本文主要是介绍Linux系统-服务器硬件及RAID配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.服务器
1.服务器与普通计算机的区别
2.功能
3.分类(按照产品形态分)
4.架构(按照指令集类型)
5.相关指令
5.1.查看服务器CPU的信息
5.2.查看服务器内存的信息
二.RAID磁盘阵列(Redundant Array of Independent Disks)
1.介绍
2.常用RAID级别
2.1.RAID 0(条带化存储)
2.2.RAID 1(镜像存储)
2.3.RAID 5(大众模式)
2.4.RAID 6(金融类、科研类)
2.5.RAID 1+0(先做镜像,再做条带)
2.6.RAID 0+1(先做条带,再做镜像)
3.总结
一.服务器
服务器(Server),是指在网络上提供各种服务的高性能计算机
1.服务器与普通计算机的区别
- 通信方式为一对多
- 资源通过网络共享
- 硬件性能更加强大
2.功能
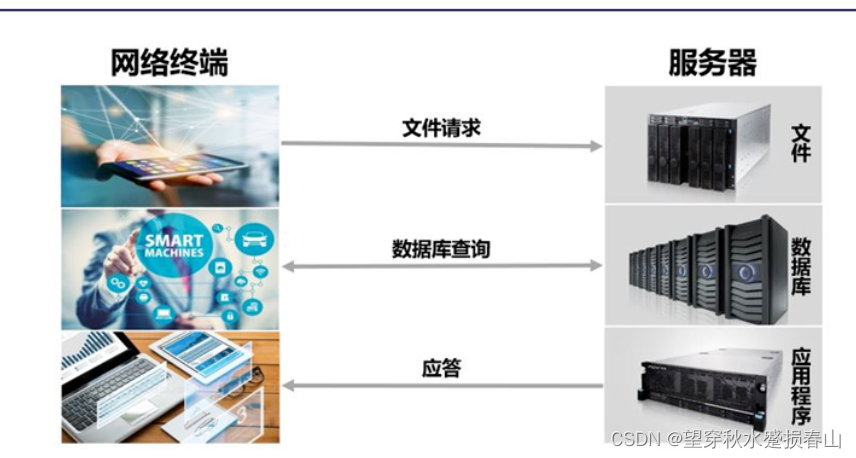
3.分类(按照产品形态分)
机架式(居多):占用空间小,便于统一管理,适用于对服务器需求量较大的大型企业
塔式:个头大,独立性强,协同工作在空间占用和系统管理上不方便,适合小型企业使用
刀片式: 应用于大型数据中心或者需要大规模计算的领域,如银行、电信、金融行业以及互联网
数据中心等
机柜式:未来数据中心基础架构的核心形态,是数据中心架构的发展趋势
4.架构(按照指令集类型)
X86(市占率高):高主频、高功耗,覆盖高性能和通用计算场景
ARM(潜力很大):众核架构,适合高并发、高带宽的计算场景
5.相关指令
5.1.查看服务器CPU的信息
cat /proc/cpuinfo
lscpu
model name(CPU型号)
physical id(物理CPU的ID)
cpu cores(每个物理CPU中的核心数)
processor (逻辑CPU的ID)
5.2.查看服务器内存的信息
cat /proc/meminfo
free [-m]
二.RAID磁盘阵列(Redundant Array of Independent Disks)
1.介绍
- RAID是同一个硬盘同一个分区或者不同硬盘的不同分区组成的逻辑上的硬盘。
- RAIN核心就是冗余(高可用)其中冗余概念就是坏了一块盘不影响使用
- RAID可以提高读写性能。
- RAID是有级别的,不同级别提供的性能和配置,需求的磁盘数都不一样
2.常用RAID级别
2.1.RAID 0(条带化存储)
- 条带化存储把数据分散在一个或者多个物理磁盘,并行读取与写入,可以使用一块或多块硬盘
- 数据传输率高,没有数据冗余
- 坏一块盘,就无法使用,无法为数据的可靠性提供保证
- 适用于视频,大文件图片,适用于读写性能要求较高的场景,不能应用于数据安全性要求高的场合
- 磁盘利用率:N

2.2.RAID 1(镜像存储)
- 通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据
- 当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能
- RAID 1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。
- 当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据
- 磁盘利用率:N/2

2.3.RAID 5(大众模式)
- N(N≥3)快盘组成阵列,一份数据产生N-1个条带,同时还有1份校验数据,共N份数据在N块盘上循环均衡存储
- N块盘同时读写,读性能很高,但由于校验机制的问题(多写一份纠删码数据),写性能不高
- 可靠性高,允许坏1快盘,不影响所有数据
- 一般企业都是采用RAID5,使用的硬盘数最少要3块
- 磁盘利用率:(N-1)/ N

2.4.RAID 6(金融类、科研类)
- N(N≥4)块盘组成阵列
- 与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息快
- 两个独立的奇偶系统使用不同的算法,即是两块磁盘同时失效也不户影响数据的使用
- 想对于RAID 5有更大的“亏损失”(多写两份纠删码数据),因此写性能更差
- 磁盘利用率公式:(N-2)/ N

2.5.RAID 1+0(先做镜像,再做条带)
- N(偶数,N≥4)块盘两两镜像,在组合成一个RAID 0
- N/2块盘同时写入,N块盘同时读取
- 性能高,可靠性高,读写都快
- 磁盘利用率:N/2

2.6.RAID 0+1(先做条带,再做镜像)
- 读写性能与RAID 10相同
- 安全性低于RAID 10

3.总结
| RAID 0 | RAID 1 | RAID 5 | RAID 6 | RAID 1+0 | |
| 磁盘数量要求 | N | 偶数 | ≥3 | ≥4 | ≥4且偶数 |
| 读写性能 | 读写速度快 | 读快;写不变 | 读快;写慢一点 | 读快;写更慢一点 | 同时具备RAID0和RAID1的性能,读写都快 |
| 利用率 | N | N/2 | (N-1)/N | (N-2)/N | N/2 |
| 有无冗余能力 | 无 | 有,允许一个硬盘故障 | 有,允许一个硬盘故障 | 有,允许两个硬盘故障 | 有,允许不同RAID1组中各坏一个硬盘 |
这篇关于Linux系统-服务器硬件及RAID配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







