的总行数存储在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高。
- InnoDB存储引擎没有单独记录表的总行数,在执行count(*)的时候是一行一行地从存储引擎里读出来,然后累计计数,效率较低。
为什么InnoDB 不像MyISAM那样,单独把表的总行数存储起来?
这是由于事务造成的,InnoDB是支持事务的,并用MVCC机制实现,这就导致了并不是所有行,当前事务都能观察到。对于还未提交的,或者在当前事务开始之后的事务提交的数据,当前事务都是观察不到的,需要一行一行的做判断,当前行是否对当前事务可见。对于每个事务,表的总行数不是确定的,所以不能单独用一个表将表的总行数存储起来。
举个例子,创建一张表t
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB;
由于表t是新创建的,所以总行数是0。
以下三个事务A、B、C按照表中的顺序执行:
| 时刻 | 事务A | 事务B | 事务C |
|---|---|---|---|
| t1 | begin; select count(*) from t; // 返回 0 | ||
| t2 | insert into t (id, c) values(1,1); | ||
| t3 | begin; | ||
| t4 | insert into t (id, c) values(2,2); | ||
| t5 | select count(*) from t; // 返回 0 | select count(*) from t; // 返回 2 | select count(*) from t; // 返回 1 |
| t6 | commit; |
可以看到,即使是在同一时刻(t5)执行的查询,计算表的总行数,由于MVCC机制,每个事务看到的表的范围不一样,得到的结果也不一样。
这和InnoDB事务设计有关,可重复读是InnoDB默认的隔离级别,在代码上就是通过多版本并发控制,也就是MVCC机制实现的。每一行都有判断自己是否对当前事务可见,因此,对于count(*)请求来说,InnoDB只好把数据一行一行读出来依次判断,可见的行才能用于计算当前事务执行的查询表的总行是。
InnoDB在执行count(*)时做了什么优化?
InnoDB是索引组织表(聚簇索引),主键索引树的叶子节点存放的是数据,而普通索引树上的叶子节点是主键值。所以,普通索引树比主键索引树要小得多。对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的,因此InnoDB会找最小的那棵索引树来进行遍历。保证逻辑结果正确的前提下,尽量减少扫描的数据量,是数据库数据库设计的通用法则之一
为什么不用show table status来查看某张表的总行数?
使用sql命令,查看表t的状态:
show table status like 't'\G
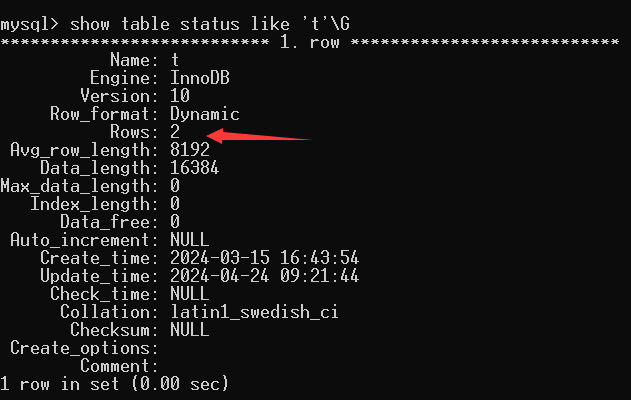
Rows字段记录了表t的行数,虽然这里是准确的,但随着表中的记录增加,Rows的精确度会下降。因为Rows是通过采样估计出来的,所以不精确,MySQL官方给出的误差是40%到50%,所以这个命令也不能用来统计表的行数。
使用Redis缓存,记录数据库表的总行数,可以吗?
使用Redis缓存,记录数据库表的总行数,如果增加一条记录,计数加1,删除一条记录,计数减1。着看起来似乎可以,但是Redis缓存有以下缺点:
- 可能会丢失更新,还未持久化Redis就重启了,刚才计树就丢失。
- 逻辑上是不准确的。
对于第1点,可以在Redis重启时,使用count(*)命令再获取一次表的总行数。由于重启发生的概率很低,count(*)带来的性能问题是可以容忍的。
对于第2点,由于Redis记录表的总行数在逻辑上就是不准确的,这是不能容忍的。举个例子,假设某个页面需要统计数据库中最新100条操作和表的总行数。表的总行数是记录在Redis中的,插入一条数据,Redis计数就加1;删除一条数据,Redis记录就减1。
假设事务A进行了操作,向表插入了一条记录,然后Redis加1;事务B统计数据库中最新100条操作和表的总行数。由于多线程的执行顺序是随机的,如果按照以下执行序列执行:
| 时刻 | 事务A | 事务B |
|---|---|---|
| t1 | 向表中插入一条记录 | |
| t2 | 统计数据库中最新100条操作和表的总行数 | |
| t3 | Redis计数加1 |
对于上表这种执行序列,从事务B中的统计结果会发现,最新的100条操作已经更新了,但是表的总行数没有加1。
| 时刻 | 事务A | 事务B |
|---|---|---|
| t1 | Redis计数加1 | |
| t2 | 统计数据库中最新100条操作和表的总行数 | |
| t3 | 向表中插入一条记录 |
对于上表这种执行序列,从事务B中的统计结果会发现,最表的总行数没有加1了,但最新的100条操作还没有更新。
本文的大纲?

如何使用数据表统计?
使用Redis缓存统计表的总行数,有丢失数据和计数不精确的问题。我们可以将表的总行数记录在数据库中单独的一张数据库表。由于InnoDB支持事务,我们可以利用事务的特性,解决特定执行序列,Redis计数逻辑上不精确的问题。
举个例子,用创建一张新的表C,专门记录原来这种表的总行数。
| 时刻 | 事务A | 事务B |
|---|---|---|
| t1 | begin; 向表中插入一条记录 | |
| t2 | 统计数据库中最新100条操作和表的总行数 | |
| t3 | 表C字段计数加1 commit; |
| 时刻 | 事务A | 事务B |
|---|---|---|
| t1 | begin; 表C字段计数加1 | |
| t2 | 统计数据库中最新100条操作和表的总行数 | |
| t3 | 向表中插入一条记录 commit; |
对于上面两种表的执行序列,由于事务B统计数据库中最新100条操作和表的总行数,由于事务A还没有提交,所以看不到最新的插入记录,也看不到表C字段计数 加1操作,所以,保证了事务B读到的数据逻辑一致性。
MyISAM、InnoDB、show table status、Redis、计数表 统计行数比较?
- MyISAM使用count(*)很快,但是不支持事务。
- show table status命令执行很快,但是不准确。
- InnoDB直接count(*)会扫描全表,虽然结果准确,但会导致性能问题。
- Redis虽然性能高,但是可能会丢失更新,且逻辑上是不正确的。
- 数据库表字段记录总行数,利用事务的特性,解决Redis缓存记录逻辑上不准确的问题。
count(*), count(1), count(id), count(字段)比较?
一、count函数语义:
public boolean count(Object o){return o == null?
}
二、不同的调用方式
| 调用方式 | 语义 | InnoDB引擎实现方式 | SQL是否进行了优化 |
|---|---|---|---|
| count(*) | 返回满足条件的结果集的总行数 | 按行累加 | 是 |
| count(1) | 返回满足条件的结果集的总行数 | 遍历整张表,但不取值。server层对于返回的每一行,将1作为实参,调用count函数。该判断不可逆为空的,按行累加。 | 否 |
| count(id) | 返回满足条件的结果集的总行数 | 遍历整张表,把每一行的id取值取出来,返回给server层。server层拿到id值之后作为实参,调用count函数。该判断是不可能为空的,按行累加。 | 否 |
| count(字段) | 返回满足条件的数据行里面,参数“字段”不为NULL的总个数 | 遍历整张表,把每一行字段值取出来,返回给server层。server层拿到字段值之后作为实参,调用count函数。如果字段不为NULL,按行累加;如果字段为NULL,不加1。 | 否 |
这篇关于MySQL统计一个表的行数,使用count(1), count(字段), 还是count(*)?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





