本文主要是介绍【磁盘根目录扩容】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目的
给磁盘的根目录扩容,每个人在服务器上在根目录操作的可能性更大,如果单独指定一个目录扩容,很有可能使用不当
步骤
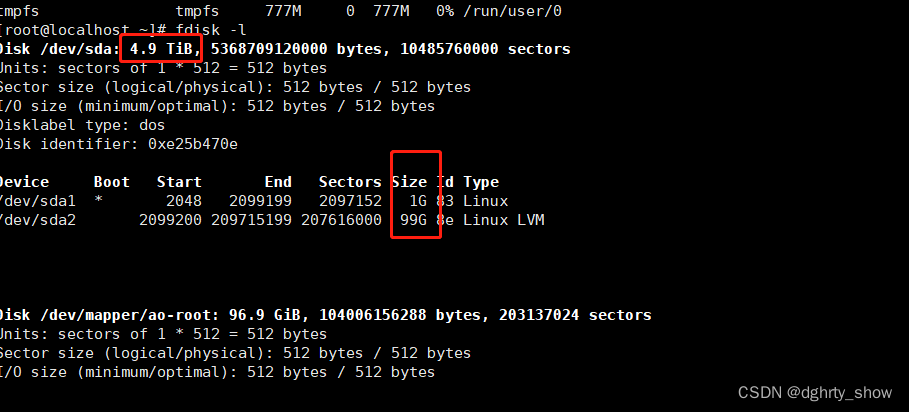
未扩容时,查看到sda下有两个分区,目前要扩展追加一个分区
使用fdisk -l
查看到sda有4.9T,但是sda1和sda2加起来才100G,所以需要扩容
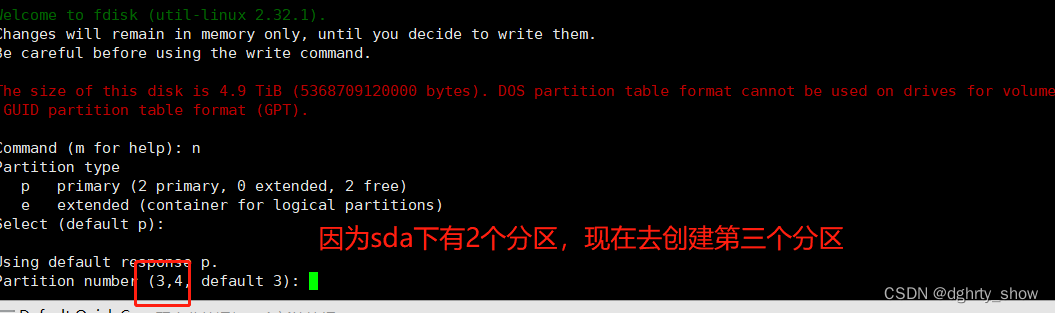
#fdisk命令对硬盘sda进行分区编辑
fdisk /dev/sda
#输入n就是new一个分区
n
#p就是默认的
p
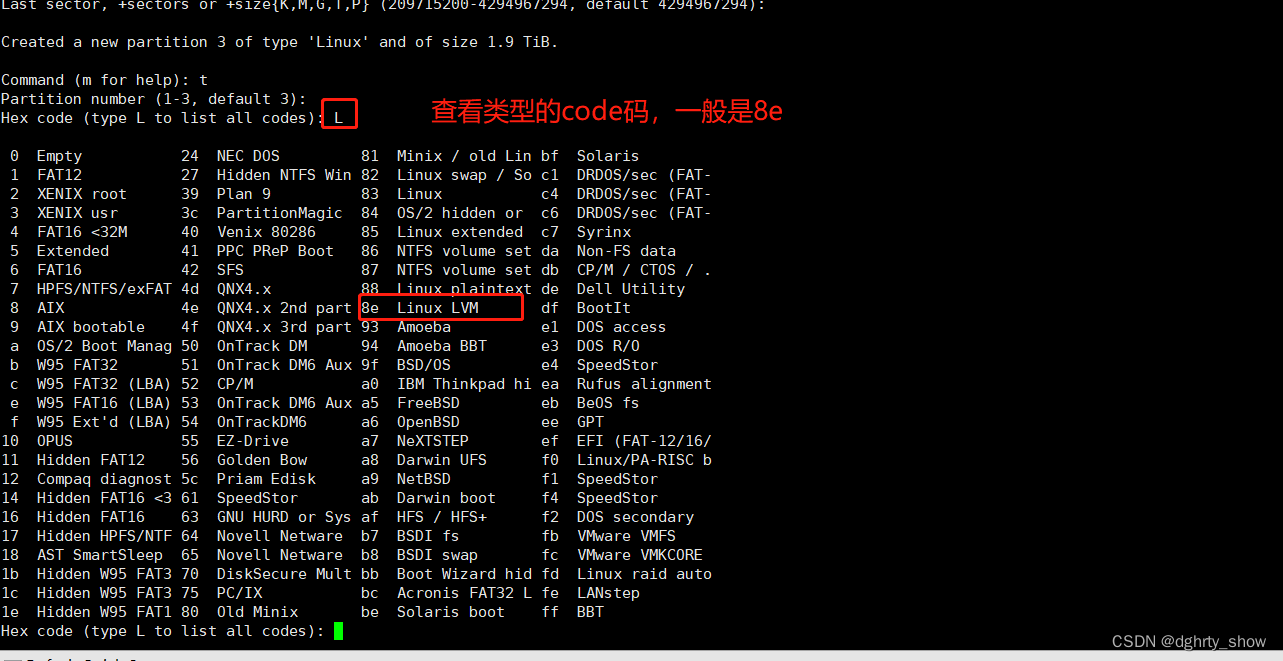
#给分区创建type
t
#l查看分区的类型
L
#分区的类型
Linux LVM(8e)
#写入并退出
w
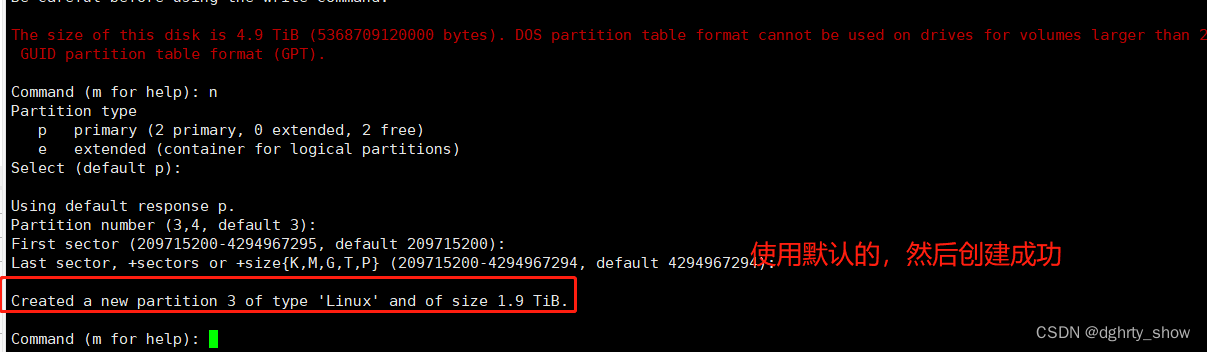
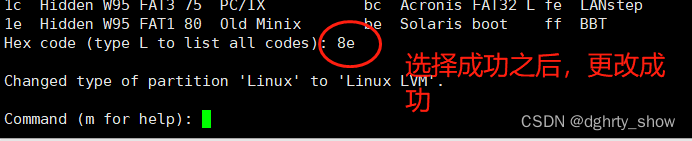
创建分区成功
#再次查看就能看到新增的分区,并看到分区的类型
fdisk -l
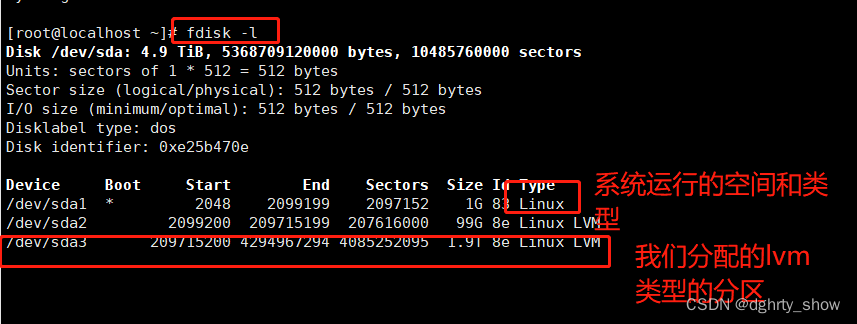
创建物理卷
#我们需要把磁盘新分区初始化为物理卷
pvcreate /dev/sda3
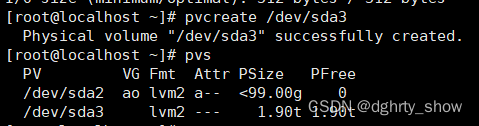
##查看物理卷,创建成功
pvdisplay===pvs
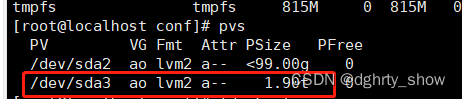
卷组查看以及扩展
##查看卷组,重点关注卷组的名字,VG列,这里是根据名字去扩展
vgdisplay==vgs
#根据名字去扩展,比如这里是根据ao,按照实际的结果扩展
vgextend ao /dev/sda3
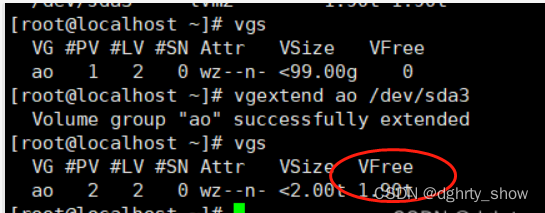
#实际还要使用剩余空间100%全部扩容:
lvextend -l +100%FREE /dev/ao/root
#查看逻辑卷,把free的全部加进来了
lvs
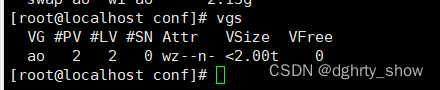
#重读分区表
partprobe
#查看文件系统的类型,type列
df -hT
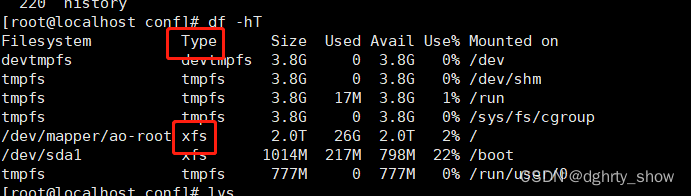
#根据不同文件系统类型挂载,,
xfs的使用:
xfs_growfs /dev/mapper/ao-root

如果是ext3/4
:resize2fs dev/mapper/ao-root
这篇关于【磁盘根目录扩容】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








